


I've selected the Buzz3 Audio Dataset to test model development and deployment to the Nicla Vision board using the Edge Impulse toolset. I discussed this dataset in my previous post - Bee Healthy - Blog 4: Audio Dataset.
The Buzz3 dataset contains 11746 2sec samples split as follows:
| train | |||
| class | hour | min | samples |
| bee | 1 | 36 | 2880 |
| cricket | 2 | 0 | 3600 |
| noise | 1 | 24 | 2520 |
| test | |||
| class | min | sec | samples |
| bee | 35 | 42 | 1071 |
| cricket | 19 | 14 | 577 |
| noise | 36 | 36 | 1098 |
I may end up rebalancing the training data, but I'll try it out first. I already have an Edge Impulse account , so I just needed to create a new project that I named Bee_Present:
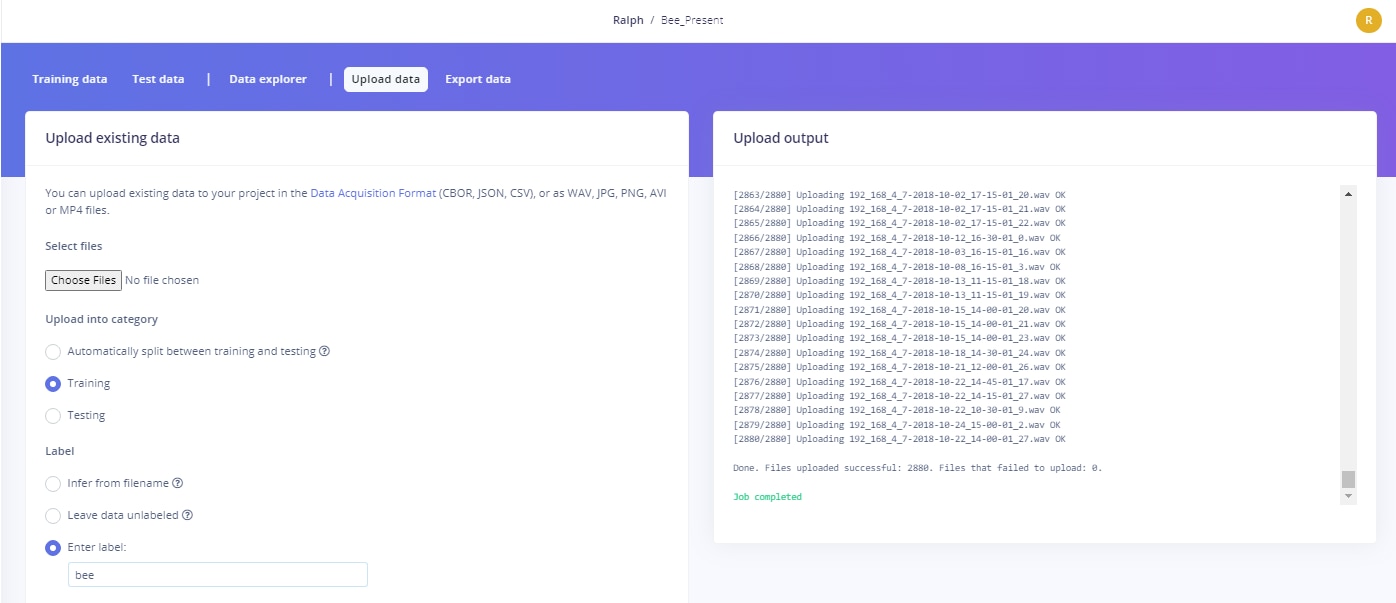
A great feature of the Edge Impulse Studio is the ability to upload existing data files provided they are in an accepted data format or file type.
Data Acquisition Formats:
- CBOR
- JSON
- CSV
File Types:
- WAV
- JPG
- PNG
- AVI
- MP4
The audio files in this dataset are all WAV files, so uploading the files with the appropriate labels was easy.
Data Acquisition
Impulse Design
For non-voice audio data it is generally recommended to use a Spectrogram Processing block - either linear or MFE (Mel-filterbank energy). The MFE is designed to match human audio perception. One might expect MFE to perform better because the data was labeled by human listeners.
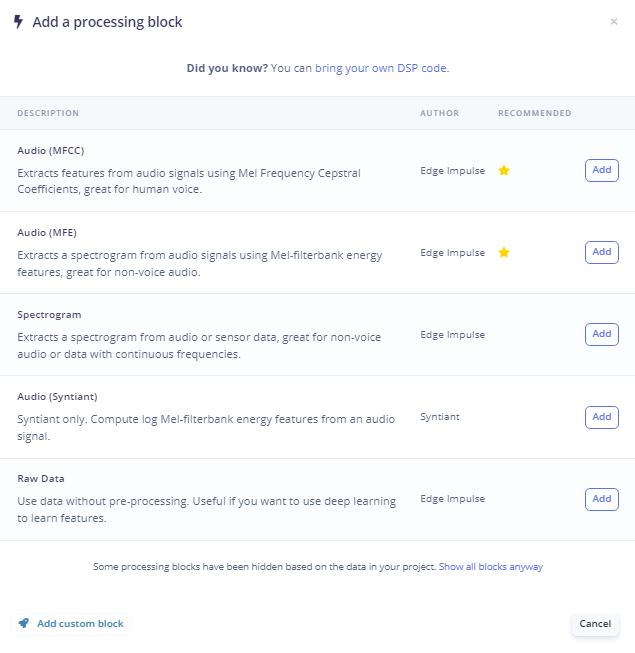
I decided to try it both ways.
Audio (MFE) Impulse
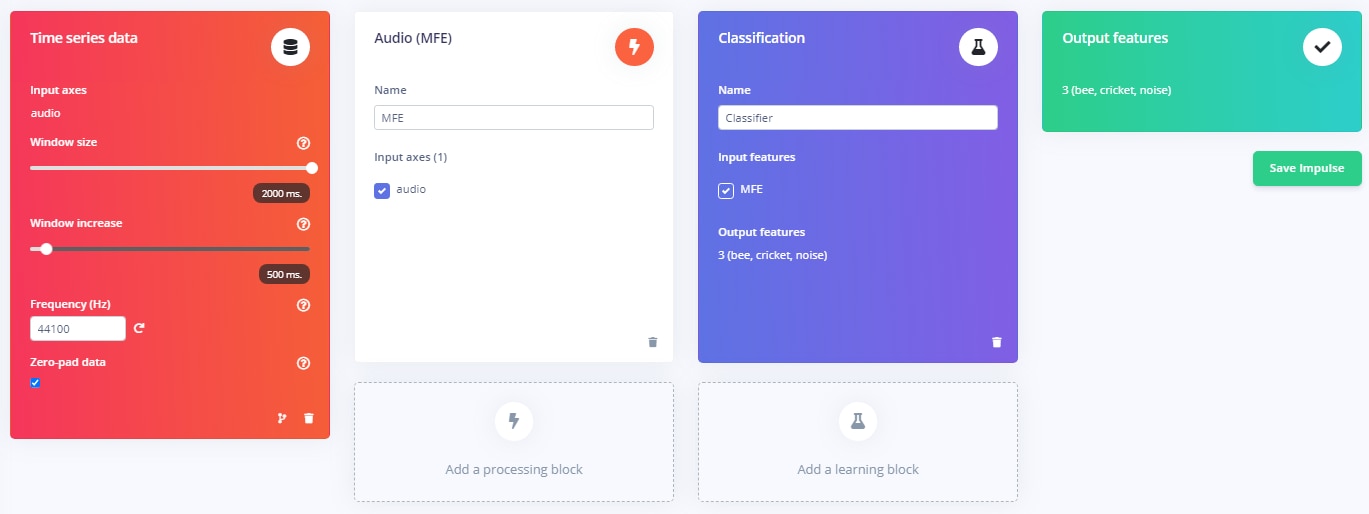
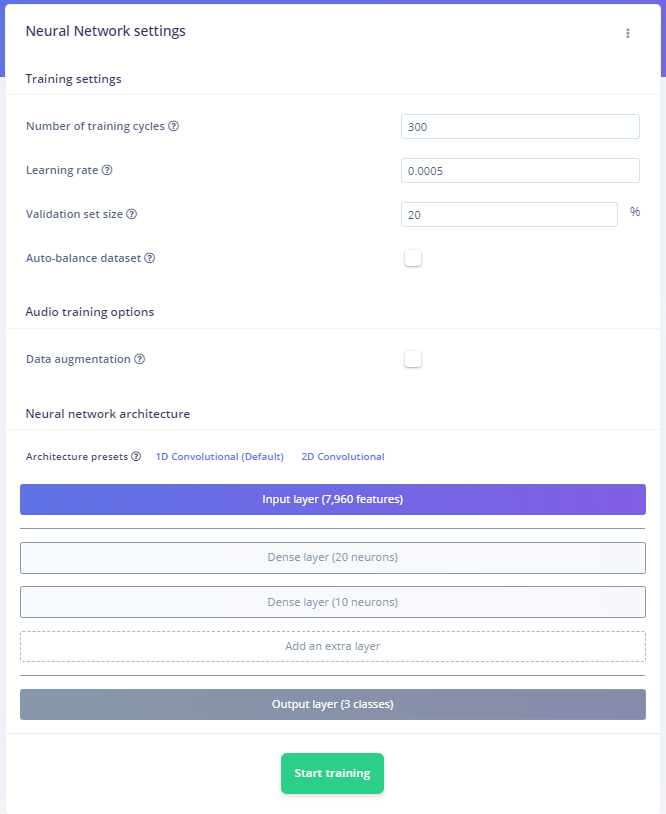
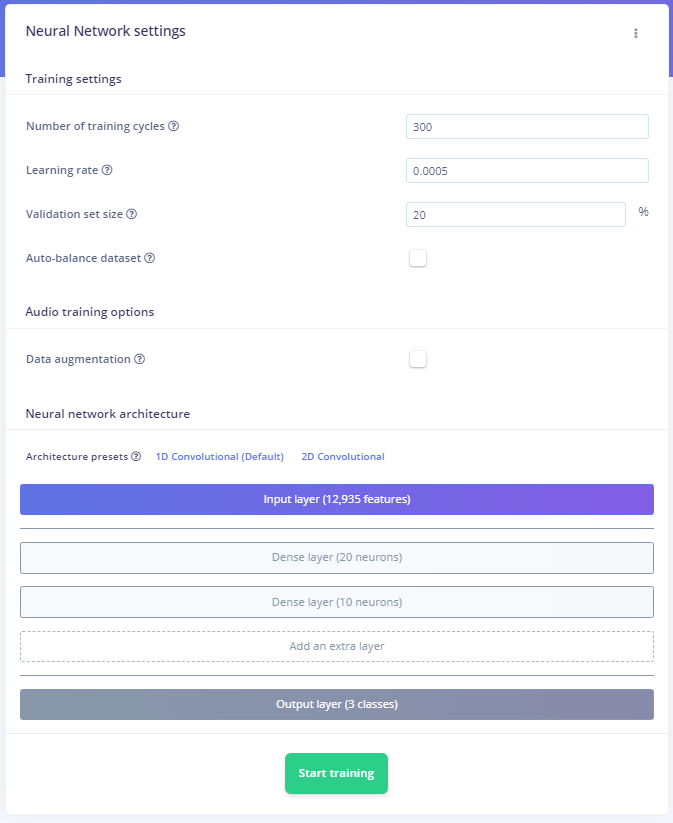
Train the Neural Network:
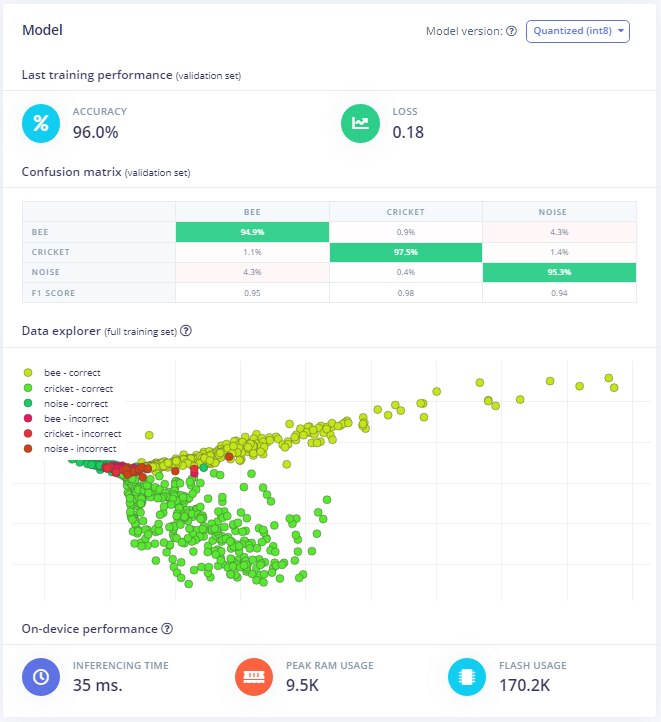
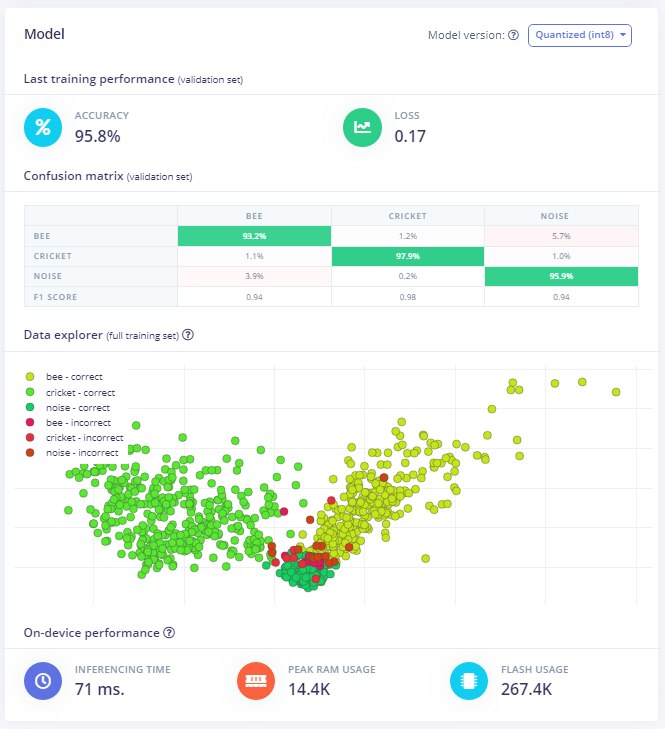
The Quantized (int8) model accuracy is reasonable when validated against the training data:
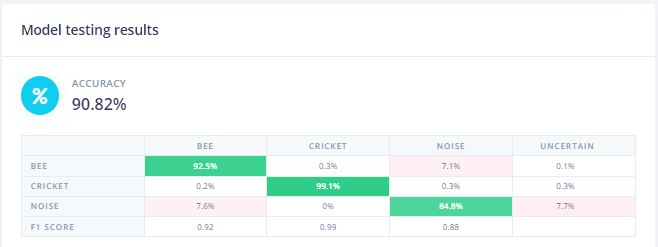
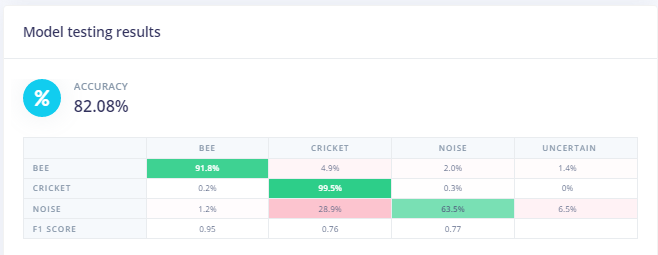
But performs less well against the test data as would be expected:
Linear Spectrogram Impulse
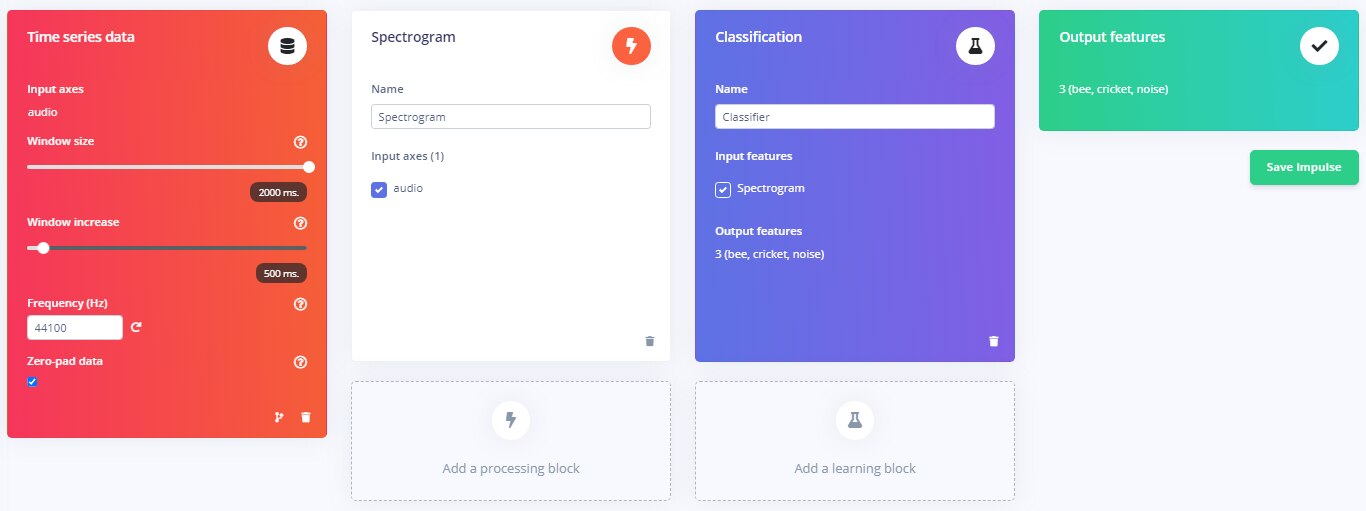
Train the Neural Network:
Again, reasonable accuracy with the training data
But worse performance against the test data
Summary of Project versions:

The inference time of the Mel Spectrogram Impulse (35ms) is half of the Linear Spectrogram Impulse (71ms). And it also has better memory efficiency and accuracy (with this dataset), so that's the model that I will use.
My first test when I get the Nicla Vision hardware will be to use the microphone to verify that I can do "Live classification" before I try to deploy the model.


