


 | Enter Your Project for a chance to win an Oscilloscope Grand Prize Package for the Most Creative Vision Thing Project! | Project14 Home |
| Monthly Themes | ||
| Monthly Theme Poll |

The Artificial Neural Network that I want to use with the LDR camera and the BeagleBone AI is one derived from a book by H Pao. As it has been some time since I used this programme I thought it would be beneficial to refresh my memory of how it works. Fortunately I have a copy of the programme with will work in a Command window with Windows 10. I no longer have a copy of the Microsoft C compiler so I am not able to make any changes to this version. Hopefully I will be able to use a C compiler on the BeagleBone AI to make some updates. The consequence of this is that the programme, called SimonnV5 (SIMple Online Neural Network Version 5 - it's not online but I needed the O to make Simon) is limited to a maximum of 50 inputs. The LDR camera has 64 inputs so I cannot use it with compatible data examples. Therefore I will use a smaller array of 7x5 (rows x columns) with 0.1 representing nothing and 0.9 representing the presence of part of a letter. For this example I will only use two letters, A and T. The data for these letters that the ANN will use for training needs to be created, so A is
0.1 0.1 0.9 0.1 0.1
0.1 0.9 0.1 0.9 0.1
0.9 0.1 0.1 0.1 0.9
0.9 0.1 0.1 0.1 0.9
0.9 0.9 0.9 0.9 0.9
0.9 0.1 0.1 0.1 0.9
0.9 0.1 0.1 0.1 0.9
Hopefully the outline of the capital can be seen. The ANN does not need to know anything about the rows and columns and just treats the data as a serial string of 35 elements, so the 7x5 array is converted into a 1x35 string.
0.1 0.1 0.9 0.1 0.1 0.1 0.9 0.1 0.9 0.1 0.9 0.1 0.1 0.1 0.9 0.9 0.1 0.1 0.1 0.9 0.9 0.9 0.9 0.9 0.9 0.9 0.1 0.1 0.1 0.9 0.9 0.1 0.1 0.1 0.9
The output data now needs to be added to the end of each string where the position in the string will indicate whether it is A (element 36) or T (element 37) as listed below.
0.1 0.1 0.9 0.1 0.1 0.1 0.9 0.1 0.9 0.1 0.9 0.1 0.1 0.1 0.9 0.9 0.1 0.1 0.1 0.9 0.9 0.9 0.9 0.9 0.9 0.9 0.1 0.1 0.1 0.9 0.9 0.1 0.1 0.1 0.9 0.9 0.1
The same process is now repeated for the letter capital T and saved in a text file with the file extension .DAT to produce the complete input file of:
0.1 0.1 0.9 0.1 0.1 0.1 0.9 0.1 0.9 0.1 0.9 0.1 0.1 0.1 0.9 0.9 0.1 0.1 0.1 0.9 0.9 0.9 0.9 0.9 0.9 0.9 0.1 0.1 0.1 0.9 0.9 0.1 0.1 0.1 0.9 0.9 0.1
0.9 0.9 0.9 0.9 0.9 0.1 0.1 0.9 0.1 0.1 0.1 0.1 0.9 0.1 0.1 0.1 0.1 0.9 0.1 0.1 0.1 0.1 0.9 0.1 0.1 0.1 0.1 0.9 0.1 0.1 0.1 0.1 0.9 0.1 0.1 0.1 0.9
The SimonnV5 programme is now started and the file containing this data is entered so that training can begin. I cannot remember what system error and individual error parameters are so I will leave them unchanged. 1000 iterations should be enough for only two data sets.
I now need to identify the number of neurons in the input layer (one for each input), the number of neurons in the output (2), the number of hidden layers (1) and the number of neurons in the hidden layer (say 45). More than 1 hidden layer does not seem to improve the performance of this programme and as long as the number of neurons in the hidden layer is greater than the input layer, it seems to work.
The file containing the training data (E14AT.DAT) now needs to be entered. The programme assumes a file extension of .DAT.
The programme provides the option of reviewing the input data, which is always a good idea.
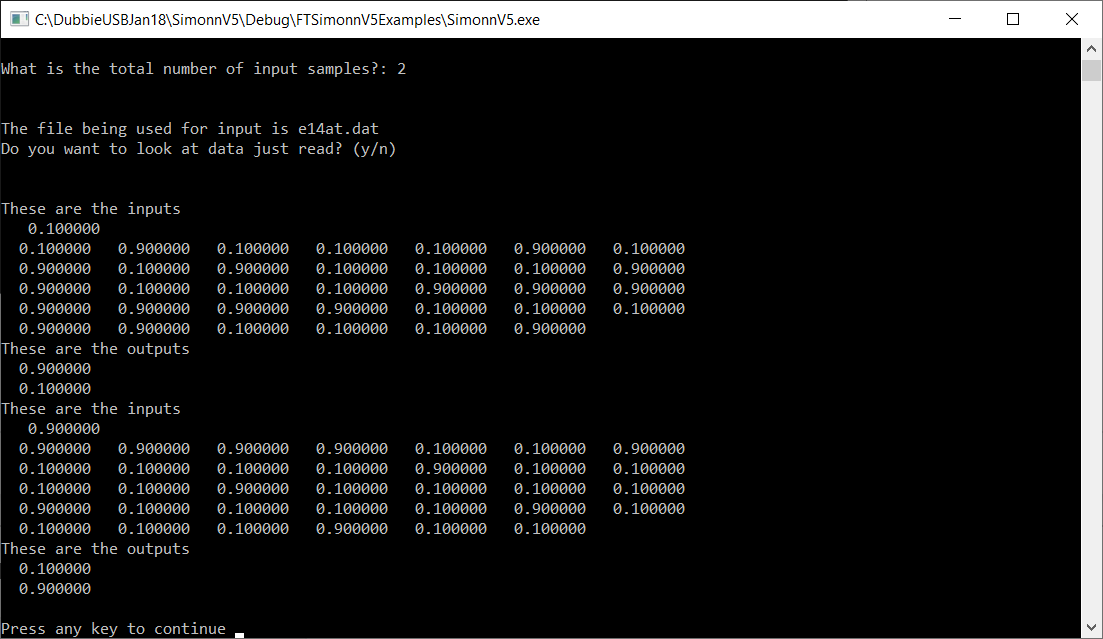
The programme will then train the ANN. This produces the following:
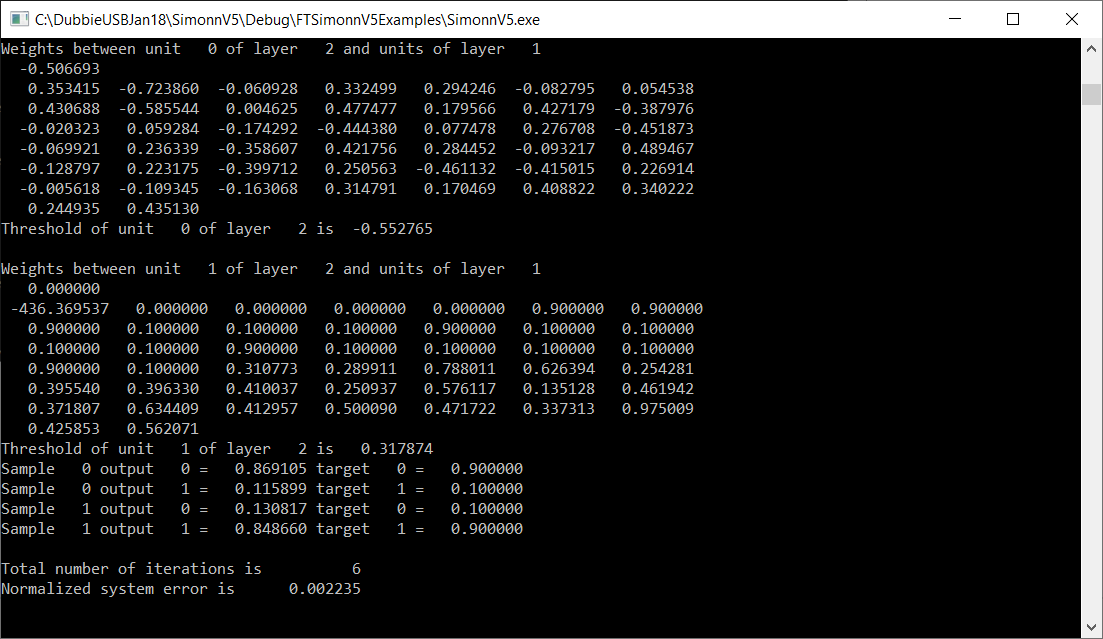
This particular data set has been chosen to be relatively easy to learn so only 6 iterations are required. For more letters of the alphabet then more iterations would be needed. There is no guarantee that the learning process will converge to a successful outcome, hence the limit on the number of iterations. Also, because the initial values when first training are randomised, no two successive trains will produce the same output and might not even train. This means that if a trained ANN is produce it is always a good idea to save it before training again as it might not be reproduced.
Now that a trained ANN has been produced it now needs to be verified as just because something has trained, it does not mean it is any good. As the only correct data available for two letters is the training data itself, then the same data will be used for verification.
This is not a particularly reliable approach but for this specific example there is no alternative.
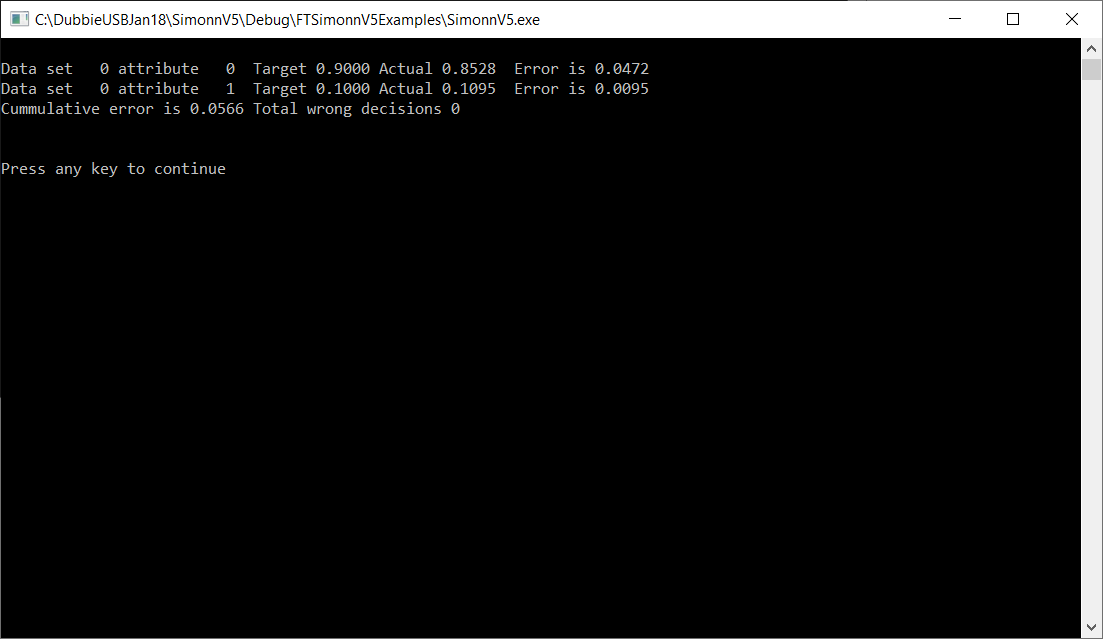
The first line (data set 0 attribute 0) is the letter A. The target output value was 0.9 and the output from the ANN is 0.8528, which is a difference (error) of 0.0472. This is about a 5% error which is pretty good for an ANN. The second line (Data set 0 attribute 1) is the letter T. This should not be recognised (target value of 0.1). The ANN output is 0.1095 which is about 10% error. Not as good as recognising the letter A but still pretty good. The next image is for the second letter, letter T.

These results are also pretty good and indicate that this seems to be a well trained ANN.
With ANNs it is difficult to be sure of whether the training is any good or not, so it would be usual to perform more testing to see how good the trained ANN is. For this example, the letter C has been added to the verification data, see below. The ANN has not been trained to recognise the letter C so it will attempt to predict whether it is a letter A or a letter T, as that is all it knows.
0.1 0.1 0.9 0.1 0.1 0.1 0.9 0.1 0.9 0.1 0.9 0.1 0.1 0.1 0.9 0.9 0.1 0.1 0.1 0.9 0.9 0.9 0.9 0.9 0.9 0.9 0.1 0.1 0.1 0.9 0.9 0.1 0.1 0.1 0.9 0.9 0.1
0.9 0.9 0.9 0.9 0.9 0.1 0.1 0.9 0.1 0.1 0.1 0.1 0.9 0.1 0.1 0.1 0.1 0.9 0.1 0.1 0.1 0.1 0.9 0.1 0.1 0.1 0.1 0.9 0.1 0.1 0.1 0.1 0.9 0.1 0.1 0.1 0.9
0.9 0.9 0.9 0.9 0.9 0.9 0.1 0.9 0.1 0.1 0.9 0.1 0.9 0.1 0.1 0.9 0.1 0.9 0.1 0.1 0.9 0.1 0.9 0.1 0.1 0.9 0.1 0.9 0.1 0.1 0.9 0.9 0.9 0.9 0.9 0.1 0.1
These image below shows just the result of verifying the trained ANN with the unknown letter C. It should indicate that it is neither A or T. It sort of does. It 'thinks that it is 0.2091 for letter A which is not too bad, but it thinks it is 0.7054 for letter T which is much too high a value. This tends to indicate that this ANN is not particularly good for recognising unknown letters.
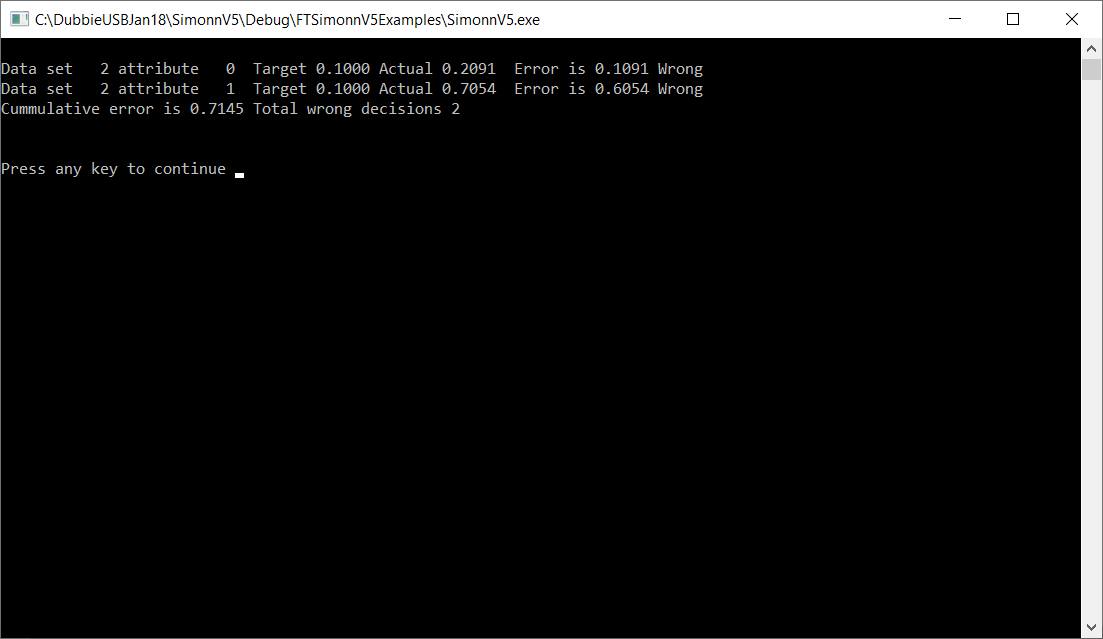
So in summary, I am making progress in the ANN part of my LDR camera. The two remaining steps will be to get the ANN C programme transferred to the BBAI and compiled and then somehow get the LDR image data from the Arduino Nao system into the BBAI. I think I'll try getting the ANN C programme into the BBAI first.
Dubbie