



Last week, in a mashup of Embedded.fm episodes 95 and 26, I started talking about Device Internationalization, introducing the terminology and describing the path to get from English-only to European language support. This week, I want to dive deeper into the technical challenges associated with supporting Asian languages.
As noted in Ken Lunde’s comprehensive CJKV Information Processing, CJKV stands for Chinese, Japanese, Korean, and Vietnamese. CJK are languages that have extensive ideographs instead of (or in addition to) a phonetic alphabet. Instead of a few dozen letters that represent sounds, our device will need many thousand glyphs to represent whole words. (Vietnamese has a large alphabet with diacritical and tonal marks but it shares more with FIGS and Cyrillic than the much larger CJK character sets.)
There are four big issues that CJK internationalization requires device developers to understand:
- Choosing display hardware that will show characters legibly
- Choosing a character set
- Storing and accessing thousands of characters
- Acquiring images for thousands of characters
Threshold of Legibility

The threshold of legibility is different for complex images, such as Chinese hanzi ideographs. An English speaker can understand all of the numbers and several letters on an 8-segment display. They don’t necessarily look like beautifully designed but they are legible. (And a display that is 12 pixels high and 8 pixels wide (12x8) shows letters that are nice looking.)
However, ideographs are square. A character with dimensions of 12x12 is barely legible, possibly illegible for some characters (similar to how 8-segment displays are for English). That may be acceptable for some devices willing to limit what they display (i.e. a microwave). On the other hand, to get a nice looking display, each character needs to be at least 32x32 pixels.
The good news is that, because of their information density, you may be able to put fewer glyphs on the screen. Instead of a long, wide (or scrolling) display to accommodate long German words, you may be able to have a smaller display, though with the same resolution.
Choosing a character set

In the US, our character set consists of 94 letters, numbers and symbols, encoded in a single byte according to ASCII (which happily is also Unicode’s UTF-8). When we added another 94 characters to support FIGS languages, we could stay with a single byte per letter (or symbol). To support Asian languages, each character may require two bytes (or more). There is plenty of existing library code able to handle wider characters but you may need to verify that basic functions (i.e. strlen) work as intended.
With two bytes, you can access 65,535 ideograms. That seems like plenty until you find out that Chinese supports over 100,000 ideograms. On the other hand, you probably don’t need all of those.
The Chinese government’s GB2312 standard has 6,763 hanzi characters. This covers 99.75% of normally used Chinese characters with some historical and proper name characters being out of scope. Chinese users are also accustomed to having other characters at their disposal: 500-1000 other characters covering the US alphabet, FIGS, Cyrillic, Greek, etc.
How many characters do you need to support Chinese? Starting with Unicode’s BMP is a very reasonable way to go. They’ve already done the work of figuring out which are the most common which means you don’t need to reinvent the wheel. However, with nearly 21,000 hanzi characters, at 32x32 pixels each, you are looking at 1.3 Mbytes (not counting overhead).
Given the low cost of SPI Flash, that may be possible for your device but it may still be non-optimal. The thing to do is to figure out the size of memory your BOM can accommodate and then find a standard of that best fits that size. Here are some ways to build a character set:
- Chinese: Start with the 3500 commonly used characters. If possible, add the non-hanzi characters from GB2312, then add missing ones from the Chinese Proficiency Test vocabulary words, finally add more missing ones from list of one hundred common Chinese surnames.
- Japanese: Take JIS X 0208: 1997 (2965) L1 kanji, then add the unsupported from common (jōyō) and name (jinmeiyō) kanji lists.
- Korean: The best option is to support all of KS X 1001 has 2350 hangul and 989 symbols
Note that these resources include other symbols such as Latin letters, Cyrillic, Greek, Japanese kana (syllabaries), as well as an assortment of punctuation. When you are looking at several thousand characters, a few hundred to support loanwords from other languages is not as daunting. Also, these resources are not complete; instead they form a reasonable set of characters, one that you can explain. Some of these links are themselves encoding standards, describing how to represent the character numerically as well as the characters supported. However, we are definitely using Unicode’s UTF-8 for encoding (right!?!?) and only looking at these standards for the list of characters to support.
With the way English speakers view letters, leaving one out would be unthinkable (“of course you need x, how would you say fox?”). However, if you think about it as a dictionary, with 2500 words, you can describe what you need without choosing a word outside the list. And if a user inputs a character that your device doesn't support, show the white box that indicates unknown (this is also called the tofu character, because it looks like a piece of tofu).
Whatever you support, be prepared for users to request more. Speaking to a developer in China, he explained that people understand devices have limitations, and suggested this:
Chinese Package disclaimer: This product contains the 3500 most commonly used characters with some extensions for common Chinese surnames. Let us know what you’d like to see in the next version!
Han Unification

The Chinese hanzi, Japanese kanji, and Korean hanja share a lot in common, including Unicode endpoints. That means that the same ideograph has the same numeric code thanks to Han unification in the Unicode specification. However, “same ideograph” is a bit of a misnomer as the glyphs may be different.
Consider if all Spanish language was written in Courier font but all French was written in, say, a calligraphy font. If a product uses the calligraphy font when shipping to Spain, the people will know that the product was intended for France. It will still be legible, but not native. Depending on the customer experience you intend legible may not be sufficient.
This means that you need a glyph set specific to the locale to which you are shipping your product. Given one font size (though that seems limiting), you might still fit all of the chosen characters on an 8Mbit flash.
Language | # characters supported | 32x32 pixels kbytes | + 30% overhead kbytes | Space needed kbytes |
Chinese | 4500 | 286 | 86 | 372 |
Japanese | 3700 | 235 | 71 | 306 |
Korean | 3400 | 216 | 64 | 281 |
Accessing characters
When using a font made up of only ASCII characters, we usually use a series of lookup tables to find the image to put on a screen. It starts with a font table (if you support multiple fonts). Once you’ve selected a font, usually there is a glyph lookup that lets you compare the character you want to display to the ones in the table. This is a search step because you need to find the right range but as long as you only have a few entries in the table, it is usually fast enough. Once you find the correct slot, you can jump into the image information table get data about the specific data to display. This sort of table is pretty fast, dense, and ubiquitous for ASCII (and single byte UTF-8 FIGS characters).
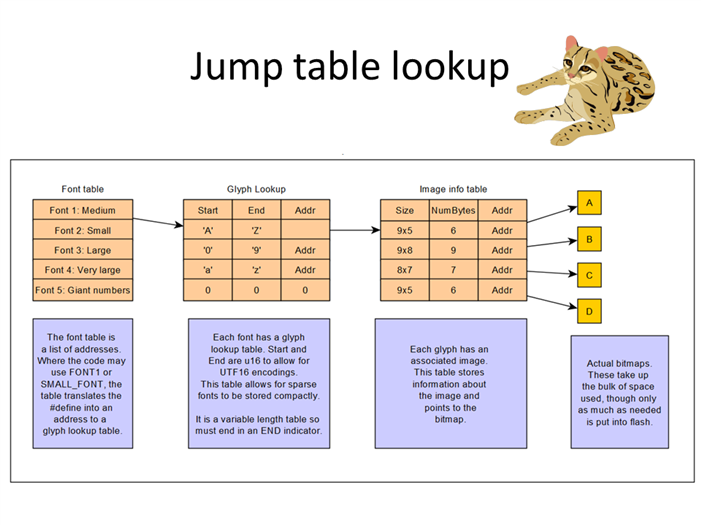
However, remember how we chose 4,500 of the possible 21,000 Chinese characters (that were two bytes under UTF-8 and stored in BMP)? Unfortunately, we didn’t choose the first 4,500 or the middle or last, they are evenly distributed through the list. This lack of packing density makes the normal font lookup impossible: you’d spend way too much time searching the glyph lookup table for the one you want.
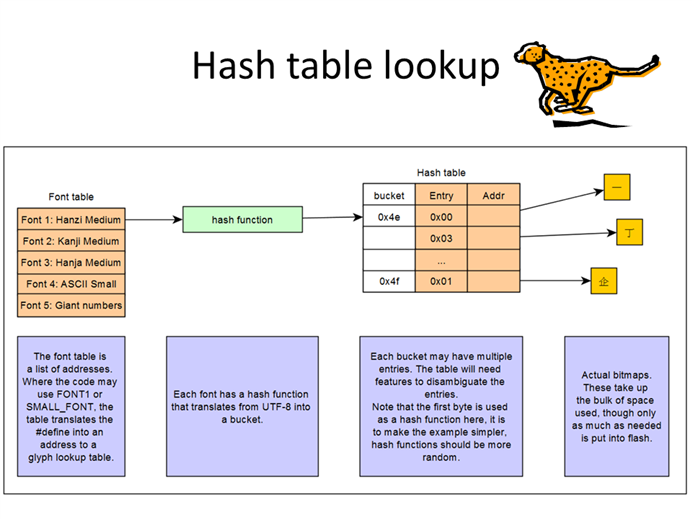
Instead, I recommend using a hash table to reduce the problem to something more tenable. I’ll even suggest a hash function: xor’ing the high and low bytes of each codepoint. This leads to 256 buckets, reasonably well distributed, though not optimally (when I ran my numbers, I got a maximum of 25 entries in a bucket where optimal would be 17; if I added high and low bytes I got a max of 27).
Embedded Fonts
With US, you may have purchased a font or may have had designers make one for your display to avoid licensing issues. However, creating your own CJK fonts is likely not feasible for small company.
This used to be a blocking issue but Google and Adobe have released that open source font Source Hans Sans that makes CJK internationalization feasible for smaller companies (and V, don’t forget Vietnamese just because it isn’t as difficult) . There may be a few steps between downloading this font from github and outputting it to a hash table accessed library of bitmaps but haven’t you wanted to familiarize yourself with Python anyway?
Closing

There are so many resources for localization that it is easy to become overwhelmed. Worse, as I focused on device localization, I would get to the end of a book or article only to find out the suggested methodologies were unavailable to me (why did it always end up suggesting having the user download a different font and read it in their browser?).
I had the opportunity to speak with grandmaster of internationalization information, Ken Lunde. I may have used our podcast to ask him all of my personal questions about the nitpicky details I needed to know to get my job done. However, we did record and release it, so you might find it helpful if you are starting out with the process.
Ken’s book (CJKV Information Processing) is also very helpful, though large and not embedded specific. I also found Common Chinese Characters to be a useful website for beginning to understand the interesting intricacies of the Chinese language (nothing means just one thing). I tend to want to be tactical with getting my job done but I may have spent a bit of time learning a few characters.