


Introduction
Last blog we are success of record sound clip to FRAM in the Cypress Kits, here we could like upload to AWS to future process, such as used for sound recognition or feed to AI engine.
In order to stream the sound data to the AWS cloud, the trandition way is use the UDP or Http streaming. By without use of additional sockets, we use MQTT publish to AWS and save in S3 storage, esspecally many iOT device only transfer way. The MQTT channel is good and design for small continues data such as machine status or sensor, it also able to transfer other object as using some technique.
Setup of AWS IoT Core
In order re-route received data to AWS Storage (or other application), we added a "Rules"
Rules
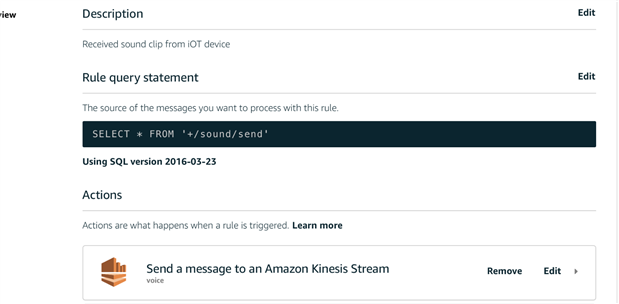
Under Act > Rules, Click Create
Name: Voice
Rule query is:
SELECT * FROM '+/sound/send
which the rules received topic [anyname]/sound/send, as we designed use topic "ThingsName"/sound/send to received the data.
Select "Add action", select "Send a message to an Amazon Kinesis Stream"
(not Kinesis Firehose, we first choose Kinesis Firehose stream which is much easy for storage but not good, we will mention later. )

Stream Name: voice
Partition key: ${Topic()}
Create IAM Role and use new one.
Inside of Things Policy document
Added
"arn:aws:iot:us-west-2:161xxxxxxx:topic/${iot:Connection.Thing.ThingName}/sound/*",
"arn:aws:iot:us-west-2:161xxxxxxx:topic/$aws/rules/Voice/*"under Action iot:Publish
The second line for we prepare use of Basic Ingest, which reduce our Messaging Costs, ref:
https://docs.aws.amazon.com/iot/latest/developerguide/iot-basic-ingest.html
S3
Other platform may more efficiency, however, for simplify, we choose S3 instead of other advanced database or storage platform.
Open Amazon S3, Simple Added a new Buckets "voicecognise"

Not public is fine, we save/retrieve though private channel.
Amazon Kinesis
Amazon Kinesis provide Data Streams and Data Firehose, depending on usage, either is suitable for continue receiving machine data, which is the "Streams", however Amazon Kinesis Streams
provide more flexible solution as Firehose is simple solution for storage under several popular storage such as S3 and Redshift.
Following Amazon instruction you can easy to build up the Kinesis Firehouse:
https://docs.aws.amazon.com/firehose/latest/dev/writing-with-iot.html
If you choose stream to S3 default, the data will separate under Date, the default is good for storage/backup iOT machine status such as temperature, as no programming require, the default setting is well for most case.
However in our case, the result is not good, this is because:
1. The minimum buffer time is 60s, so the data will not observed until the cache writing, which is Firehose system control.
2. It simple glue up the data by received time, which every message arrived time is not some, which our sound data is sequence is destroy.
(It not problem for most iOT case which transfer by json with timestamp)
3. We have two position can be process data by Lamba under firehose, first is data incoming, sorry about that the firehose accept BASE64 which not suitable for use reconstruction PCM data,
another is after S3 file builded by firehose, as this stage all data glue is not good for repacking.
So we use the Kinesis Data Streams instead of Data Firehose as main reason it have faster response so our Lamba function to process the incoming data within seconds after received.

Data stream name: voice
Number of open shards: 1
The IoT Hardware Mbed Code
Our awsiot cycle will continue monitoring and stream (publish batch of MQTT message) to AWS IoT
/*Loop for send MQTT message, sample dismiss last if size not alignment */
while(sound_stream(sound_buffer)>=SOUND_STREAM_BUFFER_SIZE){
/* time stamp */
time_t current_time = time(NULL);
if(current_time==last_time)
++count;
else{
last_time = current_time;
count=0;
}
current_time = current_time*1000+count;
time_t now = current_time;
/* write time_t to last 8 char */
for(int i=buffer_size*2-1;i>buffer_size*2-9;i--){
((char*)sound_buffer)[i]= current_time & 0xff;
current_time >>= 8;
}
/* len of after process BASE64 */
size_t len = 0;
int result = mbedtls_base64_encode((unsigned char*)base64buffer,base64buffer_size,&len,(const unsigned char*)sound_buffer,buffer_size*2);
if (result == MBEDTLS_ERR_BASE64_BUFFER_TOO_SMALL){
APP_INFO(( "BASE64 Error %d\r\n",len ));
}
/* publish the stream*/
awsiot_publish_stream(base64buffer,rules,len);
APP_INFO(("%" PRId64 "\n",now ));
wait_us(50*1000);
}
The brief jobs of above code is:
1. enquire num of sound data require send to AWS
2. read data from FRAM to buffer
3. added timestamp at the end of data
4. encode data to BASE64
5. publish the data to AWS
6. read next lot and wait 50ms for another publish
Every MQTT publish content 1.5k sound data, for 12s data we require 256 MQTT message, which mostly can finish the upload under 5 seconds.
AWS Lambda function
We build a custom function which is python to receive the stream and save to S3 storage
Under AWS Lambda, Create new Functions, name voice_consumption

Select Python 3.8 and Create a new role with basic Lamba permissions
Open the created functio, select Permissions > Execution role, click the Role name and open IAM
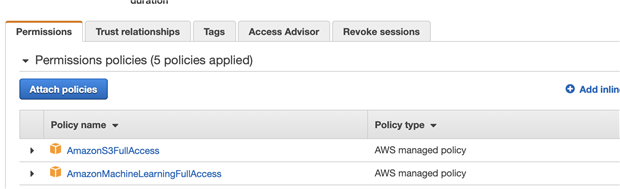
Attach policies AmazonS3FullAccess
Under Lambda, Configuration, Open Designer
Click + Add trigger
Select "Kinesis"
Kinesis stream > voice
Other leave default.
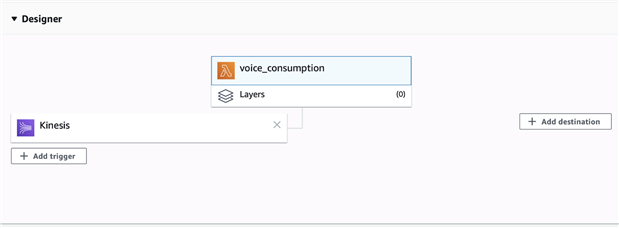
Here is the Lamba working for task.
import base64
import boto3
from datetime import datetime
import time
import pickle
# Temp int64 array used for indexing
# Timestamp is device MQTT sending time ms, not sound record time
# first - start time stamp
# ..... - seq of timestamp
# last - last time stamp
#
TEMP_S3_INDEX = "income/sound_temp_index.tmp"
TEMP_S3_LAST_SOUND_KEY = "income/sound_temp_last_key.tmp"
NEXT_FILE_SECOND = 2
BATCH_SIZE = 6
RECORD_SIZE = BATCH_SIZE * 256
SAMPLE_SIZE = RECORD_SIZE + 8;
s3_client = boto3.client('s3')
s3 = boto3.resource('s3')
def lambda_handler(event, context):
soundclip = bytearray()
key = ''
soundclip_index = []
soundclip_obj:s3.Object
s3soundlast_sound_key_obj:s3.Object
s3soundclip_index_obj:s3.Object
try:
s3soundlast_sound_key_obj = s3.Object('voicerecognise',TEMP_S3_LAST_SOUND_KEY)
s3soundlast_sound_key = s3soundlast_sound_key_obj.get()['Body'].read()
key = pickle.loads(s3soundlast_sound_key)
soundclip_obj = s3.Object('voicerecognise',key)
soundclip = bytearray(soundclip_obj.get()['Body'].read())
print ("num of record",len(soundclip)/RECORD_SIZE)
except s3_client.exceptions.NoSuchKey as e:
print ("no previous temp soundclip found")
try:
s3soundclip_index_obj = s3.Object('voicerecognise',TEMP_S3_INDEX)
s3soundclip_index = s3soundclip_index_obj.get()['Body'].read()
soundclip_index = pickle.loads (s3soundclip_index)
except s3_client.exceptions.NoSuchKey as e:
print ("no previous index found")
for record in event['Records']:
#Kinesis data is base64 encoded so decode here
payload=base64.b64decode(record["kinesis"]["data"])
#Another decord for MQTT
payload=base64.b64decode(payload)
recordsize = len(payload);
#Check sample size match
if recordsize != SAMPLE_SIZE:
print( "recordsize mismatch %d %d",recordsize,SAMPLE_SIZE)
break
# timestamp ms decorded from back of payload
stamp = int.from_bytes(payload[SAMPLE_SIZE-8:], byteorder='big',signed='true')
print( "Decoded time",stamp,"size:",len(payload)," payload: " + str(payload))
# if the timestamp more that 2.5s the last index, simple build new file
if len(soundclip_index)>0:
last = soundclip_index[len(soundclip_index)-1]
if stamp - last > 2500:
key = ''
soundclip_index.clear()
soundclip = bytearray()
timestamp = datetime.fromtimestamp(stamp/1000)
# if index empty, append data
if len(soundclip_index) == 0:
soundclip_index.append(stamp)
soundclip+=payload
continue
# from back seek the pos and insert to soundclip and update index
for i in range(len(soundclip_index)-1, -1, -1):
if soundclip_index[i] > stamp:
continue
# insert sound data on soundclip
soundclip[(i+1)*RECORD_SIZE:(i+1)*RECORD_SIZE] = payload[0:RECORD_SIZE]
# insert timestamp in index
soundclip_index.insert(i+1,stamp)
break
print("Decoded soundclip: " + str(soundclip))
if len(soundclip_index) == 0 :
return
if key=='' :
key = datetime.fromtimestamp(soundclip_index[0]/1000).strftime("income/sound %m%d%Y-%H%M%S")
s3soundlast_sound_key_obj.put(Body=pickle.dumps(key))
soundclip_obj = s3.Object('voicerecognise',key)
s3soundclip_index_obj.put(Body=pickle.dumps(soundclip_index))
soundclip_obj.put(Body=soundclip)
The Kinesis Stream will trigger this function after stream arrived
The brief of the function is:
1. A temp list storage sound clip timestamp
2. A temp string storage writing file
3 Decord the data from BASE64 to raw (working for twice because AWS kinesis will also encode another BASE64)
4. Retrive the timestamp from last 8 bytes payload.
5. seek the position and insert the sound data to correct sequence
6. Create another file if no sound data more that 2.5 second
7. Save data to S3 Storage

Conclusion
MQTT is lightweight protocol based on publish/subscribe is good for IoT, small alive overhead and low power require.
The MQTT not just can send text such as sensor or json data, by careful implement it can transfer other type of data such as firmware, pictures or as this case the sound clips, we can update the device Logo such as latest Company Logo or just update the help file without implement other protocols.
The AWS Alexa Voice Server also use of MQTT for sound transfer.
As Greengrass let the device process locally, in our challenge, target build Intelligent Mailbox for consumer, which good for simple serverless application with direct contact to AWS Cloud and process data under Cloud.
The AWS IoT advantage is fully integrated with many AWS tools to help IoT more possible, such as we can very easy to implement sensor logging and backup to S3 or DynamoDB or compute custom code though Lambda seamless.