

Introduction
High-performance computing, enterprise, and consumer applications demand superior efficiency, higher bandwidth, excellent processing, outstanding scalability, and compact integrated ICs. Other essentials include sparse latency storage, and superior performance computes that surpass traditional technologies.
System designers, to satisfy such exacting bandwidth applications market requirements, must plan support for800GE, 112G Direct Attach Cable, 400G ZR, Flex Ethernet (FlexE), and other emerging interface standards. Video streaming services fueled bandwidth demand and supplemented by full customer acceptance of several always-connected IoT devices per subscriber and smart infrastructure. Cloud services continue to gain traction.
Fluctuations in semiconductor process frequency scaling have pushed the standard computing element to become progressively parallel. The semiconductor industry continues to explore alternate domain-specific architectures, including those previously consigned to vector-based processes (DSPs, GPUs), fully parallel programmable hardware (FPGAs), and other discrete extreme performance segments.
How Xilinx meets the demands
Xilinx, a player in computationally intensive applications, introduced a new class of devices to meet contemporary challenges. The Adaptive Compute Acceleration Platform (ACAP) provides breakthrough performance computes, connectivity, and security on an adaptable platform with minimal power and area footprint. ACAP allows users to focus on their unique core competencies and novel algorithms, rather than designing connectivity and memory infrastructure, to achieve the earliest possible time to market.
Versal devices, combine adaptable and scalar processing intelligent engines (AI and DSP) with programmable logic and configurable connectivity. It enables customized, complex hardware solutions for a wide variety of applications in Data Center, Automotive, 5G wireless, Wired, and Defense. It provides superior performance/watt over conventional FPGAs, CPUs, and GPUs. Xilinx's signature Vitis unified software platform enables embedded software development and cloud-accelerated applications on Versal ACAPs. It provides a unified programming model for accelerating edge, cloud, and high-performance computing applications.
devices, combine adaptable and scalar processing intelligent engines (AI and DSP) with programmable logic and configurable connectivity. It enables customized, complex hardware solutions for a wide variety of applications in Data Center, Automotive, 5G wireless, Wired, and Defense. It provides superior performance/watt over conventional FPGAs, CPUs, and GPUs. Xilinx's signature Vitis unified software platform enables embedded software development and cloud-accelerated applications on Versal ACAPs. It provides a unified programming model for accelerating edge, cloud, and high-performance computing applications.
As shown in figure 1, ACAPs features a combo of next-generation Scalar Engines, Adaptable Engines, and Intelligent Engines, also known as Arm processor subsystem (PS), programmable logic (PL), and AI Engines respectively. Each offers different computation capabilities to satisfy distinct components that make up the complete system. The Scalar Engines are built with three processor types available for diverse application needs. The application processing unit (Dual-core Arm Cortex-A72) is ideal for complex applications supported by an OS, and the real-time processing unit (Dual-core Arm Cortex-R5) is best for latency-sensitive applications.
processor subsystem (PS), programmable logic (PL), and AI Engines respectively. Each offers different computation capabilities to satisfy distinct components that make up the complete system. The Scalar Engines are built with three processor types available for diverse application needs. The application processing unit (Dual-core Arm Cortex-A72) is ideal for complex applications supported by an OS, and the real-time processing unit (Dual-core Arm Cortex-R5) is best for latency-sensitive applications.
A separate platform management controller manages system boot, security, and debug. It comes with a wide variety of memory elements and tightly coupled with programmable I/O. The Arm processor is typically used for control-plane applications, operating systems, communications interfaces, and lower level or complicated computations.
The Adaptable Engines made of PL and memory cells allow users to create powerful accelerators for any application. This is key to optimizing for latency and power at the edge and for perfecting absolute performance in the core.PL performs data manipulation and transport, non-vector-based computation, and interfacing.

Figure 1: Versal Architecture Overview
The Intelligent Engines are an array of innovative Very Long Instruction Word (VLIW) and Single Instruction Multiple Data (SIMD) processing engines and memories, all interconnected with 100's of terabits per second of interconnect and memory bandwidth. These permits 5x–10x performance improvement for machine learning and DSP applications. An AI Engine is typically used for compute-intensive functions in vector implementations. Using the ACAP features like vector, scalar, and adaptable hardware elements, Xilinx offers advantages over software programmability, Heterogeneous acceleration, and adaptability.
ACAP's for any Application from Cloud to Edge
Application requirements determine Versal devices classification. AI Engines are present in three multi-members' AI-series (Versal AI Edge, Versal AI Core, and Versal AI RF) and excluded from three non-AI, multi-member series of devices (Versal Prime, Versal Premium, and Versal HBM). Xilinx currently supports the AI Core series, Premium series, and Prime series. The AI Edge, AI RF series, and HBM series are considered for future roadmaps.
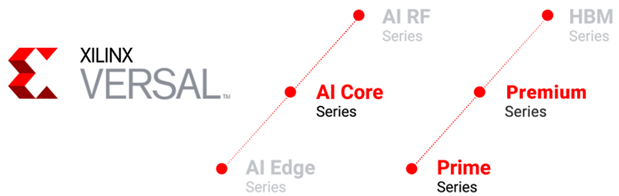
Figure 2: Versal portfolio of devices
Versal AI Core series delivers trailblazing AI inference and wireless acceleration with integrated AI engines pumping over 100x greater compute performance than today's server-class CPU's. Data Center and Wireless applications using maximum intelligent engine compute are primary markets for these series.
The Versal Prime series offers a diverse set of compute engines, next-generation I/O, and integrated DDR controllers, enabling low latency acceleration spanning different workloads suited for Data Center and Wired applications.
Versal Premium series provides the highest bandwidth and compute density on an adaptable platform from Network to Cloud. It is an integration of Networked IP on a Power-Optimized platform built on a foundation of architectural elements leveraged from the Versal AI Core and Versal Prime series. Wired and Test & Measurement are target application segment for such series. The following table summarizes the differentiated features of these three Versal devices.
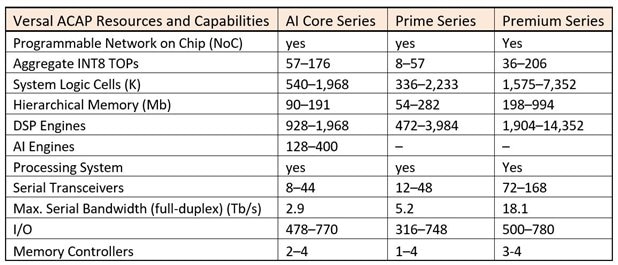
Table 1: Xilinx Versal ACAP Series
AI Engines
AI Engines consolidated with Xilinx's Adaptable Engines (PL), and Scalar Engines (PS) forms a tightly integrated heterogeneous compute platform. AI Engines provide up to five times higher compute density for vector-based algorithms. They are optimized for DSP, satisfying both throughput and compute requirements to deliver the high bandwidth and accelerated speed needed for wireless connectivity. It also reduces power consumption by a whopping 50% when compared to similar functions performed in PL.

Figure 3: AI Engine Array
The AI Engine array is two-dimensional arrays of AI Engine tiles. They are located on the north edge of a Versal AI Core device. Each AI Engine tile includes vector processors for both fixed and floating-point operations, a scalar processor, dedicated program and data memory, dedicated AXI data movement channels, support for DMA and locks, and debug.
Each AI Engine tile contains a 32KB data memory divided into eight single-port banks with each port bank 256-bit wide and 128 deep. AI Engines are a SIMD and VLIW, providing up to 6-way instruction parallelism, including two/three scalar operations, two vector load, and one write operation, and one fixed or floating-point vector operation, for every clock cycle. The AI Engine array, optimized for real-time DSP and AI/ML computation, provides deterministic timing via a combination of static dedicated data and instruction memories, eliminating inconsistencies that may arise from cache misses and associated fills.
Network on Chip (NoC)
The programmable NoC is an AXI-4 based interconnect network within the Versal ACAP architecture enabling high-bandwidth connections to be easily routed around the device. The NoC extends in both horizontal and vertical directions to the device edges. It connects device areas that demand and use vast quantities of data reducing any resource burden on the local and regional device interconnect. The NoC is a full blocking crossbar between memory controllers, PL, PS, AI Engines, and PMC.
A few examples of NoC connections include Sharing device access to DRAM, PL to PL connections, and memory-mapped access to the AI Engine array. In devices built using stacked silicon interconnect (SSI) technology, the vertical NoC columns connect between the adjacent super logic regions (SLRs), sanctioning device configuration data to travel between master and slave SLRs.
Platform Management Controller (PMC)
The PMC manages the Versal ACAP in two ways: it securely boots and configures the platform and life-cycle management. The latter includes device integrity and debug and system monitoring. The PMC is responsible for booting the Versal ACAP from the primary boot source in a multi-stage boot process that supports both a non-secure and a secure boot. The PMC also configures the PL, which can be set before or after the PS. It also controls the platform's encryption, authentication, system monitoring, and device debug capabilities.
The PMC encapsulates system monitoring capability for monitoring voltage and temperature in the PS and PL to enhance the system's overall safety, security, and reliability. The PMC also contains a high-speed debug port that can be used as a faster debug method than the primary JTAG interface.
Digital Signal Processing (DSP)
DSP applications use several binary multipliers and accumulators, best implemented in dedicated DSP Engines. Each DSP Engine fundamentally consists of a dedicated 27 × 24 bit two's complement multiplier and a 58-bit accumulator. The multiplier can be dynamically bypassed, and two 58-bit inputs can feed a SIMD arithmetic unit (dual 24-bit or quad 12-bit add/subtract/accumulate), or a logic unit that can generate any one of ten different logic functions of the two operands. The DSP Engine includes an additional pre-adder, typically used in symmetrical filters. It also contains a 58-bit-wide pattern detector that can be used for convergent or symmetric rounding. The pattern detector can implement 116-bit-wide logic functions when used in conjunction with the logic unit.
The DSP Engine provides extensive pipelining and extension capabilities that enhance the speed and efficiency of several applications beyond DSP, like wide dynamic bus shifters, memory address generators, wide bus multiplexers, and memory-mapped I/O register files. The accumulator may also be used as a synchronous up/down counter.
| Versal AI Core Series VCK190 Evaluation Kit |
|---|
|
For more Information: https://www.xilinx.com/products/boards-and-kits/vck190.html |

Application benefits and implementation of ACAP devices
Xilinx provides a flexible, standards-based solution that combines software programmability, workload optimization, and high-performance data center interconnect with the security needed for the next generation of cloud computing.
Data centers must be workload-optimized to swiftly adapt to changing throughput, latency, and power requirements from a wide range of virtualized on-demand software applications. These applications include machine learning, video transcoding, image and speech recognition, and high-performance connectivity.
AI Engines have been optimized for compute-intensive applications, specifically DSP and some AI technology like ML and 5G wireless apps.
Real-time DSP finds extensive use in wireless communications. Xilinx compared implementations of classic narrow-band and wide-band radio design principles, massive MIMO, and baseband and digital front-end concepts, validating the AI Engine architecture as being ideally-suited to building radio solutions. For example, a 100MHz 5-channel LTE20 wireless was implemented in a Versal device part.
For 5G, Xilinx technology helps to solve capacity, connectivity, and performance challenges. It also provides the flexibility to support multiple standards, multiple bands, and the various sub-networks that enable diverse IoT driven applications of 5G.
Summary:
AI Engines represent a new class of high-performance computing. The AI Engine, integrated within a Versal-class device, can be optimally combined with PL and PS to implement high-complexity systems in a single Xilinx ACAP. AI Engines deliver three to eight times better silicon area compute density when compared with traditional programmable logic DSP and ML implementations while reducing power consumption by 50%.
For metro and core network and leading-edge compute acceleration applications, Versal Premium ACAPs offer breakthrough integration of networked, power-optimized IP cores on a platform that adapts to new standards and algorithms. This platform brings superior performance to compute fabric immediately adjacent up to 1Gb of on-chip SRAM accessible at rates up to 123TB/s for next-generation compute applications.