


Welcome to our 10th blog post! In this blog, we'll be talking about a python library, called TTS (Text-to-Speech).
Image captioning is all good and great until we realize that a caption is just a string - it still requires eyes to be read! A visually handicapped person won't find any information in such data as he won't be able to see it in the first place. Clearly, we need to convert the mode of communication from ocular to auditory - and this is where the TTS library comes in.
TTS or Text-to-Speech or Speech Synthesis is basically an artificial imitation of the human speech. A TTS system takes a string as input and gives the audio file of a "person" speaking that string out loud as output. This is ideal for our use case.
We use this library to implement TTS in our system. The idea is to send an image from the MKR to a server, have that server evaluate a caption for it, feed said caption to a TTS service, and send the resultant audio file back to the MKR.
We test out the library:
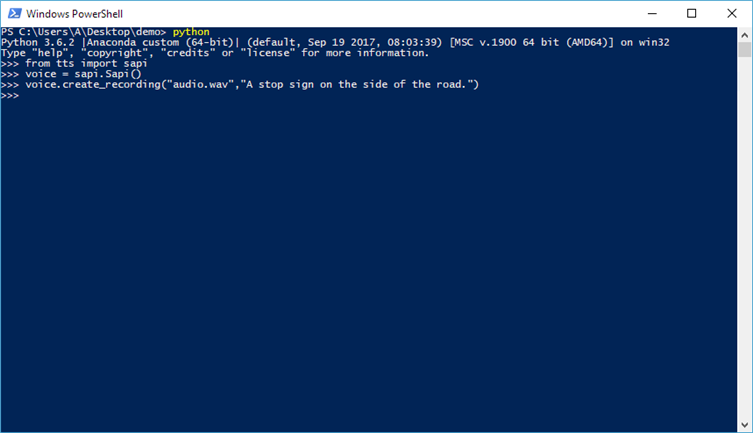
A file named audio.wav is created in the demo folder:
Here is the audio:
Now, let's test it on an actual image, using our Flask server:

The audio file generated for this image is:
https://drive.google.com/open?id=1b6MKq6OV-XX62gxyC8_mCgLAVcJAE5Zu
This audio file will then be sent to the MKR via a GET request and played using the speaker mentioned in the previous blog.
That's it for this blog, which was more on the server side. The next one would be more Arduino-oriented, and we would be talking about the primary functions and POST/GET requests from the Arduino side.
Thanks for reading this blog, the next one is right around the corner!