

Take the Poll | Join our Discussion
sponsored by

Understanding Human Speech
Advancements in artificial intelligence (AI) have enabled the development of completely new classes of software and devices. In many cases, AI-enabled devices are no longer dependent on humans; they are able to classify data and even make decisions on their own. While AI-enabled Computer Vision applications have gotten a great deal of attention, algorithms that process voice and sound have also made great strides in efficiency and accuracy. AI-enabled audio algorithms have the potential to make applications, such as predictive maintenance and health monitoring, intelligent. This Tech Spotlight will give an overview of how machine learning algorithms are trained when working with audio, and show an example of voice recognition with machine learning using Edge Impulse.
What is Machine Learning?
Machine Learning is a type of AI that focuses on data analysis. ML models are trained with a large number of relevant datasets, after which they are able to recognize patterns and make decisions on new input data with minimal human intervention. The goal of ML is for systems to be able to learn from previous data in order to make new decisions that are repeatable and reliable. While ML algorithms are not a new concept, the ability to process and learn using large datasets at usable speeds has not been possible until recently.
Deep Learning with Audio
In the past, machine learning algorithms would extract individual features from an audio clip using digital signal processing (DSP). These features would then be analyzed using phonetic concepts in an attempt to classify the audio. This required a great deal of processing power, as well as extensive expertise in acoustics, linguistics, and audio processing.
|
What is a Feature in Machine Learning? A feature is an individual measurable piece of data in a machine learning model that can be analyzed. Features should be distinctive and independent. The better the features are within a dataset, the more success the algorithm will have in finding patterns in the data. |
With the advancement of deep learning, modern audio algorithms have evolved. Deep learning is a subset of machine learning, where algorithms, called artificial neural networks, are modeled after the human brain. Today’s deep learning algorithms first convert an audio waveform into an image, called a spectrogram. The spectrogram is then processed with a convolutional neural network (CNN), similar to those used in computer vision applications.
For more on CNN algorithms in computer vision applications, take a look at our Tech Spotlight on Object Detection with AI using Edge Impulse.
What is a Spectrogram?
A spectrogram is a visual representation of an audio clip, comparing frequency and amplitude over time. The Y-axis shows the range of frequencies, with the X-axis showing time. The amplitude or strength of each frequency is represented by the color and brightness. A spectrogram can be thought of as a fingerprint of the audio clip.
Figure 1 illustrates an example of a spectrogram.
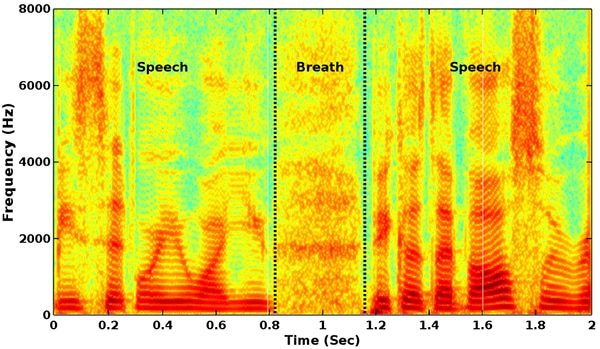
Figure 1: Spectrogram of a speech signal
Source: Dumpala S. & Alluri K., (2017). An Algorithm for Detection of Breath Sounds in Spontaneous Speech with Application to Speaker Recognition
Deep Learning Process
Deep learning audio applications typically start their process in a similar fashion. First, the audio is converted to a digital format. The digital audio is then converted into a spectrogram. Some applications may do simple processing on the audio, for example equalization or noise reduction, before conversion. Once the spectrogram is created, standard CNN algorithms can be used to extract features. After an acceptable feature map is extracted, any additional processing is done depending on the application.
Applications
Audio applications with AI cover a wide range of industries; the ability to extract and classify individual sounds from an audio file benefits many applications. Voice recognition is already used in many industries and will become more widespread as the technology improves. Because machines sound different when they are not working properly, adding audio classification capabilities could make a big impact in predictive maintenance. Healthcare also has several use cases, as many ailments are diagnosed through listening to the body. In addition, AI has the potential to introduce many novel applications in media and entertainment.
One popular application that several devices currently use is wake words. Wake words are specific phrases that trigger a device to come out of standby mode and listen for more instructions. Wake word examples include Amazon’s Alexa, Apple’s Siri, and Microsoft’s Cortana.
Wake Words with Edge Impulse
Edge Impulse provides the environment that can be used for a variety of machine learning applications. A wake word application that recognizes keywords and other audible events, even in the presence of background noise, can be developed quickly with Edge Impulse Studio.
First, you’ll need to connect the development board to Edge Impulse Studio. Supported devices include:



Next, think of your wake word. The sound of the wake word should be complex and not easily confused with another sound. For example, a one-syllable word, like “hey”, would be difficult to differentiate from “say” or “day”, leading to false-positives. To avoid this, Apple, Microsoft, and Amazon all use at least three-syllable words (“Hey, Siri”, “Cortana”, and “Alexa”).
After you’ve selected your keyword, you’ll need to record yourself saying it over and over to create data for training the model. This is done using the Data Acquisition function in Edge Impulse Studio (Figure 2).
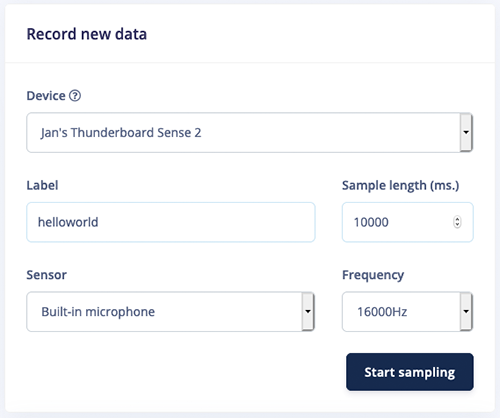
Figure 2: Recording a keyword in Edge Impulse Studio
Source: Edge Impulse
Figure 3 shows the result of recording “Hello world” six times.
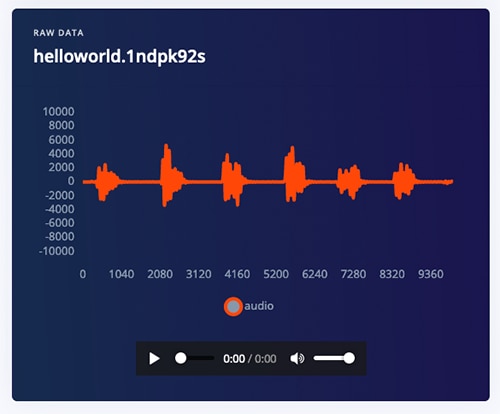
Figure 3: 10 seconds of “Hello World” data.
The audio file can be split into separate samples with the Split Sample function, as depicted in Figure 4.
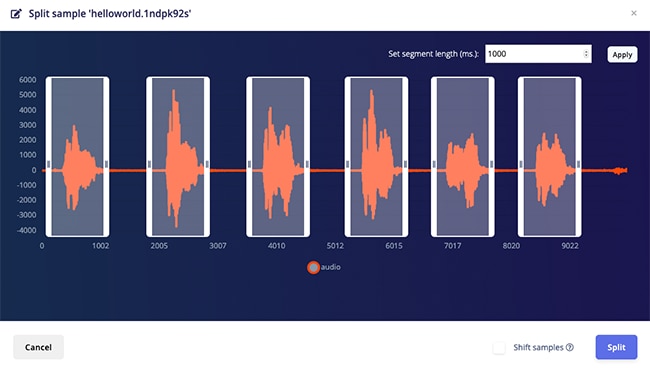
Figure 4: Splitting the audio data in Edge Impulse Studio
In addition to the audio of the wake word, the model can be made more accurate by training with other sounds. These can include background noise, such as appliances or a TV, and people saying other words. The more varied the data is, the better the training will be. Collect 10-minute samples of various sounds, and enter them into Edge Impulse Studio. Edge Impulse also provides existing datasets of both background noise and random words that can be imported into the project.
The next step after uploading your dataset is to design an impulse. An impulse is the start of the algorithm’s training. The raw data is split up into smaller windows where features are extracted using a signal processing block, after which new data is fed into a learning block for classification.
Edge Impulse offers several signal processing blocks, such as MFE (Mel-filterbank Energy), Spectrogram, and MFCC (Mel Frequency Cepstral Coefficients). For wake word detection, MFCC is the best fit due to its performance in processing human speech. MFE and Spectrogram are better suited for non-voice audio. In Edge Impulse Studio, the signal processing block is selected in the Create Impulse tab (Figure 5).
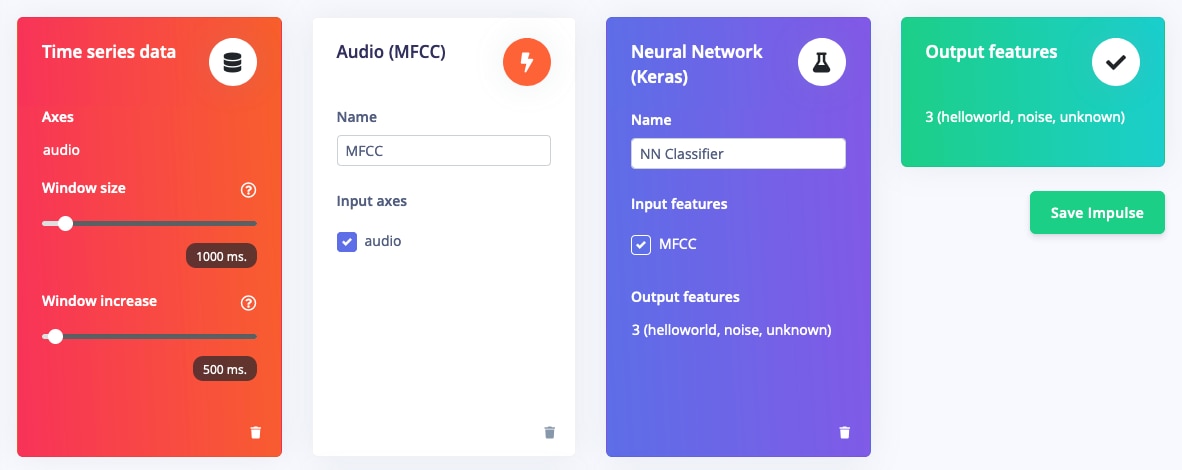
Figure 5: Create Impulse in Edge Impulse Studio
Clicking on the MFCC link brings you to an interface for the configuration of the MFCC block. On this page, various parameters can be set, including the resolution of the spectrogram, which is adjusted by changing the number of coefficients (or frequency bands), frame stride, and frame length. Figure 6 shows a screenshot of the configuration page. On the right side, a sample spectrogram is displayed based on the configuration settings.
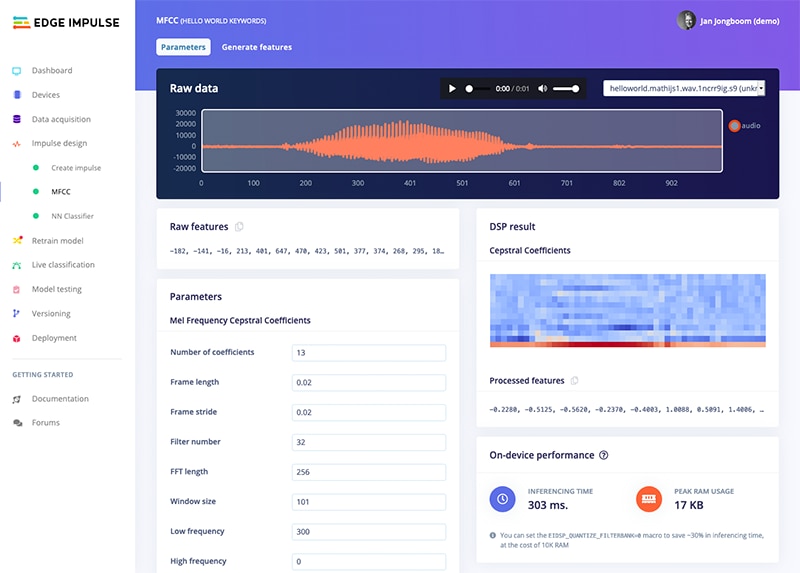
Figure 6: MFCC Block with an audio file loaded

Figure 7: Spectrogram for a voice saying “Hello world”

Figure 8: Spectrogram for a voice saying “On”
Once the MFCC block is configured, the Generate Feature function generates MFCC blocks for all of the audio data. Once this function has completed, the Feature Explorer opens. The Feature Explorer is a 3D representation of the complete dataset, color-coded for each type. Clicking on each item lets you listen to the sample.
After the data is processed, the next step is the training of the neural network. A neural network operates by feeding the image into a series of layers, each one filtering and transforming it. For example, a filter can be applied that enhances the edge pixels of structures in the image. During training, the neurons are gradually adjusted over thousands of iterations, each time checking to see how close the network’s output, or prediction, is to the correct answer.
In Edge Impulse Studio, the neural network can be configured with the NN Classifier (Figure 9). Edge Impulse provides a default neural network architecture, but others, such as Tensorflow and Keras, can be selected. You can also define your own custom architecture. In the NN Classifier, the “Minimum Confidence” can be adjusted. If a prediction has a confidence level (the probability that the audio clip contains the specified audio) that is under the Minimum Confidence level, it is thrown away. The NN Classifier also allows you to add “Data augmentation”, which comprises random mutations of the data, such as additional noise or warping of the time axis. This simulates the unpredictability of real-life data and lowers the potential for overfitting. Overfitting can occur when the algorithm learns the training data too well, to the point where noise and random fluctuations are learned. This makes it ineffective when working with new data, where the noise and random fluctuations are not present.
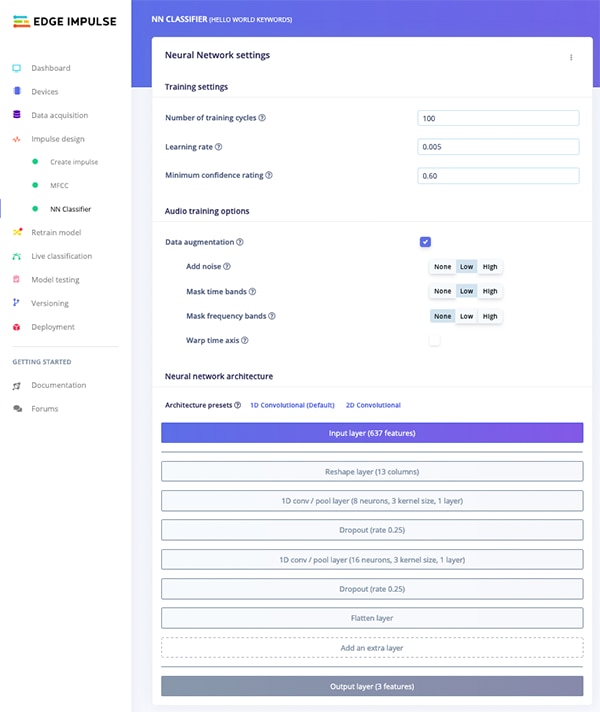
Figure 9: NN Classifier in Edge Impulse Studio
Once the neural network is configured, training can begin. Click “Start Training” to train the model. Figure 10 shows the results of training.
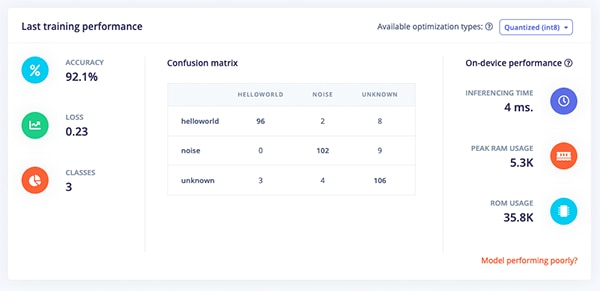
Figure 10: The results of a model trained to recognize the “Hello world” keyword
To test the newly trained neural network, click the “Model testing” menu item. From here, you can test with new audio samples, update labels, and add audio to your training set to help refine the model with retraining. Figure 11 shows the Model Testing page.
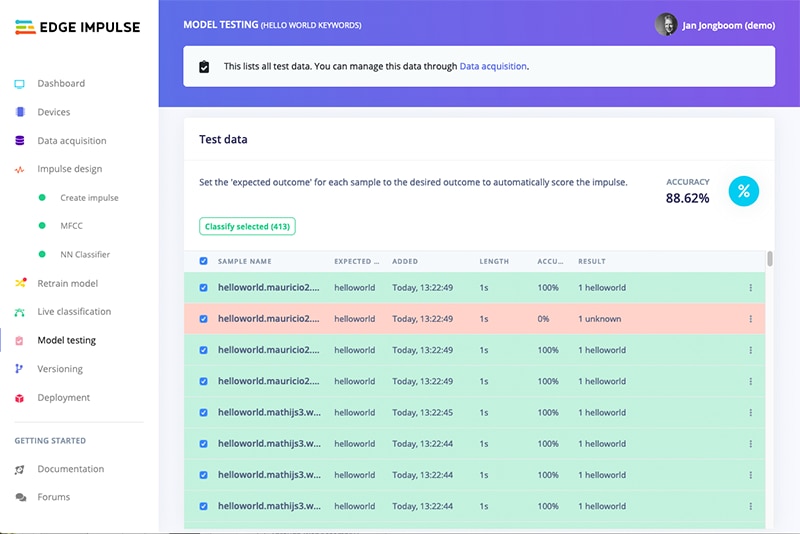
Figure 11: Model testing showing 88.62% accuracy on the test set
Once the algorithm is delivering satisfactory results, the software can be compiled using “Deployment” in Edge Impulse Studio. A pop-up will appear with instructions on deploying the executable to your device.
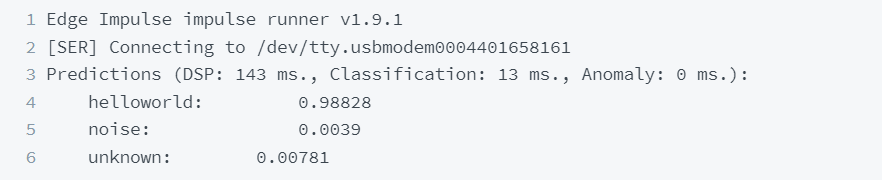
Once the executable is on the device, run the Edge Impulse Impulse Runner in a terminal window.

The device is now listening for the wake words you’ve specified.
Summing Up: AI for Audio Applications
Audio data can be used to support a myriad of applications, and recent advancements in artificial intelligence have enabled software and devices to take over more of the classification and decision-making duties. From convenient bells and whistles, such as voice commands and wake words, to pointing out the sound of a broken motor on the factory floor, AI-enabled audio applications has the potential to improve the functionality of many devices.
This Tech Spotlight presented a very high-level overview of the process of creating a wake word application. For more information, including troubleshooting and more training tips, take a look at the official tutorial from Edge Impulse. In addition, Lorraine from e14presents goes through the process of building a wake word detector (with extras) using a Raspberry Pi and Edge Impulse.

