



In my previous blog I illustrated the OCR result for any display that contains seven segment display like multimeter, digital weight scale, blood pressure meter. I foud that tesseract OCR engine is not good enough for reading seven segment display. Maybe customized training can improve the result (I will try later if time permits). After getting the frustrating result from tesseract I was looking for another alternate OCR engine that can read seven segment display better. I came to know the ssocr (seven segment OCR), a OCR tools design to read only the seven segment display. So, I installed the tool in my Raspberry Pi and did some test with some sample images of multimeter and weight scale. In this blog I will represent the test result and compare with the previous result.
Installing SSOCR to Raspberry Pi
SSOCR does not provide ready to use binaries. You need to build it from source. In order to build ssocr from its source code, you will need some of the functionalities of the xlib (libx11) library in your system and the libimlib2 as well (library for image loading, rendering, saving images). You can install them easily with the following commands:
sudo apt-get update sudo apt-get install libx11-dev sudo apt-get install libimlib2-dev
After installing, you can proceed with the build of the ssocr library without any issue.
Best way to install from the latest version on github using the following command:
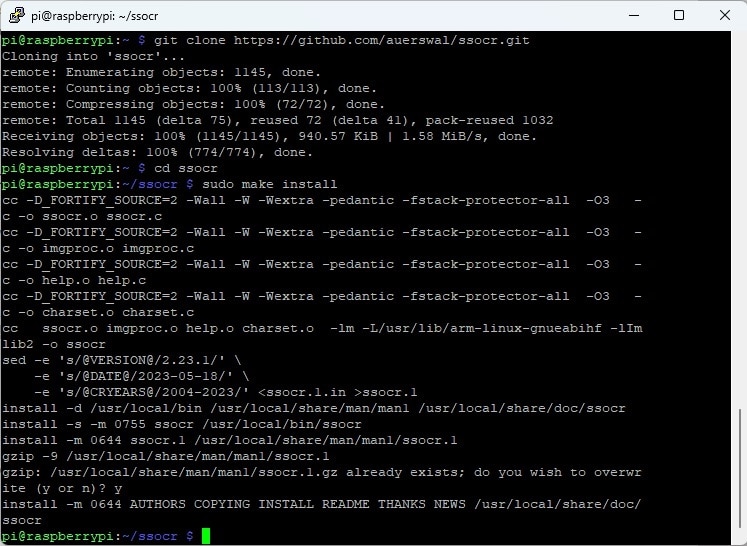
git clone https://github.com/auerswal/ssocr.git cd ssocr sudo make install
You will get the following message in the terminal if it goes correctly.
You can also install by downloading tar file.
wget http://www.unix-ag.uni-kl.de/~auerswal/ssocr/ssocr-2.23.1.tar.bz2 bzip2 -d ssocr-2.23.1.tar.bz2 tar xvf ssocr-2.23.1.tar cd ssocr-2.23.1/ sudo make
To test that it works, download the following sample image and give it a try.

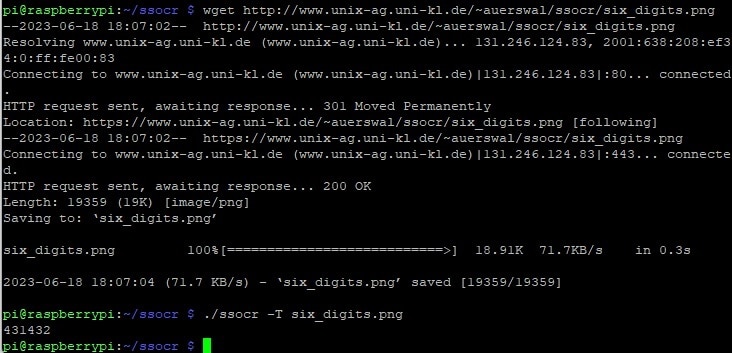
Use the following command to download the above test image and run the OCR tool:
wget http://www.unix-ag.uni-kl.de/~auerswal/ssocr/six_digits.png ./ssocr -T six_digits.png
If everything works well you will get the following output:
Testing ssocr using sample images
As my environment is ready I can now test the ssocr to understand how correctly it can determine the number from a seven segment display image. These are some sample images of multimeter and weight scale I am going to test using ssocr.

I then pre-processed those images using OpenCV to separate the text part. Following images shows the separated portion on which we are interested.
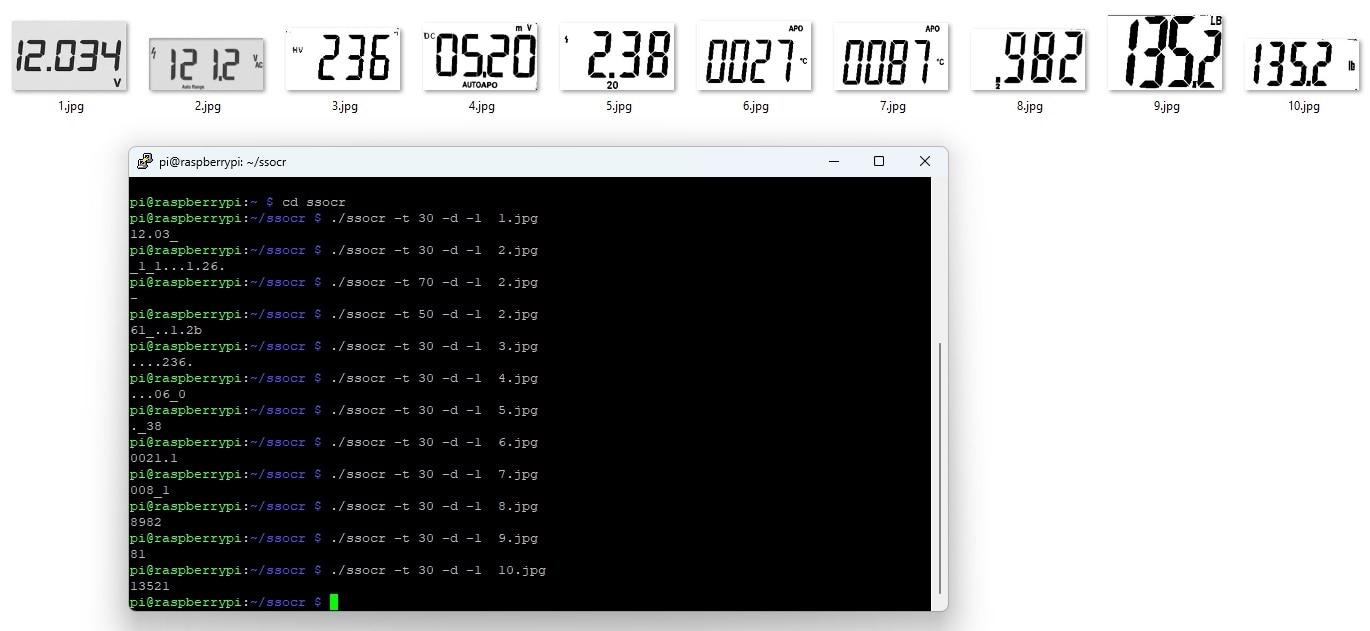
From the terminal screenshot above we can see the OCR result for each image but the result is not still satisfactory. One thing I realized that the image which contains any text or symbol at the beginning has bad ocr result. But the image that started only with the seven segment digit and have some symbol or text above or after the image can show a approximate ocr result. The image that contains only the digit without any symbol or text get accurately ocr result. For giving a clear proof I removes the beginning symbols from some of the images manually and test those again and the following terminal shows a better result that previous.
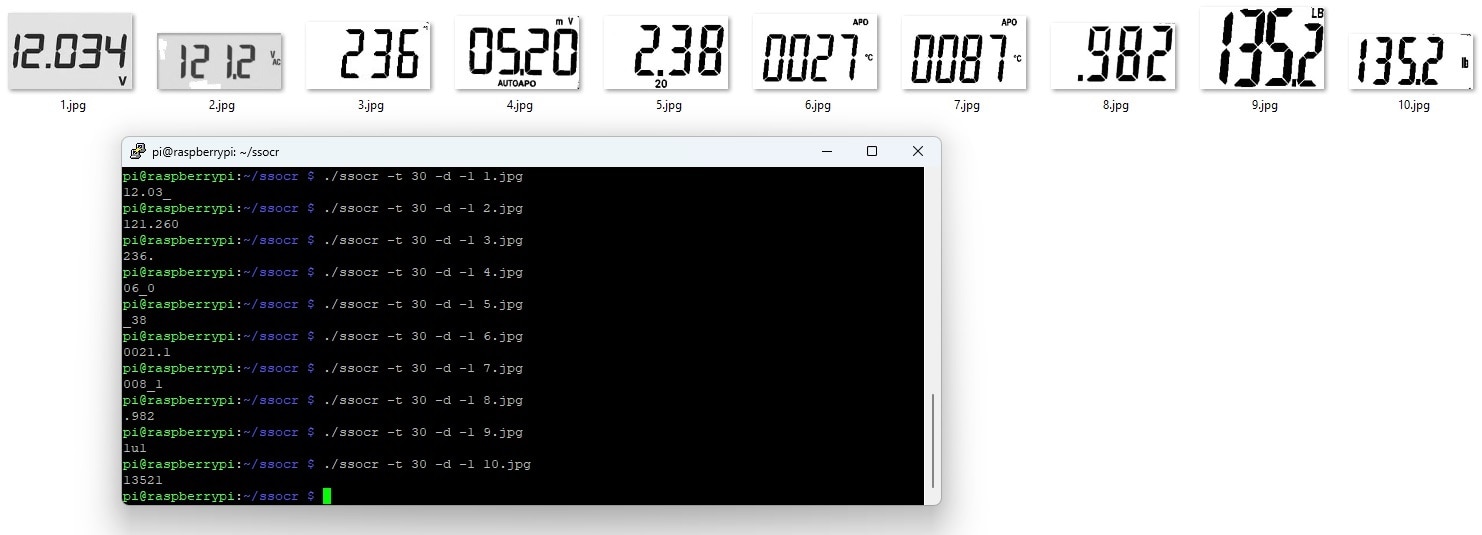
This is the operation result in a table:
| Preprocessed image | OCR result |
 |
12.03_ |
 |
121.260 |
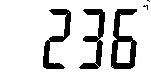 |
236. |
 |
06_0 |
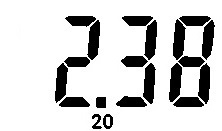 |
_38 |
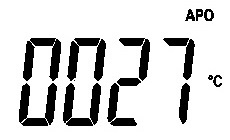 |
0021.1 |
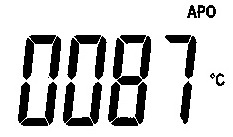 |
008_1 |
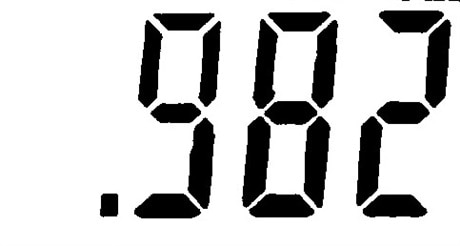 |
.982 |
 |
1u1 |
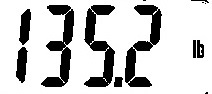 |
135.21 |
So, from two experiment first with tesseract ocr and the second with ssocr it is clear that no ocr is perfect. Tesseract is good for text ocr not for seven segment but ssocr is specially designed for detecting number from seven segment display. So, it gives better result from a seven segment display without any symbol or text on the display.
So, as no one is good for all situation I am going to use both of them in my project based on the display. I will add an extra button with the raspberry pi so that user can select the display type using the button. Based on the user input the suitable ocr engine will be applied for ocr operation.


