


 | Enter Your Project for a chance to win an Oscilloscope Grand Prize Package for the Most Creative Vision Thing Project! | Project14 Home |
| Monthly Themes | ||
| Monthly Theme Poll |

Content

Forget your KEY and your SECRET PASSCODE? That is OK if you are with AILOCK.
You can have one with BeagleBone AI and do it by yourself in FOUR
1st Hour, unboxing and start coding immediately, crack the code with bare C++ in one of PRU ARM-M4 core,
BBAI with Out-of-Box ecosystem makes everyone build AI application with ease. If you want to dig further with extended capabilities , Refer to my Animation Project Scary Door and BeagleBone AI - Review .
1. Introduction
1.1 Why AI Lock
Simple as it it, you can not return your home if you misplace your key.
You can have smart door lock below,


But still not smart enough, the lock only knows the NFC tags and Mobile Open Tokens, or the smartest one which knows your fingerprint.
You can choose to have one lock knows you and only you with deep learning Computer Vision (CV).
1.2 What to Have
- One BeagleBone AI board, with embedded software for everything
- One USB Camera
- One 3.3V DC motor
- One normal door lock for refurbishment
- No more development software needed, you have C9 Cloud already
1.3 Highlights
- Easy to use, boosting performance,
- Steep Learning curve, sometimes it is painful
- Perfect for Commercial Development. Many tools support easy to use embedded Deep Learning functions, including Python-scikit, OpenCV, or even Tensorflow Lite. Only TIDL provides multi-device-host pipeline, I guess , the first one ready for large scale production. Of course, it is not perfect like the heating issue, which is same
Many tools support easy to use embedded Deep Learning functions, including Python-scikit, OpenCV, or even Tensorflow Lite. Only TIDL provides multi-device-host pipeline, I guess , the first one ready for large scale production. Of course, it is not perfect like the heating issue, which is same
2. Codes
As far as I know, BeagleBone AI is the first Industrialized products for AI application. Complete development ecosystem and fastest deployment.
For this aiLock, the Block Structure shall be
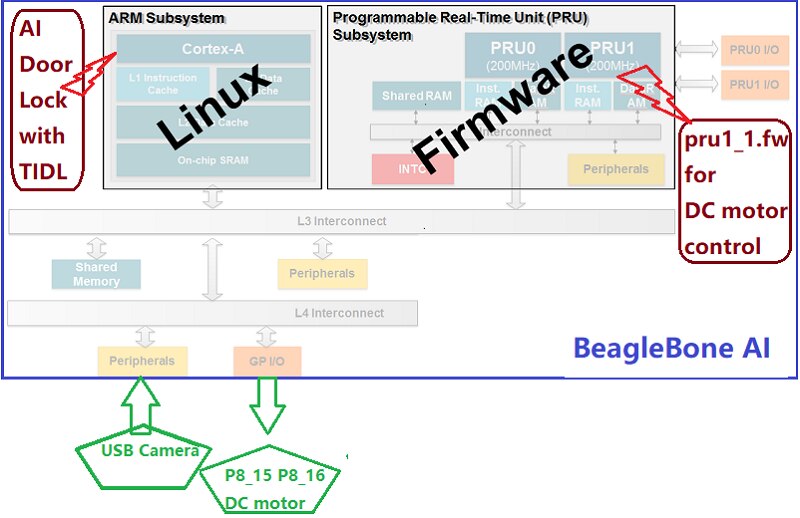
2.1 Versatile Inter Processor Connection, Remote Connection and PinMux
PRU-- Programmable Real-Time Unit Subsystem and Industrial Communication SubSystem (PRU-ICSS) consists of dual 32-bit RISC cores (Programmable Real-Time Units, or PRUs), data and instruction memories, internal peripheral modules, and an interrupt controller (INTC) with dual ARM Cortex-M4 subsystem. This is best choice for GPIO control and can even be programmed into I2C, SPI, CAN communication protocols as you like. Best thing is that if you use register _R30 , no need to turn off triggers or set pin direction.



Here is code for PRU, with direct access to PinMux, sharememory shall be used as IPC between PRU and Linux Core.
////////////////////////////////////////
// ailock.pru1_1.c
////////////////////////////////////////
#include <stdint.h>
#include <pru_cfg.h>
#include <pru_ctrl.h>
#include <stddef.h>
#include <rsc_types.h>
#include "resource_table_empty.h"
#include "init_pins_empty.h"
#include "prugpio.h"
#include <time.h>
#define SHARED_RAM_ADDRESS 0x10000
unsigned int volatile __far * const SHARED_RAM = (unsigned int *) (SHARED_RAM_ADDRESS);
#define CLEARBIT 0xAAAAAAAA
#define LOCKON 8
#define LOCKOFF 4
#define LEDBLK 2
#define ON 1
#define OFF 0
volatile register unsigned int __R30;
volatile register unsigned int __R31;
void mvlock(uint32_t outpin, uint32_t onoff );
void blinky(uint32_t outpin, uint32_t bktimes );
void main(void) {
unsigned int value = 255;
/* Set the SHARED_RAM value to 0 */
*SHARED_RAM = 255;
//uint32_t gpio=P8_26 |P8_15 |P8_16 ;
uint32_t ledpin=P8_26;
uint32_t lockpin = P8_15 |P8_16 ; //
//blinky(ledpin,2);
while(1) {
/* Look for the ARM to modify the SHARED_RAM value */
if(value != *SHARED_RAM) {
/* Flip every other bit and write the value back */
value = *SHARED_RAM;
if(value==OFF){
// ALLOFF .
} else if (value==LEDBLK){
// LEDBLK.
//blinky(ledpin,LEDBLK);
} else if (value==LOCKOFF){
// LOCKOFF.
mvlock(lockpin, OFF);
blinky(ledpin,LOCKOFF);
} else if (value==LOCKON){
// ELOCKON.
mvlock(lockpin, ON);
//blinky(ledpin,LOCKON);
} else {
// Exit Empty.
}
// End of if-else
value ^= 0xAAAAAAAA;*SHARED_RAM = value;
}
}
}
void blinky(uint32_t outpin,uint32_t bktimes ){
uint32_t i;
for(i=0; i<bktimes; i++) {
// blink indicator 5 times
__R30 &= ~outpin; // Set the GPIO pin to 1
__delay_cycles(500000000/5); // Wait 0.5 second
__R30 |= outpin; // Clear the GPIO pin
__delay_cycles(500000000/5);
__R30 &= ~outpin; // Set the GPIO pin to 1
__delay_cycles(500000000/5); // Wait 0.5 second
}
return;
}
void mvlock(uint32_t outpin, uint32_t onoff){
uint32_t i,duemilli;
duemilli=3000; // Duetime for millicecond;
time_t timer = time(0);
// Clear the bits
__R30 &= ~outpin; // or __R30 |= outpin;
__delay_cycles(1000000/5); // Delay 1ms;
if(onoff==ON){
__R30 &= ~P8_15 ;
__delay_cycles(1000000/5); // Delay 1ms;
__R30 |= P8_16 ;
} else if (onoff==OFF){
__R30 &= ~P8_16 ;
__delay_cycles(1000000/5); // Delay 1ms;
__R30 |= P8_15 ;
} else {
// Power OFF and alert
}
for (i=0;i<duemilli;i++){
__delay_cycles(1000000/5);
}
__R30 &= ~outpin; __delay_cycles(500000000/5); // Clear bits.
return;
}Build and RUN,

2nd Hour, Go to deep learning part with TIDL, read through Classification Demo Code and revise it,
LINUX APPLICATION --The LINUX core runs on Dual ARM Cortex-A15 subsystem supporting the most desirable Deep Learning Framework. Easy to deployed two TI C66x VLIW floating-point DSP core and Vision AccelerationPac (with 4x EVEs) are core engines in accelerating the intense computing load.
Here is full code on LINUX APPLICATION,, based on classification demo code,
/******************************************************************************
*****************************************************************************/
#include <signal.h>
#include <getopt.h>
#include <iostream>
#include <iomanip>
#include <fstream>
#include <cassert>
#include <string>
#include <functional>
#include <queue>
#include <algorithm>
#include <time.h>
#include <memory.h>
#include <string.h>
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <mosquitto.h>
#include "executor.h"
#include "execution_object.h"
#include "execution_object_pipeline.h"
#include "configuration.h"
#include "imgutil.h"
#include "opencv2/opencv.hpp"
#include "opencv2/core.hpp"
#include "opencv2/imgproc.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/videoio.hpp"
#define MAX_EOPS 8
#define MAX_CLASSES 1100
#define HOST "localhost"
#define PORT 1883
#define KEEP_ALIVE 60
#define MSG_MAX_SIZE 16
#define PRUSS_SHARED_RAM_OFFSET 0x10000
#define LOCKON 8
#define LOCKOFF 4
using namespace tidl;
using namespace cv;
using namespace std;
int current_eop = 0;
int num_eops = 0;
int top_candidates = 3;
int size = 0;
int selected_items_size;
int * selected_items;
std::string * labels_classes[MAX_CLASSES];
Configuration configuration;
Executor *e_eve = nullptr;
Executor *e_dsp = nullptr;
std::vector<ExecutionObjectPipeline *> eops;
int last_rpt_id = -1;
bool session = true;
struct mosquitto *mosq = NULL;
char buff[MSG_MAX_SIZE];
unsigned int mem_dev= open("/dev/uio0", O_RDWR | O_SYNC);
volatile int *shared_dataram =(int*)mmap(NULL,
16+PRUSS_SHARED_RAM_OFFSET, /* grab 16 bytes of shared dataram, must allocate with offset of 0 */
PROT_READ | PROT_WRITE,
MAP_SHARED,
mem_dev,
0
);
bool CreateExecutionObjectPipelines();
void AllocateMemory(const std::vector<ExecutionObjectPipeline*>& eops);
bool ProcessFrame(ExecutionObjectPipeline* eop, Mat &src);
void DisplayFrame(const ExecutionObjectPipeline* eop, Mat& dst);
int tf_postprocess(uchar *in);
bool tf_expected_id(int id);
void populate_labels(const char* filename);
void flip_test(void);
void mv_lock(uint32_t on_off);
// exports for the filter
extern "C" {
bool filter_init(const char* args, void** filter_ctx);
void filter_process(void* filter_ctx, Mat& src, Mat& dst);
void filter_free(void* filter_ctx);
}
bool verbose = false;
/**
Initializes the filter. If you return something, it will be passed to the
filter_process function, and should be freed by the filter_free function
*/
bool filter_init(const char* args, void** filter_ctx) {
shared_dataram += (PRUSS_SHARED_RAM_OFFSET/4);
printf("shared_dataram = %p, and data=%d \n", shared_dataram,*shared_dataram);
mosquitto_lib_init();
mosq = mosquitto_new(NULL,session,NULL);
std::cout << "Initializing MQTT and SHARE_MEMORY" << std::endl;
if(!mosq){
printf("create client failed..\n");
mosquitto_lib_cleanup();
return 1;
}
mosquitto_username_pw_set(mosq,"scaryball","scaryball");
if(mosquitto_connect(mosq, HOST, PORT, KEEP_ALIVE)){
fprintf(stderr, "Unable to connect.\n");
return 1;
}
mosquitto_publish(mosq,NULL,"lockstatus",strlen(buff)+1,buff,0,0);
memset(buff,0,sizeof(buff));
flip_test();
std::cout << "Initializing filter" << std::endl;
populate_labels("/usr/share/ti/examples/tidl/classification/imagenet.txt");
selected_items_size = 10;
selected_items = (int *)malloc(selected_items_size*sizeof(int));
if (!selected_items) {
std::cout << "selected_items malloc failed" << std::endl;
return false;
}
selected_items[0] = 429; /* baseball */
selected_items[1] = 837; /* sunglasses */
selected_items[2] = 504; /* coffee_mug */
selected_items[3] = 441; /* beer_glass */
selected_items[4] = 898; /* water_bottle */
selected_items[5] = 931; /* bagel */
selected_items[6] = 531; /* digital_watch */
selected_items[7] = 487; /* cellular_telephone */
selected_items[8] = 722; /* ping-pong_ball */
selected_items[9] = 720; /* pill_bottle */
std::cout << "loading configuration" << std::endl;
configuration.numFrames = 0;
configuration.inData =
"/usr/share/ti/examples/tidl/test/testvecs/input/preproc_0_224x224.y";
configuration.outData =
"/usr/share/ti/examples/tidl/classification/stats_tool_out.bin";
configuration.netBinFile =
"/usr/share/ti/examples/tidl/test/testvecs/config/tidl_models/tidl_net_imagenet_jacintonet11v2.bin";
configuration.paramsBinFile =
"/usr/share/ti/examples/tidl/test/testvecs/config/tidl_models/tidl_param_imagenet_jacintonet11v2.bin";
configuration.preProcType = 0;
configuration.inWidth = 224;
configuration.inHeight = 224;
configuration.inNumChannels = 3;
configuration.layerIndex2LayerGroupId = { {12, 2}, {13, 2}, {14, 2} };
configuration.enableApiTrace = false;
configuration.runFullNet = true;
try
{
std::cout << "allocating execution object pipelines (EOP)" << std::endl;
// Create ExecutionObjectPipelines
if (! CreateExecutionObjectPipelines())
return false;
// Allocate input/output memory for each EOP
std::cout << "allocating I/O memory for each EOP" << std::endl;
AllocateMemory(eops);
num_eops = eops.size();
std::cout << "num_eops=" << num_eops << std::endl;
std::cout << "About to start ProcessFrame loop!!" << std::endl;
std::cout << "http://localhost:8080/?action=stream" << std::endl;
}
catch (tidl::Exception &e)
{
std::cerr << e.what() << std::endl;
return false;
}
/*** Test integrity of SHAREMEMORY again;
for(i=0; i<10; i++) {
printf("Writing 0x%08x\n", i);
*shared_dataram = i;
usleep(1);
j = *shared_dataram;
printf("Read 0x%08x (%s, Mask=0x%08x)\n", j, j==i?"not flipped":"flipped!", j^i);
}
***/
return true;
}
/**
Called by the OpenCV plugin upon each frame
*/
void filter_process(void* filter_ctx, Mat& src, Mat& dst) {
int doDisplay = 0;
dst = src;
try
{
// Process frames with available EOPs in a pipelined manner
// additional num_eops iterations to flush the pipeline (epilogue)
ExecutionObjectPipeline* eop = eops[current_eop];
// Wait for previous frame on the same eo to finish processing
if(eop->ProcessFrameWait()) doDisplay = 1;
ProcessFrame(eop, src);
if(doDisplay) DisplayFrame(eop, dst);
current_eop++;
if(current_eop >= num_eops)
current_eop = 0;
}
catch (tidl::Exception &e)
{
std::cerr << e.what() << std::endl;
}
return;
}
/**
Called when the input plugin is cleaning up
*/
void filter_free(void* filter_ctx) {
try
{
// Cleanup
for (auto eop : eops)
{
free(eop->GetInputBufferPtr());
free(eop->GetOutputBufferPtr());
delete eop;
}
if (e_dsp) delete e_dsp;
if (e_eve) delete e_eve;
}
catch (tidl::Exception& e)
{
std::cerr << e.what() << std::endl;
}
mosquitto_destroy(mosq);
mosquitto_lib_cleanup();
return;
}
bool CreateExecutionObjectPipelines()
{
const uint32_t num_eves = 4;
const uint32_t num_dsps = 0;
const uint32_t buffer_factor = 1;
DeviceIds ids_eve, ids_dsp;
for (uint32_t i = 0; i < num_eves; i++)
ids_eve.insert(static_cast<DeviceId>(i));
for (uint32_t i = 0; i < num_dsps; i++)
ids_dsp.insert(static_cast<DeviceId>(i));
#if 0
// Create Executors with the approriate core type, number of cores
// and configuration specified
// EVE will run layersGroupId 1 in the network, while
// DSP will run layersGroupId 2 in the network
std::cout << "allocating executors" << std::endl;
e_eve = num_eves == 0 ? nullptr :
new Executor(DeviceType::EVE, ids_eve, configuration, 1);
e_dsp = num_dsps == 0 ? nullptr :
new Executor(DeviceType::DSP, ids_dsp, configuration, 2);
// Construct ExecutionObjectPipeline that utilizes multiple
// ExecutionObjects to process a single frame, each ExecutionObject
// processes one layerGroup of the network
// If buffer_factor == 2, duplicating EOPs for pipelining at
// EO level rather than at EOP level, in addition to double buffering
// and overlapping host pre/post-processing with device processing
std::cout << "allocating individual EOPs" << std::endl;
for (uint32_t j = 0; j < buffer_factor; j++)
{
for (uint32_t i = 0; i < std::max(num_eves, num_dsps); i++)
eops.push_back(new ExecutionObjectPipeline(
{(*e_eve)[i%num_eves], (*e_dsp)[i%num_dsps]}));
}
#else
e_eve = num_eves == 0 ? nullptr :
new Executor(DeviceType::EVE, ids_eve, configuration);
e_dsp = num_dsps == 0 ? nullptr :
new Executor(DeviceType::DSP, ids_dsp, configuration);
// Construct ExecutionObjectPipeline with single Execution Object to
// process each frame. This is parallel processing of frames with
// as many DSP and EVE cores that we have on hand.
// If buffer_factor == 2, duplicating EOPs for double buffering
// and overlapping host pre/post-processing with device processing
for (uint32_t j = 0; j < buffer_factor; j++)
{
for (uint32_t i = 0; i < num_eves; i++)
eops.push_back(new ExecutionObjectPipeline({(*e_eve)[i]}));
for (uint32_t i = 0; i < num_dsps; i++)
eops.push_back(new ExecutionObjectPipeline({(*e_dsp)[i]}));
}
#endif
return true;
}
void AllocateMemory(const std::vector<ExecutionObjectPipeline*>& eops)
{
for (auto eop : eops)
{
size_t in_size = eop->GetInputBufferSizeInBytes();
size_t out_size = eop->GetOutputBufferSizeInBytes();
std::cout << "Allocating input and output buffers" << std::endl;
void* in_ptr = malloc(in_size);
void* out_ptr = malloc(out_size);
assert(in_ptr != nullptr && out_ptr != nullptr);
ArgInfo in(in_ptr, in_size);
ArgInfo out(out_ptr, out_size);
eop->SetInputOutputBuffer(in, out);
}
}
bool ProcessFrame(ExecutionObjectPipeline* eop, Mat &src)
{
if(configuration.enableApiTrace)
std::cout << "preprocess()" << std::endl;
imgutil::PreprocessImage(src,
eop->GetInputBufferPtr(), configuration);
eop->ProcessFrameStartAsync();
//flip_test();
return false;
}
void DisplayFrame(const ExecutionObjectPipeline* eop, Mat& dst)
{
if(configuration.enableApiTrace)
std::cout << "postprocess()" << std::endl;
int is_object = tf_postprocess((uchar*) eop->GetOutputBufferPtr());
if(is_object >= 0)
{
cv::putText(
dst,
(*(labels_classes[is_object])).c_str(),
cv::Point(15, 60),
cv::FONT_HERSHEY_SIMPLEX,
1.5,
cv::Scalar(0,255,0),
3, /* thickness */
8
);
mv_lock(LOCKON);
}
if(last_rpt_id != is_object) {
if(is_object >= 0)
{
std::cout << "(" << is_object << ")="
<< (*(labels_classes[is_object])).c_str() << std::endl;
}
last_rpt_id = is_object;
}
}
// Function to filter all the reported decisions
bool tf_expected_id(int id)
{
// Filter out unexpected IDs
for (int i = 0; i < selected_items_size; i ++)
{
if(id == selected_items[i]) return true;
}
return false;
}
int tf_postprocess(uchar *in)
{
//prob_i = exp(TIDL_Lib_output_i) / sum(exp(TIDL_Lib_output))
// sort and get k largest values and corresponding indices
const int k = top_candidates;
int rpt_id = -1;
typedef std::pair<uchar, int> val_index;
auto constexpr cmp = [](val_index &left, val_index &right) { return left.first > right.first; };
std::priority_queue<val_index, std::vector<val_index>, decltype(cmp)> queue(cmp);
// initialize priority queue with smallest value on top
for (int i = 0; i < k; i++) {
if(configuration.enableApiTrace)
std::cout << "push(" << i << "):"
<< in[i] << std::endl;
queue.push(val_index(in[i], i));
}
// for rest input, if larger than current minimum, pop mininum, push new val
for (int i = k; i < size; i++)
{
if (in[i] > queue.top().first)
{
queue.pop();
queue.push(val_index(in[i], i));
}
}
// output top k values in reverse order: largest val first
std::vector<val_index> sorted;
while (! queue.empty())
{
sorted.push_back(queue.top());
queue.pop();
}
for (int i = 0; i < k; i++)
{
int id = sorted[i].second;
if (tf_expected_id(id))
{
rpt_id = id;
}
}
return rpt_id;
}
void populate_labels(const char* filename)
{
ifstream file(filename);
if(file.is_open())
{
string inputLine;
while (getline(file, inputLine) ) //while the end of file is NOT reached
{
labels_classes[size++] = new string(inputLine);
}
file.close();
}
#if 0
std::cout << "==Total of " << size << " items!" << std::endl;
for (int i = 0; i < size; i ++)
std::cout << i << ") " << *(labels_classes[i]) << std::endl;
#endif
}
void flip_test(void){
int i,j;
for(i=0; i<10; i++) {
printf("Writing 0x%08x\n", i);
*shared_dataram = i;
usleep(1);
j = *shared_dataram;
printf("Read 0x%08x (%s, Mask=0x%08x)\n", j, j==i?"not flipped":"flipped!", j^i);
}
mosquitto_publish(mosq,NULL,"lockstatus",strlen(buff)+1,buff,0,0);
memset(buff,0,sizeof(buff));
}
void mv_lock(uint32_t on_off){
int i,j;
i=on_off;
printf("Writing 0x%08x\n", on_off);
*shared_dataram = i;
usleep(1);
j = *shared_dataram;
printf("Read 0x%08x (%s, Mask=0x%08x)\n", j, j==i?"not flipped":"flipped!", j^i);
buff[0]=char(on_off);
mosquitto_publish(mosq,NULL,"lockstatus",strlen(buff)+1,buff,0,0);
memset(buff,0,sizeof(buff));
}Here is some screenshot result,
Program starting,
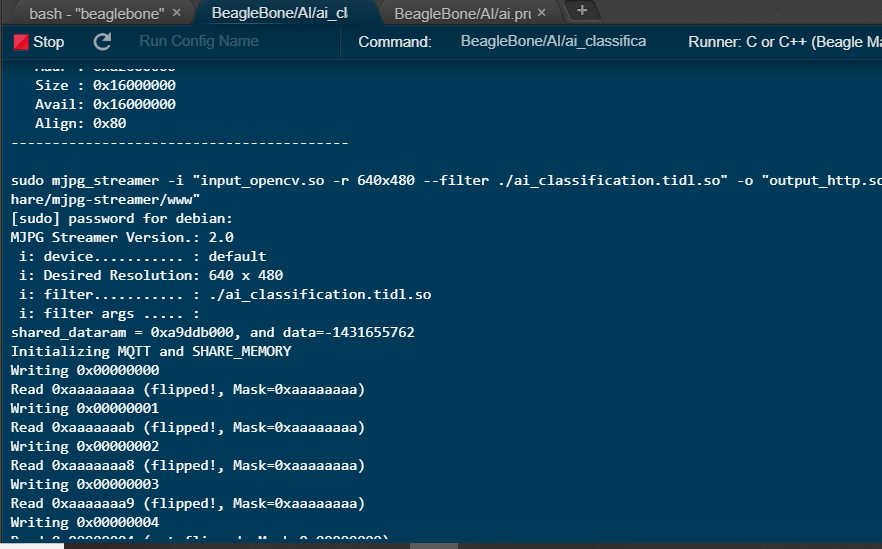
One glass was detected , that is my eyeglass,

UI -- Computer Vision shall be displayed vividly for humans. User friendly Interface shall be provided. LCD panel, LED indicator, mobile APP, HTML page can all be proper choice.
Therefore, Intercommunication for PRU, LINUX APPLICATION and UI shall be configured reliable and elastically. In BeagleBone AI , IPC(Inter-Processor Communication) in shared memory is idea for PRU vs LINUX APPLICATION. Message broker service like MQTT is idea for LINUX APPLICATION vs UI.
The code for MQTT implementation on HTML web page or other portal is easy and reliable. MQTT server can run on local BeagleBone AI or remote Broker Server like arduino cloud.
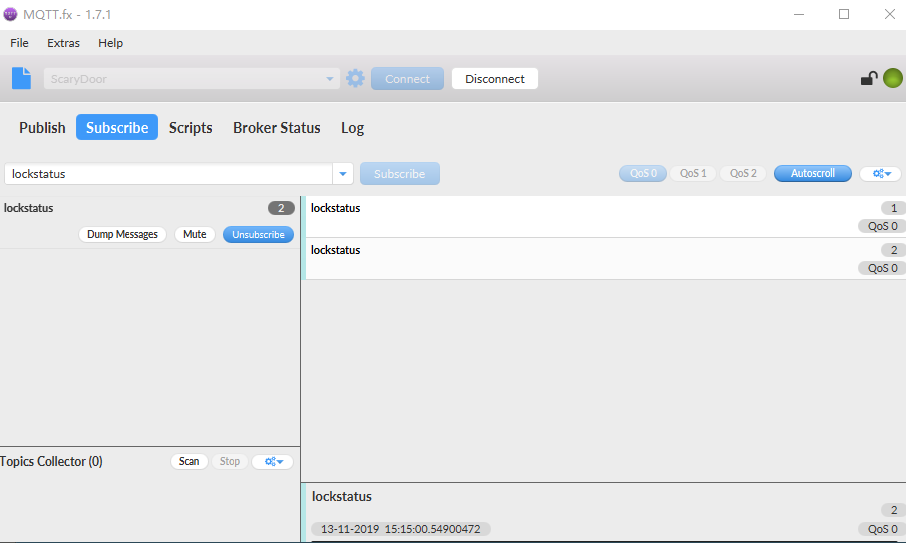
Mosquitto Broker listen on port 1883,

Refer to the screenshot from MQTT.fx for information, MQTT topic "lockstatus" was published twice from LINUX APPLICATION above,
Other code would be added later.
3rd Hour, Understand TIDL better and try modifying your model or even optional extra hours on training your model,
2.2 Deep Learning with TIDL
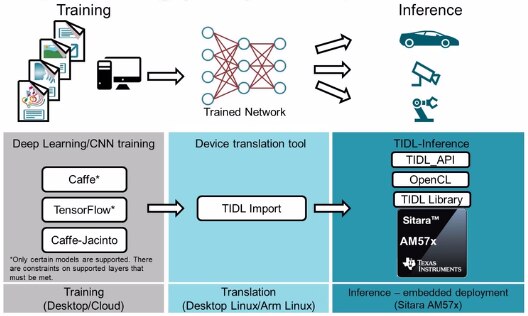
In the center of LINUX APPLICATION aboveis TIDL. TIDL(TI Deep Learning) enables Deep Learning compute workloads from Arm cores to hardware accelerators such as TI’s proprietary EVE and/or C66x DSP, with boosting performance. Google offer versatile Tensorflow Lite for embedded devices even on SAMD-core arduino board, with compensable performance optimization and deduction. This is why TIDL is so different in focus on performance boosting, refer to TIDL development flow diagram below.
- Classification Model sample
This part is the same as previous code in LINUX APPLICATION part,
- Select model and train with new data
The most challenge part, in most case, you can skip this part, since most of the work shall be done on GPUs, at least on your desktop. There have been many well trained model with years of development and research, if not for commercial, you can use them for free, sucha as CAFFEE model ZOO.
4th Hour, fix one small 3V DC motor and try to make AI Door Lock work,
3 Hardware and Build
3.1 Normal Door Lock Breakout
Find one door lock and disassemble it.


3.2 aiLock Refurbishment
Replace on bottom plate and fix one small DC motor and trigger plate. Then wiring the DC motor to BBAI directly on PinMux in PRU part. In this case, P8_26 for LED and P8_15&P8_16 for door lock open motor.
Do not worried about the DC load, by mistake, I have blacked out the BBAI with one large DC motor. The TPSxxxx PMIC proves its value and protect the BBAI. Check the datasheet, DC motor load less than 1W means nothing to BBAI. Theheatsink above the AM57xx chip can boil one small quail egg if you really want a try.
After test, very small motor can work on GPIO with maximum ouput of 5mA, but the torque is not enough to drive the handle, the gear set is small enough to fit into the lock case, and the motor can not fit in.




I shall design better hardware arrangement to put them all in most compact space later.
I have to select9g servo , with bigger size to show how it works.

3.3 aiLock fixed into Door
Wiring the BB AI and USB camera ,

Fix the lock back to the door, in reverse order you have disasambled it.
4 The AI Lock, Finally
4.1 BBAI have try everything to save us from library dependancy and conflicts. For example, you can update the cloud9 demo codes with ,
git pull
Install mosquitto MQTT service with ,
apt-get install mosquitto
During development, no need for your consideration of MakeFile, just press the run botton on cloud9 menu bar.
Ease of use on BeagleBone AI does not mean that it is easy in exploring technical issues.It only shows how many wit embedded on this dev board. On the contrary, it is so tough a job worth a try. I would give a close look into the BeagleBone AI when buiding this project AILOCK.
4.2 Once you master all, it is obvious that beyond the aiLOCK,you can do more as long as your imagination can reach.
4.3 Finally, one aiLock in operation is real reward to yourself.


Reference,
- BeagleBone AI - Review
- AM5728 Sitara Processor: Dual Arm Cortex-A15 & Dual DSP, Multimedia | TI.com
- TPS659037 Power Management IC (PMIC) for ARM Cortex A15 Processors | TI.com
- Home Page ofr Beaglebone AI https://beagleboard.org/ai
- Software IMG https://beagleboard.org/latest-images
- Quick start guide in github https://github.com/beagleboard/beaglebone-ai/wiki/Quick-Start-Guide
- Opensource hardware and software lib https://github.com/beagleboard/beaglebone-ai
- Getstart on TIDL Examples — TIDL API User's Guide
- Cloud9 Examples in github https://github.com/beagleboard/cloud9-examples
- The most Important One https://github.com/beagleboard/beaglebone-ai/wiki/System-Reference-Manual to get updates to the board, there have been many TODO with blank space awaiting. What really matters it every items is eactly right to BeagleBone AI. You shall know, even the PinMux for BeagleBone Black may not same as BeagleBone AI.
Note:
The demo door lock is not stable, the mechanical part is not well designed. I shall upgrade this door lock later with full instructions. Generally the design is practical, the BBAI and Power cable shall be installed indoor, outside intruder can not break the electronic part without entering house. The square latch can be drive both by key or rotary servo from upper side or downward side. Malfunction of electronic part can not keep you out of house if you put the key in safe place.
Top Comments