


General Considerations for Using LLM
While large language models are very powerful, their power requires a thoughtful approach. Here are some technical considerations.I think are very important:
- Context window limit - most of the current models have limitations on their input text and the generated output. It is measured in tokens. Two tokens can represent an average word, The current limit of GPT4ALL is 2048 tokens. Why it is important? The current LLM models are stateless and they can't create new memories. One of the workarounds is to provide the previous dialogue as input. This context should provide the summary of the previous dialogue. Otherwise, they will not be able to remember anything from the discussion. As a result, it puts a significant constraint to make them useful for scientific research, which requires a large amount of data..
- The LLM model size and the size of the context impact processing performance. And this impact can be very significant. Especially it is a concern for edge devices with limited computing and power. A LLM model needs to be loaded into RAM and significant extra memory space is required for their calculations. The bigger the input more processing time it will require.
GPT4ALL Performance Findings on RPi 4B
I was aware of memory considerations for LLM. So I've created a swap disk on RPi to add more memory for processing. This workaround comes with a huge performance impact as my sd card is much slower than my RAM,
I've modified the Python code and added some timer output, And then I run a few tests to measure performance,
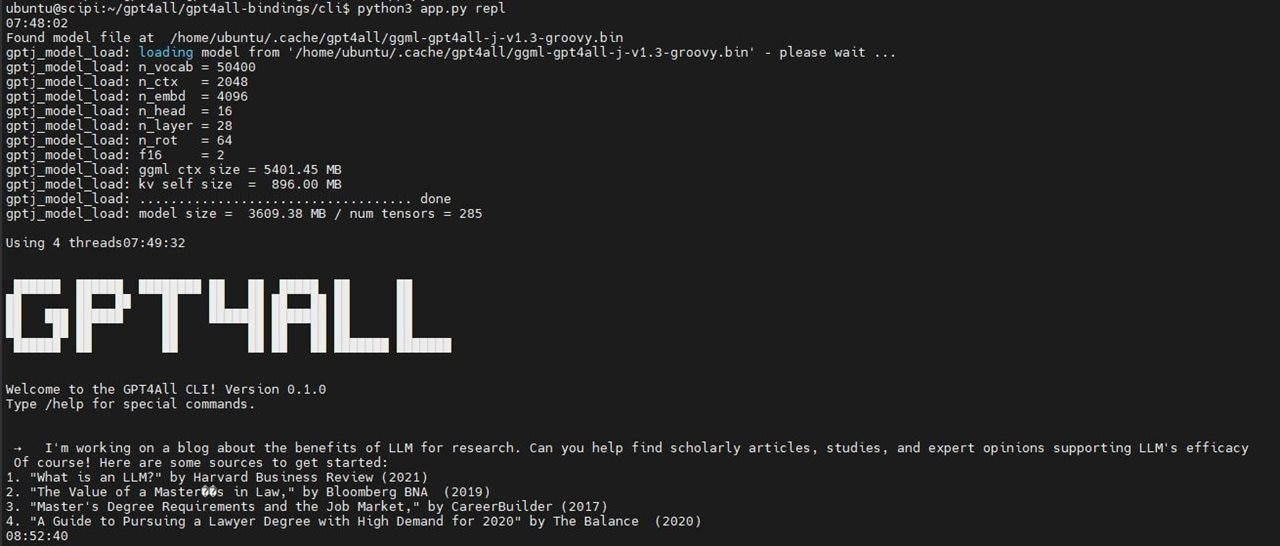
Based on this test the load time of the model was ~90 seconds. It took much longer to answer my question and generate output - 63 minutes. I've run another test and asked a short question.
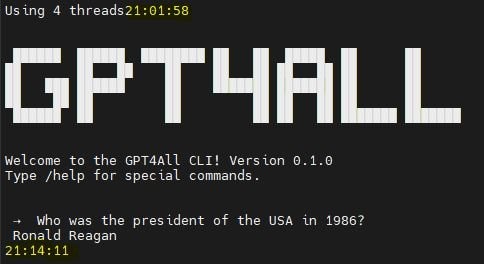
It took ~12 minutes to generate the answer.
I've used htop utility to look at resource usage. The RPi CPUs were not too busy during these tests.
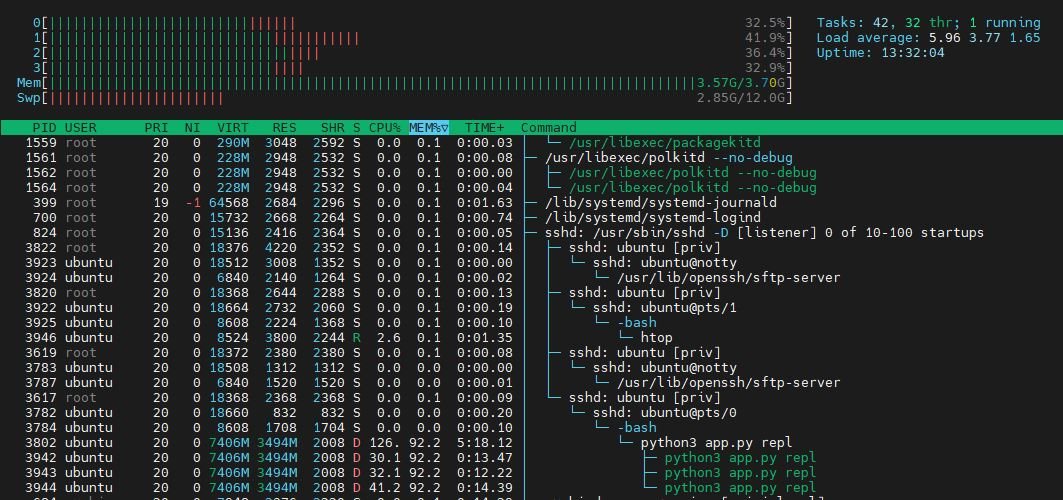
But RAM and swap were used extensively.

Potential Optimization Options
As this RPI 4B has only 4GB of RAM I start looking at what can be done to reduce the memory usage.
There are several techniques like distillation, pruning, and quantizing for LLM model optimization. These techniques allow for reducing the model size and memory usage.
Another direction is to find a model that has a smaller size and needs less RAM.
And there are some other ideas to improve performance without changing hardware: Here are some of them:
- Use free ARM-CPU optimized ArmPL library for ML
- Use the edge-optimized ML AIMET toolkit from Qualcomm
Samo options from a hardware perspective:
- Increase RAM to 8GB to fit the model in RAM and exclude the use of a swap
- Use faster storage to reduce the negative impact of swapping
- Use Hardware ML accelerators