


Artificial Intelligence III: Inference for Machine Learning
Sponsored by

We have all seen films where humankind implements an artificial intelligence (AI) system, something goes wrong, and it turns against its creators. 2001: A Space Odyssey and the Terminator films are classic examples. But what is artificial intelligence, really, and how do we use it in our applications, especially at the edge?
When it comes to working with artificial intelligence, we really are standing on the shoulders of giants. The term AI itself was first used by John McCarthy in 1956, when the earliest conference on artificial intelligence was held. Even before the AI term had been coined, however, there was considerable research being undertaken on the question of whether or not machines think. One early leading researcher was Alan Turing, the Bletchley Park code breaker, who posed the Turing Test. The test revolves around the question of whether we will ever be able to build a computer that can sufficiently imitate a human, to the point where a suspicious judge can't tell the difference between what is human and what is machine.
AI research has been a hot topic over the years. The late 1990s saw IBM's Deep Blue supercomputer beat chess grandmasters. More recently, we have seen significant interest in artificial intelligence and machine learning at the edge, deployed within embedded systems.
But what is machine learning? According to the book Machine Learning by Tom M. Mitchell, Professor at Carnegie Mellon University, "Machine learning is the study of computer algorithms that allow computer programs to automatically improve through experience."
A simple example of this is providing a machine learning algorithm with a data set of pictures with labels. The machine learning (ML) algorithm will be able to identify features and elements of the pictures, so that when a new unlabeled picture is input, the ML algorithm is able to determine how likely the image is to contain any of the learned features and elements. The classic example of this is the machine learning algorithm being able to identify pictures of animals, fruits, and so on.
These machine learning algorithms can, therefore, be said to have two distinct elements: training and inference. Training is process in which the features and elements that need to be identified are learned, while inference is using the trained behavior to examine unlabeled inputs to identify the elements and features once deployed.
2. Objectives
This Essentials learning module will introduce you to the basics of artificial intelligence (AI) and machine learning (ML) inference. The learning objectives are as follows:
 Gain an understanding of inference and its role in AI and ML systems.
Gain an understanding of inference and its role in AI and ML systems.
Learn about neural networks and what they consist of.
Become familiar with the different network types that can be used for AI inference.
See examples of different methodologies and frameworks which can be used for creation, training, and inference of AI and ML.
At the heart of the machine learning inference implementation is the neural network. This neural network is instantiated and trained to provide the required behaviour. Training can be very compute intensive, as large data sets are used to train the network. As such, the training most often takes place using a high-performance GPU unit rather than the deployed end solution. This enables much faster training of the network than would be achieved if the deployed system was used alone.
The term neural network is very generic, and includes a significant number of distinct subcategories whose names are normally used to identify the exact type of network being implemented. Neural networks are modeled upon the human cerebral cortex, in that each neuron receives an input, processes it, and communicates the processed signal to another neuron. Therefore, neural networks typically consist of an input layer, internal layer(s), and an output layer.
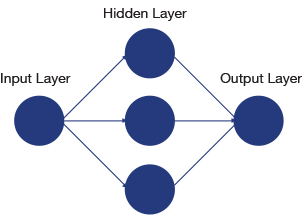
Figure 1: A Simple Neural Network
There are several classes of neural networks, with different classes used for different applications (e.g. speech recognition or image classification). Neural networks which pass the output of one layer to another without forming a cycle are called Feedforward Neural Networks (FNNs). Those which contain directed cycles where there is feedback, for example the Elman network, are called Recurrent Neural Networks (RNNs). One very commonly used term in many machine learning applications is Deep Neural Networks (DNNs). These are neural networks which have several hidden layers enabling a more complex machine learning task to be implemented.
- 3.1 Network Types
The structure of the neural network, the number of stages, and which types of elements are used has been, and indeed continues to be, the subject of considerable research to obtain the best performance. Common network structures have evolved. Convolutional Neural Networks (CNNs), for example, are a type of feedforward neural network. Long Short-Term Memory (LSTM) is a type of Recurrent Neural Network. CNNs are exceedingly popular for image classification, while LSTM is a popular network for Natural Language Processing (NLP).
Commonly used CNN network structures include:
AlexNet: Invented by Alex Krizhevsky as part of his PhD Studies. AlexNet is an 8-layer deep network which completed the ImageNet Large Scale Visual Recognition Challenge in 2012.
GoogLeNet: A 22-layer CNN first described in 2014 by Google.
VGG-16: A 16-layer CNN described by the Visual Geometry Group at the University of Oxford in 2014.
- 3.2 Convolutional Neural Networks
What separates embedded vision applications from other, simpler machine learning applications is that they have a two-dimensional input format. As such, in machine learning implementations, a Convolutional Neural Network is used, as it can process two-dimensional inputs. As outlined above, several different CNN implementations exist which have evolved over the years. However, they consist of multiple stages of the same basic functional blocks, with different parameterizations throughout the implementation. These stages are:
Convolution: In this stage, the input image is broken down into several overlapping smaller tiles by the application of a filter. The results from this convolution are used to create a feature map.
Rectified Linear Unit (reLU): This activation layer is used to create an activation map following a convolution.
Max Pooling: Performs subsampling between layers to reduce resolution.
Fully Connected: This is a matrix multiplication layer which applies both weights and a bias to the input. It is called a fully connected layer because the input and output are fully connected.
These networks and stages are defined and trained within an ML framework. The ML framework provides not only a range of libraries, but also pre-existing network models thanks to its Model Zoo, and pre-trained weights that are applied to the model to quickly get networks up and running. Training is required to define the parameters for the convolution (filter weights) and fully connected layers (weights and bias), while the pool and reLU elements require no parameterization. Both the pool and convolution layers, however, require parameterization to define the size of the filter kernel and the stride. How we determine the values which are used for these is called training. One of the advantages of using a CNN is the relative ease of training the network.
Of course, machine learning inference is a complex area, and starting from scratch could be daunting. However, several frameworks exist which enable us to get started creating our solution. Here are some of the most commonly used frameworks:
TensorFlow: Developed by the Google Brain Team and first released publicly in 2015, TensorFlow provides both Python and C APIs.
Caffe: This convolutional architecture for fast-feature embedding was developed by the University of California at Berkley. Caffe supports both C and Python.
PyTorch: A Python implementation of torch primarily developed by the FaceBook AI research group.
tinyML: TensorFlow Lite, developed to enable ML implementations on Arm Cortex-M class devices, ESP32 devices, and other edge processors.
These frameworks provide everything required to instantiate a network, train the network, and deploy the network on the target device.
The training of a network requires a large data set consisting of many thousands of correct and incorrect sources.
There are three types of training routinely used for an ML network:
Supervised Training: A tagged data set is used. The network iteratively makes output predictions based on the tagged input data. These output predictions are corrected by a supervisor based upon the tag data, meaning that when untagged data is input, the output prediction is correct within an accuracy. Supervised training is used for the majority of neural networks.
Unsupervised Training: Untagged data sources are used. These are used for neural network implementations with no correct answer (e.g. clustering and association).
Reinforcement Learning: Uses the interaction with the network's environment to maximize the notion of cumulative reward.
When structured training is performed, an additional layer is introduced, called the loss function. This stage enables the training algorithm to know if the network correctly identified the input image. During training, both forward and backward propagation is used to determine if the image is correctly classified, and updates are made to the weights and biases based on the error signals and calculated gradients. To apply the image sets and calculate the network coefficients as quickly and as efficiently as possible, large farms of Graphical Processing Units (GPUs) are used. GPU farms are used because the goal of training is to generate the weights and biases within the minimal time frame. Therefore, power efficiency, real-time response, and determinism for each image frame is not as critical as it is within the final inference deployment. Therefore, GPU farms provide the most efficient mechanism for determining weights and biases.
While the training and creation of an ML solution will take place using GPU farms, the ML inference application will be deployed on many different edge technologies, such as the following examples.
Edge-Based Applications
CPU: General-purpose CPUs, such as Arm-based microcontrollers like the Arm Cortex-M3 processor
GPU: Graphics Processor Units, such as the Nvidia System-on-Module
FPGA: Field Programmable Gate Array, such as Xilinx heterogeneous SoCs and MPSoCs like the Zynq-7000 or the Zynq UltraScale+ MPSoC
Cloud-Based Applications
High Performance CPU: x86 or Arm-based higher performance server processor
Graphics Cards: High-performance graphics co-processors
Acceleration Card: FPGA-based acceleration cards connected to the x86 server hardware using PCIe
Each end implementation technology will have different deployment needs. This is where technology-specific tool chains are used for the deployment. Examples of this include the Vitis AI tool from Xilinx or the TensorFlow Lite converter.
One large deciding factor in this situation is the capability of the underlying hardware. For example, many neural networks are defined and trained as floating-point implementations. However, at the edge, fixed-point representation may make for easier and more efficient implementations. Using fixed point may also enable the use of lower-cost hardware. Even in the cloud, FP32 implementation may still provide a faster, more powerful, and efficient implementation.
Machine learning applications are increasingly using more efficient, reduced precision, fixed-point number systems such as INT8 representation. The use of fixed-point reduced precision number systems comes without a significant loss in accuracy, when compared to a traditional floating point 32 (FP32) approach. However, fixed-point mathematics is considerably easier to implement than floating point. This move to INT8 provides for more efficient, faster solutions in some implementations. To support this generation of reduced precision number systems, the automated Ristretto tool for Caffe enables the training of networks using fixed-point number systems. This removes the need (and associated potential performance impact) of converting floating-point training data into fixed-point training data.
If you are targeting a Xilinx programmable logic device, the Vitis AI tool also provides several tools which support implementation of models in programmable logic.
AI Optimizer: Optimizes the floating-point model to reduce model complexity
AI Quantizer: Quantizes the floating-point model weights and biases into an INT8 representation
AI Compiler: Compiles the quantized model to be deployed on the Xilinx Deep Learning Processor Unit (DPU)
Using Vitis AI, networks defined within Caffe, TensorFlow, and PyTorch can be deployed on programmable logic solutions. This allows AI developers to leverage the benefits which come with implementation of a solution in programmable logic.
Edge-based ML applications are increasingly growing in popularity. Typical examples include use in both the industrial and automotive solutions spaces.
Within the automotive space, ML can be used for several different solutions. One implementation is in road sign recognition and classification, as part of an Advanced Driver Assistance program. Another application is internal cabin monitoring, where the behavior of the occupants is used to set up environmental conditions.
When ML is deployed at the edge, one of the main aspects of its use for industrial applications can be predictive maintenance, where sensors and data are used to predict the failure or wear out of materials ending their lifecycle.
Embedded systems at the edge are increasingly deployed using machine learning algorithms to enable intelligent processing. Throughout this Essentials course, we have examined the history of AI and ML, neural networks, network types, frameworks, training, and deployment at the edge. Now, all that is left is for you to try creating your first ML application!
*Trademark. Xilinx is a trademark of Xilinx Inc. Other logos, product and/or company names may be trademarks of their respective owners.

Shop our wide range of components, development boards, and evaluation kits used for artificial intelligence and machine learning solutions.
Test Your KnowledgeBack to Top

Are you ready to demonstrate your knowledge of Inference for Machine Learning? Then take this 15-question quiz to see how much you've learned. To earn the AI III Badge, read through the learning module, score 100% on the Quiz, leave us some feedback in the comments section, and give the learning module a star rating.
| AI3.pdf |

Top Comments