


We would like to start off the proceedings by thanking Element14 and Arduino for giving us an opportunity to build a project that can impact a massive segment of the population. We hope that it will benefit a lot of people who need something like this and we pledge our full devotion towards this endeavour.
This is the first blog post so I would like to introduce everyone to our product design and plan of action. AUDIO4VISION is a project for the visually impaired, be it those who are completely blind, partially blind or even colour blind. The primary function of the product is image description in audible form which can be heard through a speaker or headset. Using this a person can move around and take pictures of their surroundings to get decently detailed captions describing what is happening in the image. We are planning to add several features once the prototype is ready and fully functioning.
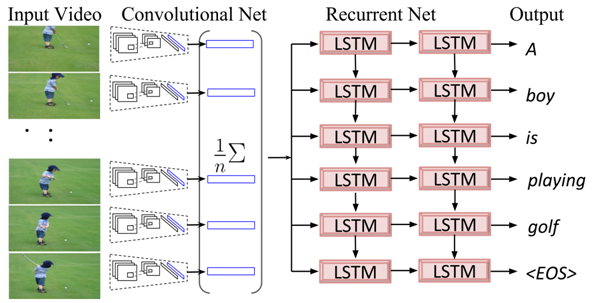
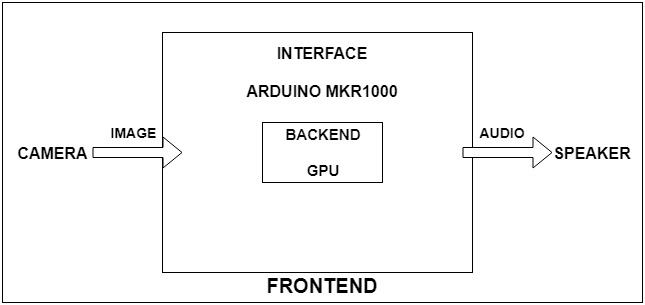
There are three layers of functionality in our project -
- Front End We will incorporate OV7670 ArduCam for caption generation HC-SR04 to detect the distance of an object ADXL335Z to detect acceleration EKMC1601111EKMC1601111 PIR sensor to detect the change in surrounding objects There will be an additional speaker to give audio output as given by Arduino MKR1000 after processing is completed in the cloud instance
- Middle Interface - Arduino MKR1000 is the primary board used for the interface for exchange of information between the two ends. The various sensors will relay the information to MKR1000 and from there it will transmit the information to a cloud server which may be Microsoft Azure or AWS
- Back End - The backend will consist of a cloud instance as specified earlier, and it will be running a deep learning model consisting of a Convolution Neural Network and a Recurrent Neural Network. The exact model and hyperparameters will be researched and discussed in the following blog posts. The output from the cloud will be a sentence in English (as shown in the image above) which will be passed onto Arduino MKR1000 to be converted into Audio
The major chunk of research required is for the deep learning model, which will be deployed on the cloud instance. The datasets for image captioning are quite huge and unless we can find a good enough pre-trained model, we will have to train a model ourselves on a GPU. We have already started trying out various image classification models and will be discussing about them in the blog posts to come. We will also start interfacing the ArduCam with the MKR1000 as soon as the kit arrives. We are also considering various cloud services for connecting with the MKR1000 and will be posting about the same very soon. We hope to complete this project within time so we can add additional features to help the visually impaired in more ways than just image captioning.
Thank you for reading the post, the next one is coming up very soon!
