


Tech Spotlight Summer of FPGAs:
Main Agenda | Xilinx | Tech Connection | FPGA Group | Related Poll | Participate in the Discussion
sponsored by

Introduction
As technology advances and hardware becomes increasingly intelligent, more and more applications are being deployed at the edge and endpoint. Armed with cameras and radar, cars are learning to drive themselves. Cities are getting smarter, with machines that sense when help is needed. Factory automation has evolved, from the brainless robot arms of the past to safer, more efficient AI-powered machines. While the preceding examples span a wide variety of industries, the goals are the same in each. Safety and reliability are primary concerns, as are low-power consumption and small form factors. As the successes in edge computing implementations add up, so does demand: demand for more functionality, more intelligence, and more performance. This is where adaptive computing is revolutionizing today’s compute-intensive and latency-sensitive workloads, spanning networking, video, data analytics, and more. In this article, we will explore adaptive computing.
Defining Adaptive Computing
Adaptive computing has emerged as a game changing technology in the development of AI-enabled edge applications. Adaptive computing is a term covering any silicon hardware than can be highly optimized for specific applications. Field Programmable Gate Arrays (FPGAs) are the backbone of most adaptive computing hardware because of their ability to be configured and reconfigured. In addition to FPGAs, programmable Systems-on-Chip (SoCs) have also been introduced. Built on an FPGA fabric, FPGA-based SoCs have one or more CPU subsystems embedded into the chip.
A recent innovation in adaptive computing is the introduction of the AI Engine from Xilinx. An AI Engine is fundamentally a configurable block that can be programmed like a CPU. Instead of being built on FPGA processing hardware, an AI Engine contains high performance scalar and single instruction multiple data (SIMD) processors, optimized for math-intensive algorithms, similar to the algorithms required for AI and wireless communication applications. Figure 1 illustrates an AI Engine array.
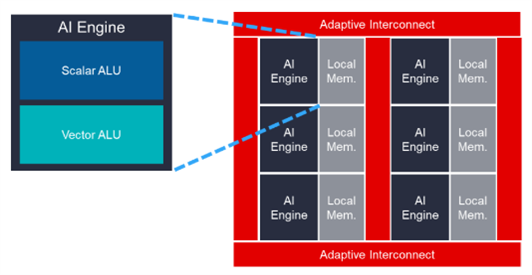
Figure 1: State-of-the-art adaptive hardware – an AI Engine Array (Image source: Xilinx)
Included under the adaptive computing umbrella is the design and runtime software that, when combined with the hardware, gives designers the potential for building intelligent edge applications.
Adaptive computing empowers a new generation of intelligent, efficient applications. These applications vary widely, from latency-sensitive applications, such as autonomous driving and real-time streaming video, to high-complexity applications, such as 5G signal processing, and the data processing of unstructured databases. Adaptive computing is deployed in the cloud, on the network, at the edge, and even at the endpoint, bringing the latest architectural innovations in discrete and end-to-end applications.
Comparison with Other Technologies
Edge computing applications have their own set of requirements. Because many edge computing devices run on batteries, low power consumption is critical. Additionally, many devices need to be portable, and therefore a small form factor is paramount. As more and more processing shifts from servers to the edge, demand for processing power increases, prompting new designs and technology to deliver the performance levels required.
Xilinx Products
Shop our wide variety of products by Xilinx including, FPGAs, SoCs, MIPSoCs, and 3D ICs.
Don't forget to take our poll.
CPUs offer immense flexibility because they are software programmable; however, the underlying hardware cannot be changed once manufactured. Algorithmic Logic Units, or ALUs, are the components in CPUs that handle processing, and they are capable of processing almost everything the software tells them to. Modern CPUs can have 32 or more arithmetic logic units (ALUs), but, fundamentally, each one operates in sequential fashion, being limited to one instruction at a time.
To better suit the requirements of an edge computing application, a domain specific architecture (DSA) is generally preferred. A DSA is a specific architecture, built especially for the application in question, closely matching compute, memory, bandwidth, data-paths, and I/O to the specific requirements of the domain. In many applications, a DSA delivers significantly higher efficiency than a general purpose CPU.
An ASIC is an example of hardware built and optimized for a specific application, and thus can be considered a DSA. Because ASICs are designed for specific applications, they are able to deliver high efficiency and performance; however, ASICs have two primary disadvantages: the speed of innovation and the cost of development. In these times, innovation occurs at breakneck speeds and manufacturers are expected to keep pace. The time it takes to design and build a fixed silicon DSA, like an ASIC, slows the process and puts manufacturers at a disadvantage. Additionally, designing and manufacturing custom silicon is extremely expensive and projected to become even more so, as device geometries sink to 5nm and below.
The advantages of using adaptive computing include reduced time-to-market, reduced operating costs, flexible and dynamic workloads, future-proofed systems, software programmability, acceleration, and dynamically adaptable reconfiguration.
Adaptive Computing for the Developer
Versal ACAP
Versal ACAPs (Adaptive Compute Acceleration Platforms) combine Scalar, Adaptable, and Intelligent Engines with leading-edge memory and interfacing technologies to deliver efficient computing power for any application. They offer a host of tools, software, libraries, IP, middleware, and frameworks to support industry-standard design flows. The Versal portfolio is the first platform to combine software programmability and domain-specific hardware acceleration with significant adaptability.
ACAPs (Adaptive Compute Acceleration Platforms) combine Scalar, Adaptable, and Intelligent Engines with leading-edge memory and interfacing technologies to deliver efficient computing power for any application. They offer a host of tools, software, libraries, IP, middleware, and frameworks to support industry-standard design flows. The Versal portfolio is the first platform to combine software programmability and domain-specific hardware acceleration with significant adaptability.
The ACAP portfolio includes six series of devices designed to deliver scalability and AI inference capabilities for a variety of applications, including cloud computing, networking, wireless communications, and edge computing and endpoints.
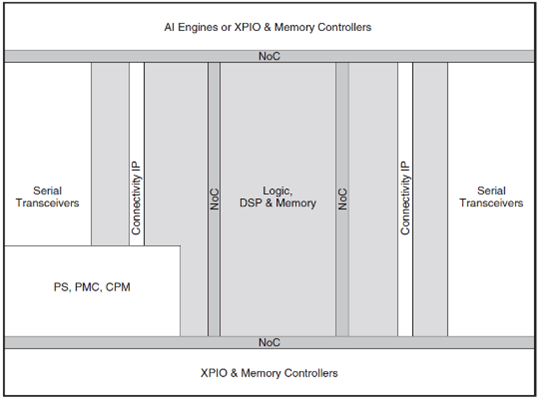
Figure 2: Versal ACAP Device Layout (Image source: Xilinx)
As shown in Figure 2, Versal ACAPs consist of a programmable network on chip (NoC), enabling memory-mapped access to the full height and width of the device. An ACAP is comprised of a multi-core scalar processing system (PS), an integrated block for PCIe with DMA and Cache Coherent Interconnect Designs (CPM), SIMD VLIW AI Engine accelerators for AI and complex signal processing, and Adaptable Engines in the programmable logic (PL). Scalar Engines, including Arm Cortex-A72 and Cortex-R5F processors, support compute-intensive tasks.
with DMA and Cache Coherent Interconnect Designs (CPM), SIMD VLIW AI Engine accelerators for AI and complex signal processing, and Adaptable Engines in the programmable logic (PL). Scalar Engines, including Arm Cortex-A72 and Cortex-R5F processors, support compute-intensive tasks.
The platform management controller (PMC), adjacent to the PS, is responsible for booting and configuring the device. Referencing Figure 2, Versal devices typically have I/O and memory controllers on the north and south edges of the device and serial transceivers on the east and west edges. The south edge of Versal ACAPs generally contains numerous XPIO banks and associated memory controllers to read from and write to DDR4 and LPDDR4 memory. The east and west edges of the device commonly contain serial transceivers capable of communicating at up to 112Gb/s.
Vitis Unified Software Platform
The Vitis unified software platform enables the development of embedded software and accelerated applications on Xilinx FPGAs, SoCs, and Versal ACAPs. It provides a single programming model for accelerating edge, cloud, and hybrid computing applications. The Vitis AI development environment is a specialized development environment for accelerating AI inference on Xilinx embedded platforms, Alveo accelerator cards, or on the FPGA instances in the cloud.
As shown in Figure 3, the Vitis AI Development Environment, Vitis Accelerated Libraries, Vitis Core Development Kit, Xilinx Runtime library, and Vitis Model Composer are the platform's key components. It is designed for efficiency and ease of use, allowing for AI acceleration on Xilinx FPGAs and ACAPs. The Xilinx Runtime library (XRT) facilitates communication between application code and the accelerators deployed on the reconfigurable portion of PCIe-based Xilinx accelerator cards, MPSoC-based embedded platforms, or ACAPs.
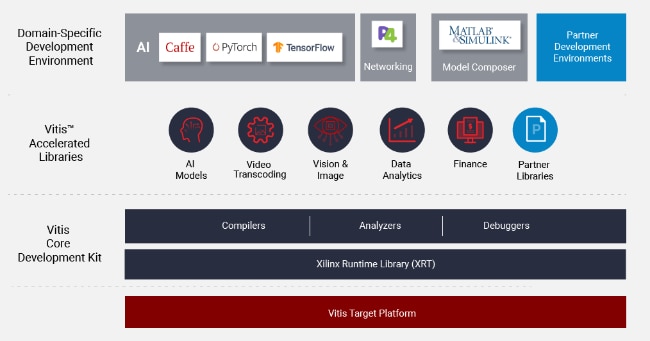
Figure 3: The Vitis Unified Software Platform (Image source: Xilinx)
The Vitis AI development environment supports deep learning frameworks like Tensorflow and Caffe, and offers comprehensive APIs to prune, quantize, optimize, and compile the trained networks to achieve the highest AI inference performance for the deployed application. The Vitis Core Development Kit is a complete set of graphical and command-line developer tools that includes the Vitis compilers, analyzers, and debuggers to build, analyze performance bottlenecks, and debug accelerated algorithms developed in C, C++, or OpenCL.
Applications
Adaptive computing is well-suited for edge computing applications, including (a) accelerating tasks at data centers, (b) image and video processing, and (c) AI processing for devices at the edge. What follows are example applications that adaptive computing might benefit:
Automotive Smart Forward-Looking Camera (Edge Compute)
Smart forward-looking cameras support many applications in the automotive world, including autonomous driving, adaptive cruise control (ACC), lane departure warning (LDW), automated emergency braking (AEB), traffic sign recognition (TSR), and traffic jam assistant (TJA), among others.
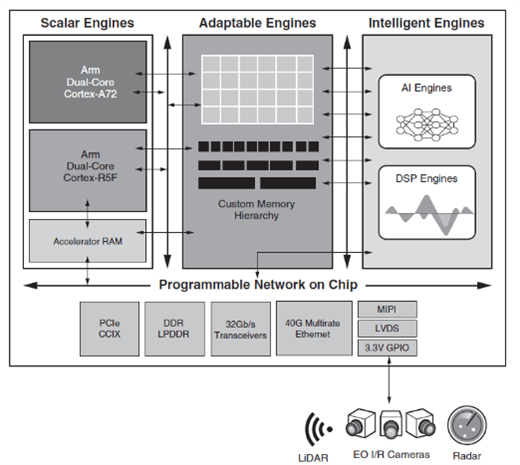
Figure 4: Forward-Looking Camera Versal AI Edge Architecture (Image source: Xilinx)
Figure 4 illustrates a typical architecture and functional partitioning for an AI Edge ACAP-based forward-looking camera platform. Vision data from cameras can be combined with data from other forward-looking devices, such as LiDAR or Radar, enabling object detection and AI functions for classification to be accelerated in the ACAP’s Adaptable and Intelligent Engine domains.
Xilinx Versal-based 5G Beamforming Solution
5G makes use of beamforming, a technique which utilizes an antenna array to steer signals in a specific direction, enabling multiple data streams to be transmitted simultaneously to different users employing the same spectrum. 5G wireless communication systems have enhanced multiple-input-multiple-output (MIMO) technology through several antennas for higher spectral efficiency. Massive MIMO requires adaptable, optimized partitioning and integration of complex digital and RF signal processing functions.
With its larger number of antennas, the complexity of 5G MIMO beamforming systems can be as high as 320 times that of a 4G LTE system. Supporting this added complexity are the hundreds of AI Engine tiles in the Versal engine core, each designed for intensive computing in various applications, including 5G. Each AI Engine tile consists of one AI Engine, 32KB data memory, and two DMA engines for automatic data transportation. The vector processor in every AI Engine is capable of 32 16 bit multiply-and accumulate (MAC) operations in one clock cycle. It is shown that 100 MHz 64-antenna 32-layer 5G NR beamforming can be implemented on 64 AI Engines with three kernels, while a similar solution implemented on programmable logic would require 2048 DSP58 blocks and hundreds of thousands of LUTs and FFs.
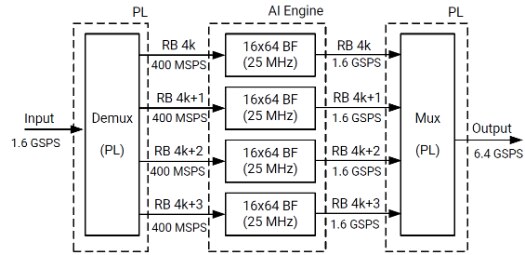
Figure 5 shows an example of a 5G NR Beamformer implemented with an AI Engine.
Figure 5: 5G NR 100 MHz Beamformer Using Four 25 MHz Beamforming Units (Image source: Xilinx)
Conclusion
Adaptive computing builds on existing FPGA technology and makes it available to a diverse range of developers and applications. This adaptability makes it uniquely different from fixed hardware architecture CPUs and ASICs. The benefits of deploying adaptive platforms in production systems include reduced time-to-market, reduced operating costs, and an innate future-proofing of the system.
Examples of Adaptive Computing Products and Development Tools
| Versal Prime Series VMK180 Evaluation Kit | Versal Prime Series VMK180 Evaluation Kit | VCK5000 Versal Development Card for AI Inference | Debugger / Programmer, Versal ACAP |
|---|---|---|---|
|
EK-VCK190-G-ED |
EK-VMK180-G-ED |
VCK5000-AIE-ADK |
HW-SMARTLYNQ-G Newark/FarnellNewark/Farnell |




