


Living in an era of unprecedented booming artificial intelligence (AI) feels none less than storylines for science fiction movies. A tiny portion of recent successes of machine learning can be attributed to the advancements of algorithms in this past couple of years, but this stuff has been lurking around for decades, waiting for hardware infrastructure to catch up. Instead, the success of machine learning has relied solely on the collection of training data and building infrastructure to train them that companies — like Google — have managed to build up which has made substantial breakthroughs in a wide spectrum of fields, ranging from speech recognition, natural language processing, computer vision to robotics. Machine learning development has been proliferating but the deployment at the last mile is still questioned.
Feasibility of AI on large scale deployment:
AI is the enabling technology that requires large amounts of data. Machine learning is traditionally associated with heavy-duty, power-hungry, processors. It’s something done on big servers. Cisco estimates that just about 850 ZB is going to be generated by people, machines, and things at the network edge by 2021. When that’s the case, important nuances may be lost, which limits the potential to enhance AI training in the cloud or data center.
Example:
Automotive is driving the pattern – the normal non-self-ruling vehicle currently has 100 sensors, sending information to 30-50 microcontrollers that run about 1m lines of code and create 1TB of data per vehicle every day. Extravagance vehicles may have twice the same number of, and independent vehicles increment the sensor check considerably more significantly.
Source – https://reality.ai/ultimate-guide-to-machine-learning-for-embedded-systems/
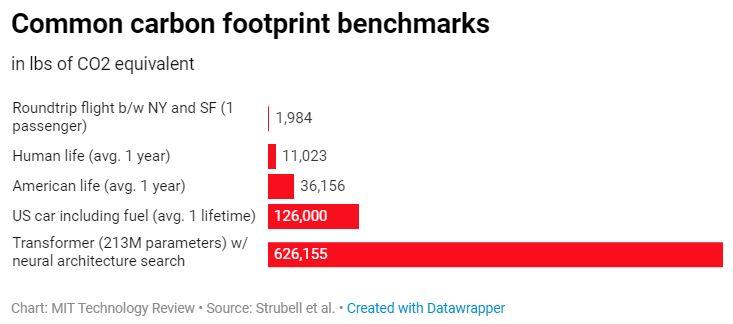
Researchers at the University of Massachusetts performed life cycle estimation for training several common large AI models and found out that the whole process can emit more than 626 thousand pounds of CO2. Hence sending all this data to the cloud puts a huge pressure on our existing bandwidth infrastructure capabilities.
Presently, most IoT gadgets are controlled by batteries which can’t dependably bolster the continuous assortment and examination of data. As indicated by Forrester Research, 60% to 73% of the information in an undertaking that could be utilized for examination goes undiscovered. Because of this significant subtleties can be lost and the potential to improve AI preparing in the cloud or server farm is undermined.

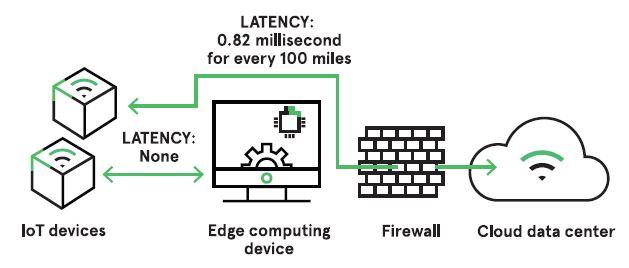
Even if the sensors, cameras, and microphones taking the info are themselves local, the computer that controls them is much away, the processes that make decisions are all hosted within the cloud. While this approach has proven reliable, the number of your time it takes to finish the transfer of information to and from the cloud introduces latency issues that will affect real-time decisions. The farther away from a cloud data center is geographically located, more latency is introduced. for each 100 miles data travels, it loses speed of roughly 0.82 milliseconds. the entire process raises security concerns and hence more importance is then leveraged on data security and cybersecurity.
For example, drilling systems needed for various industries are often in remote locations with constraints such as high-speed wireless infrastructure. But recently the Industries want to put the power of machine learning to monitor closely what is happening to machinery and watch for signs of trouble. Often Conventional closed-loop algorithms lack the flexibility to deal with the many potential sources of failure and interactions with the environment in such systems. By utilizing machine learning to prepare systems on the conduct of real world interactions it is conceivable to work in more prominent unwavering quality.
Edge AI – Bridging the gap at the last mile:
The amalgamation of AI and edge processing has offered access to another examination territory, to be specific “edge intelligence” or “edge AI”. Essentially, the physical proximity between the data collection sources and the computing sources promises several benefits compared to the traditional cloud-based computing paradigm, including low-latency, energy-efficiency, privacy protection, reduced bandwidth consumption, on-premises and context-awareness.
The edge devices are mostly microcontrollers with a couple of sensing units and network connectivity modules. According to a research every year 40 billion MCU CPUs are shipping around the world and most of these CPUs are not going into your mobile phones. These small microcontrollers that going in objects we use every day a typical car these days a 60 different processor sitting in them you don’t really see them
If we look at the current state of where we are in 2020 a typical industrial sensor relatively expensive can do amazing things. We have now MEMS sensors, really tiny and efficient sensors that can measure vibration a few thousand times a second and are very precise. There are temperature measurements, measurements are waterproof and are now even explosion-proof boxes. If we deploy it in a factory and because of technologies like Laura and sigfox we can send data over 8 – 10 kilometers of range with only 20-foot mill watts of power. All this is enabled by a really powerful processor under the hood capable of running 20 million instructions a second. But what we do with such amazing devices is, once an hour it sends the average motion on the accelerometer, the peak motion and the current temperature over which is very little as we realize that the device can measure vibration at thousand times a second so we are throwing away lots and lots of valuable information and the only reason is that we need to run these devices off a battery and it’s kind of sad because these amazing devices are so underutilized.
The only real solution here is to put some own device intelligence on the device so that device alerts only when it identifies that the vibration pattern or temperature is unexpectedly altering and might lead to a fault in about a week from now or so. Focusing on deriving these conclusions from the sensor data at the edge is the main purpose. Since in the course of the most recent year or so there has been an acknowledgment that not all things can, or should, be done in the cloud. The arrival of hardware designed to run machine learning models at vastly increased speeds, and inside relatively low power envelopes, without needing a connection to the cloud, is starting to make edge-based computing that much more of an attractive proposition for a lot of people and has made the edge AI a real thing. Several key players are emerging such as Intel, Arm, Nvidia, Google, and also there is a start-up ecosystem building around this.
An accelerometer might send data a thousand times a second on three different axes; it’s very hard to program on such tiny devices. But machine learning is really great at trying to fit a curve through the data in a way that captures the very small variations between the different things and try to find this correlation. If you have realized that the okay Google Keyword spotting the thing that runs on every single one of your phones is a machine learning model and a machine learning model that doesn’t run on a big computer in a big data center. It is running on the signal processing little chip that sits inside the phone and the same goes for ‘Hey Siri’.
Machine learning models in training are just trying to find a mathematical function with lots of parameters that best match the problem at hand. Which means that if it is a mathematical function, we can just execute it on a little bit of computer as long as this function is not too large and can actually run it on a microcontroller? Yes, we can if we make a trade-off between a little bit of accuracy for a lot less memory because we are not that interested in all these like very tiny variations and are mostly looking at what the global say of the function is and utilizing the existing FPU in our processors can make the execution of these functions a lot faster on battery-powered devices that run off a battery for a year or longer that need to deal with messy sensor data.
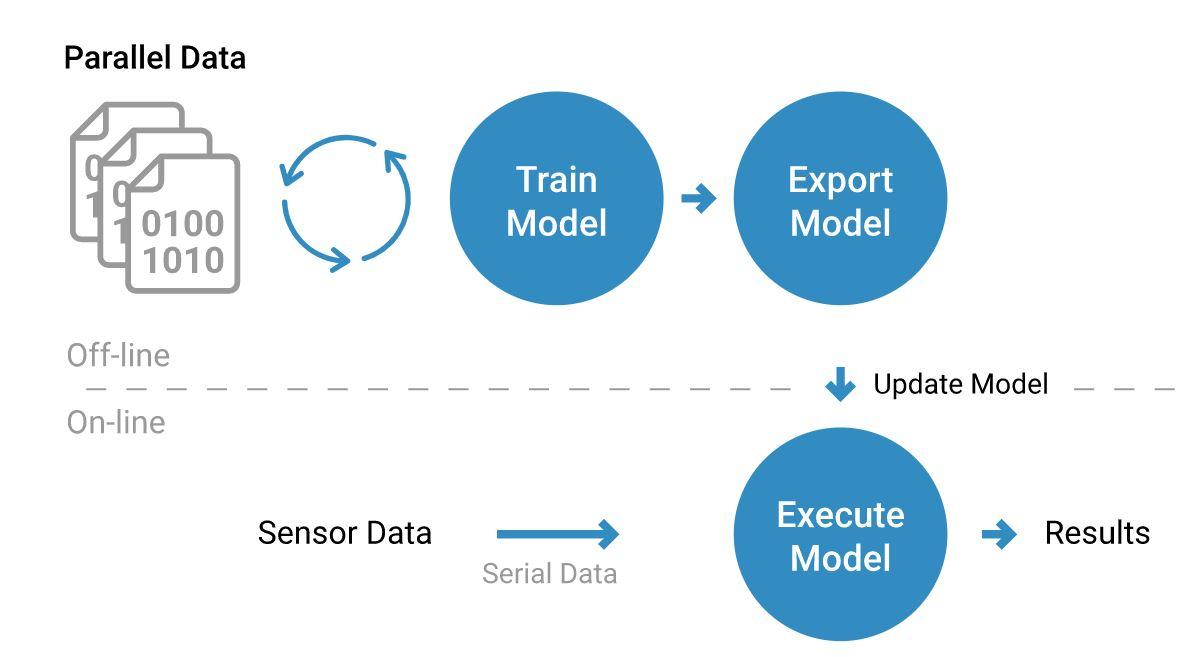
One of the most popular AI techniques, deep learning is being used for edge AI devices. Deep learning consists of two main pieces: training and inference. The training part usually happens to be offline on desktops or in the cloud and thus, enables feeding large labeled data sets into a deep neural network (DNN). Power or real-time performance is not an issue during this phase. The output of the training phase is a trained neural network. The deployment of the trained neural network on an edge device that executes the algorithm is known as the inference. Given the constraints imposed by an embedded system, the neural network is again verified with the real-time performance, and tradeoffs between accuracy and power consumption is made accordingly.

Edge AI has been widely recognized as a promising solution to support computation-intensive AI applications in resource-constrained environments. Edge AI is still at a very early stage. Few Embedded developers are specialized in utilizing the AI/ML platforms and vice versa. The capabilities of edge computing to handle AI algorithms and machine learning locally without the inherent latency of cloud computing will provide insights to more efficiently drive operations and increase productivity. Hence tech giants have already started investing in this field, this opens a new field for upcoming engineers’ to explore. There is, in general, a lack of sources committed for summarizing, discussing, and disseminating the latest advances of edge AI, hence I conclude to write an article on it.
If you want to know more about Edge AI here are some useful resources:
Videos:
https://www.youtube.com/playlist?list=PLHcJAnBJ_bsokR8sTaQTbm1erKfZ6l8Jv
Books:
Others:
https://www.tensorflow.org/lite/microcontrollers
https://github.com/uTensor/uTensor
https://github.com/agrimagsrl/micromlgen
https://github.com/merrick7/EmbeddedML
https://eloquentarduino.github.io/