



Now that we have our "real" bee and hornet ready for showtime, I had to rebuild the Edge Impulse model from scratch using pictures of the new characters.
The cast is ready for action!
Behind the scenes on the set:


I took about 50 images each of the bee and hornet in various positions on our tree of blossoms. I also took about 20 pictures of just the blossomy tree to use as background.
I just read that the recommendation is to have at least 1500 images with at least 10,000 labelled objects! Yikes! I'll be here all year! I'll be here all year anyway, but I'll be doing more fun stuff than labelling bees and hornets 
While creating the model in Edge Impulse though, it does mention that the chosen base model is quite good with small datasets, so that gives me hope.
Then I had to go through and draw little boxes around every bee and every hornet in all the pictures. Thankfully Edge Impulse seems to have added a feature that helps detect the same object in the next picture as you go through, so it was mostly a process of tweaking the boundaries.

After all of that I ran the training, and the results were a little disappointing - it was ok for the murder hornet detection, but nearly 3/4 of the bee pictures in the test set were classified as background.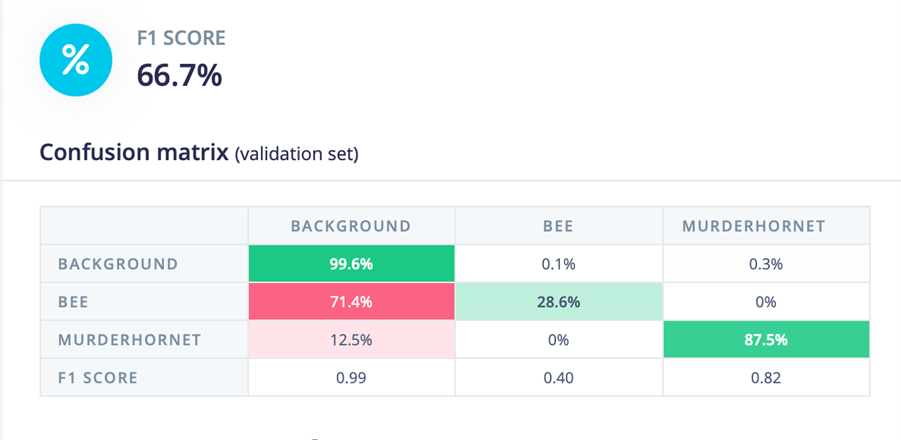
This made me wonder if, while drawing the bounding boxes, it's best to focus on the main features of the bee and hornet, rather than the whole thing - ie, the antenna and wings might not be unique enough, and the big stripey body and the face details might be all that is needed to get a good result.
So I tried again - adjusting most of the bounding boxes on the bee images to reduce the amount of background blossomy bits and focus just on the main features. It's a bit more tedious, as I couldn't find a way to return all the images back to the queue, and had to go one by one.



That helped a lot for the bees, but now the hornets were not identified as successfully.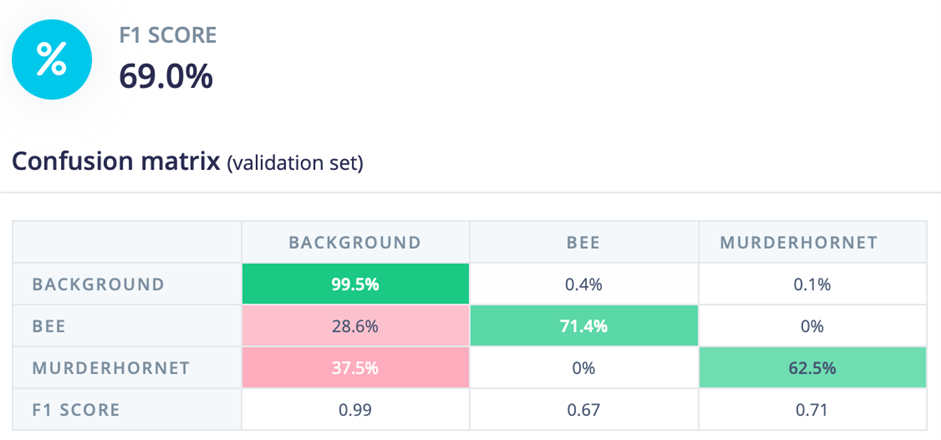
Adjusting the hornet picture bounding boxes and re-training the model gave a more balanced result. Less accurate for bees, but more accurate for the hornets. I guess the hornet detection part is the most important bit, so we'll leave it like this.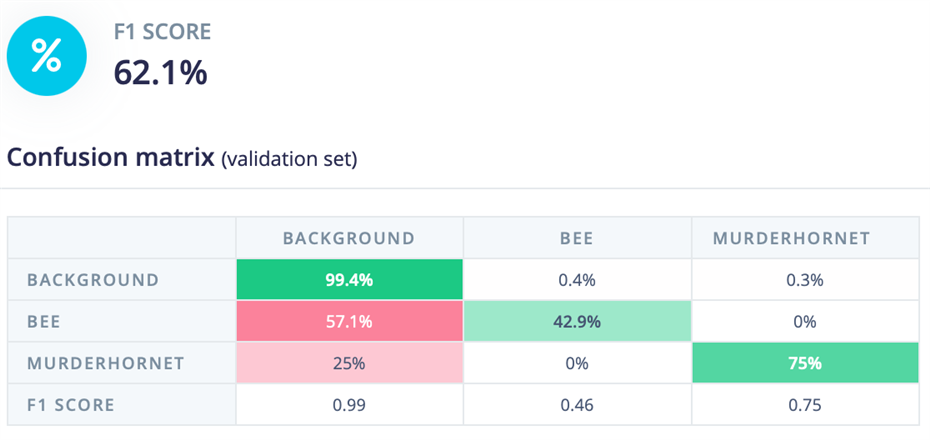
At this point I also realized I didn't take any pictures of just the bee and just the hornet, without the blossomy tree, for the training data set. That might help increase accuracy. It's also possible that the 10% of pictures used for testing are not that representative of what the bee and the hornet really look like. It's only 5 testing pictures each, afterall.
So I built the firmware and uploaded it to the Nicla Vision, and tested it out.
Pointing it just at the bee and then at the hornet gave good results.
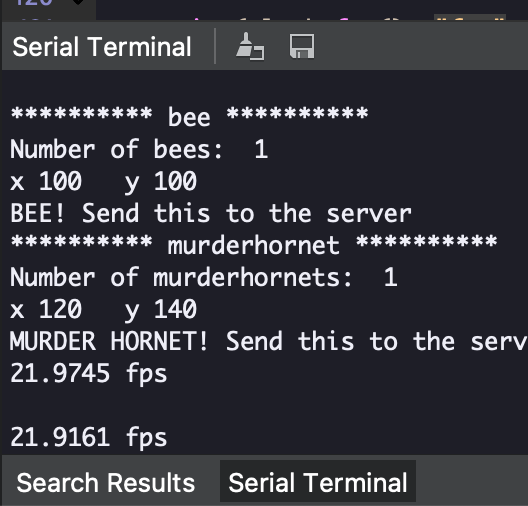
It also saved the image of the hornet on the Nicla Vision drive! I had forgotten about this feature until I opened up the drive to update the script.
It shows a small issue - the murder hornet is being identified as both a hornet in one place and a bee in another place. But the main purpose is being served - we've identified a murder hornet in the area that poses a danger. Yay!
It's possible that the faces of the stunt bee and hornet are too similar to differentiate them fully. This is where having 10,000 objects might make it more accurate! 

I think this means we are ready to do a "field test". I copied my own script to the Nicla Vision drive, and renamed it to be "main.py", so that it will be the script that runs when the board starts up.
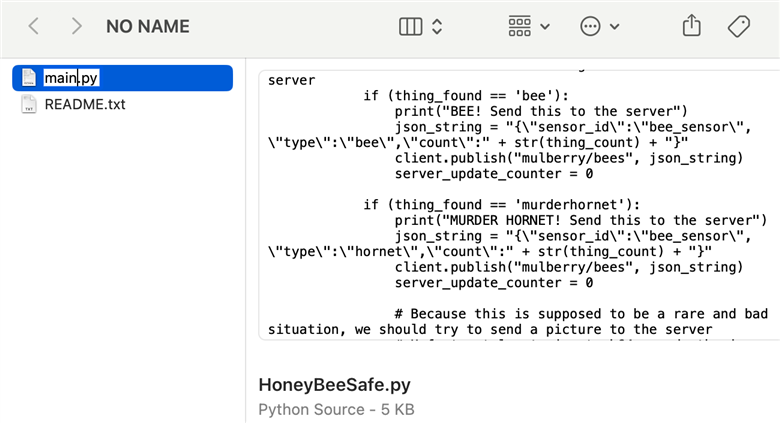
Now we just need to plug in the board anywhere, without needing a connection to my computer and OpenMV, and it should run independently to detect our stunt bee and hornet and report it to the server, which will then report it to us via the web UI.
I'll leave that for another day and another blog post, as I'll need some help from the resident artist here to take video of the process 