

Introduction
The mains hum is generated by alternating current and contains multiple harmonics of its fundamental, which typically is either 50 or 60 Hz. I was wondering how I could synthesize the noise, which of course does not have much practical use as according to a small poll (Mains hum) the noise makes most people anxious.
Getting the sample
To get a good audio sample I began looking for samples in Youtube and found this one (which Dave Farmer kindly allowed me to use in this project):
Dave Farmer
The video was downloaded with JDownloader2 and ~26 s of audio were extracted with ffmpeg.
Audio analysis and synthesis
The spectrogram of the extracted audio sequence looked like this:

As it can be seen, it contains multiple harmonics of the 50 Hz fundamental. I then extracted a "clean" 5 s segment at the 13 s timestamp and computed the power spectrum density using Welch's method:
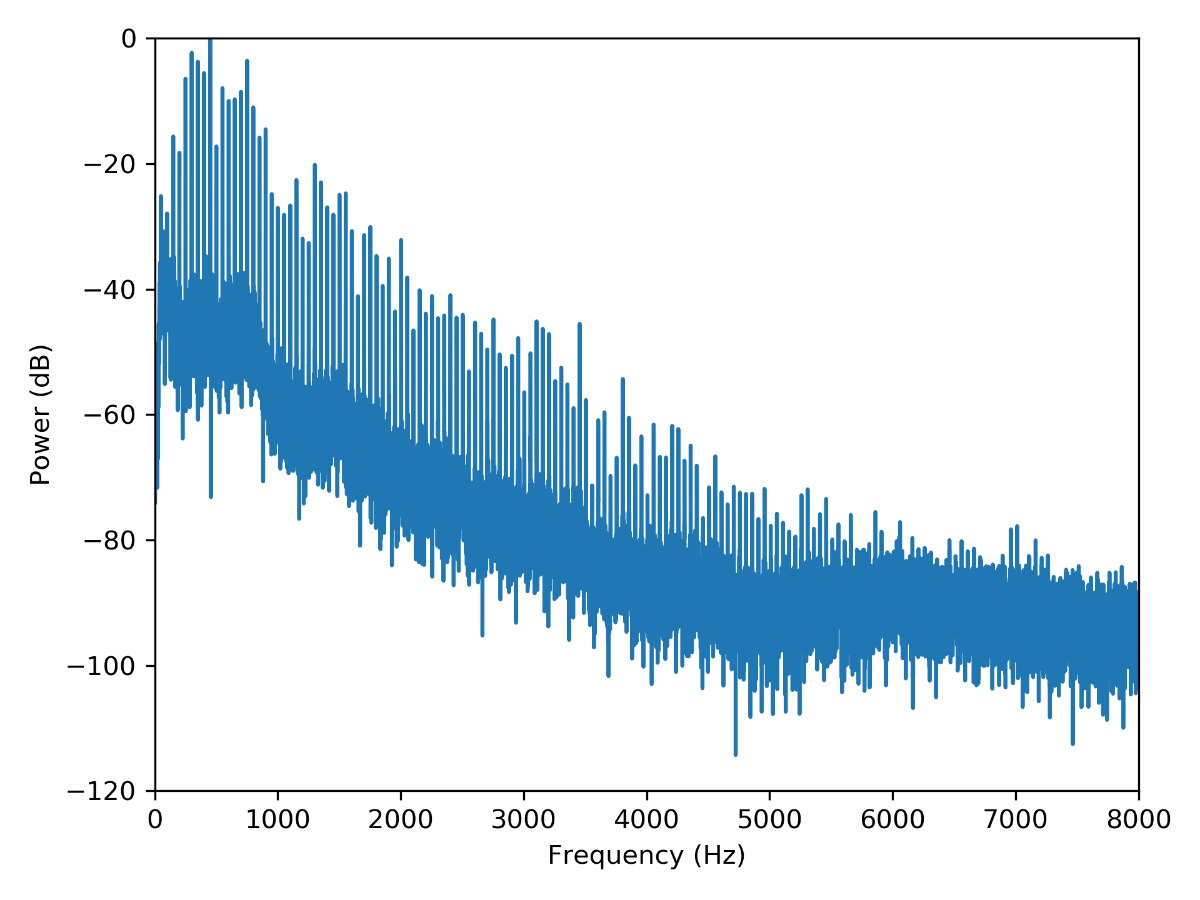
I then measured the amplitude of the fundamental and 99 harmonics and ran 100 oscillators at random phase shifts. The spectrum looked like this:

Even though the spectrums look quite different, they sound similar. Two important differences are that the synthetic hum is stationary, while the recorded one is not (it changes with time), and the second difference is that the recorded hum contains noise (wind on the microphone, etc), while the synthetic hum doesn't. The video compared the recorded segment to the synthetic segment:
I tried covering all harmonics up to lower frequencies using fewer oscillators, but I noticed that with fewer than 80 oscillators the synthetic hum began sounding quite different to the original.
Here's the code used to generate the audio and the figures:
import numpy
import sounddevice as sound
import scipy.io.wavfile as wavfile
import scipy.signal as signal
import matplotlib.pyplot as pyplot
duration = 5
sampleRate = 44100
fundamental = 50.085
nHarmonics = 100
delta = 25
audioRate, wave = wavfile.read('../Data/hum.wav')
wave = wave[:, 0].astype(numpy.float)
pyplot.specgram(wave, NFFT = 8000, Fs = audioRate, noverlap = 4000, detrend = 'mean')
pyplot.ylim(0, 8000)
pyplot.xlabel('Time (s)')
pyplot.ylabel('Frequency (Hz)')
pyplot.tight_layout()
pyplot.savefig('../Data/Spectrogram.png', dpi = 300)
pyplot.close()
wave = wave[int(13. * audioRate) : int(18. * audioRate)]
wave = wave / numpy.abs(wave).max()
frequency, power = signal.welch(wave, fs = audioRate, nperseg = 1024 * 16)
harmonics = numpy.zeros(nHarmonics)
frequencies = numpy.zeros(nHarmonics)
for i in range(nHarmonics):
higher = frequency > ((i + 1) * fundamental) - delta / 2
lower = frequency < ((i + 1) * fundamental) + delta / 2
harmonics[i] = numpy.max(power[numpy.logical_and(lower, higher)])
t = numpy.arange(sampleRate * duration) / sampleRate
f = numpy.zeros(sampleRate * duration)
for i, h in enumerate(harmonics):
f += numpy.sin(2 * numpy.pi * (fundamental) * (i + 1) * t + numpy.random.random(1)[0]* numpy.pi * 2) * numpy.sqrt(h)
f = f / numpy.abs(f).max()
frequency1, power1 = signal.welch(wave, fs = audioRate, nperseg = 1024 * 128)
frequency2, power2 = signal.welch(f, fs = audioRate, nperseg = 1024 * 128)
pyplot.plot(frequency1, 10 * numpy.log10(power1 / power1.max()))
pyplot.xlim(0, 8000)
pyplot.ylim(-120, 0)
pyplot.xlabel('Frequency (Hz)')
pyplot.ylabel('Power (dB)')
pyplot.tight_layout()
pyplot.savefig('../Data/Recorded.png', dpi = 300)
pyplot.close()
pyplot.plot(frequency1, 10 * numpy.log10(power1 / power1.max()))
pyplot.plot(frequency2, 10 * numpy.log10(power2 / power2.max()))
pyplot.xlim(0, 8000)
pyplot.ylim(-120, 0)
pyplot.xlabel('Frequency (Hz)')
pyplot.ylabel('Power (dB)')
pyplot.legend(['Recorded', 'Synthesized'], frameon = False)
pyplot.tight_layout()
pyplot.savefig('../Data/Synthesized.png', dpi = 300)
pyplot.close
wavfile.write('../Data/Recorded.wav', 44100, (wave * ((2. ** 15.) - 1)).astype(numpy.int16))
wavfile.write('../Data/Synthesized.wav', 44100, (f * ((2. ** 15.) - 1)).astype(numpy.int16))
sound.play(wave, 44100)
sound.wait()
sound.play(f, 44100)
sound.wait()
Conclusion
This simple project showed that it is possible to mimic a relatively simple "real sound" through simple wave analysis and audio synthesis. It also shows that the auditory system puts different emphasis on different aspects of acoustic waves, the oscillator phase difference for instance was likely very different to that of the recording and still sounded very similar to the original recording.
Top Comments