


I've been spending a while on what I think is going to be my Pynq embedded vision project. I say I think it will be because I'm having a frustratingly difficult time of it. it's not the FPGA stuff. That's difficult but I'm getting used to that. It's not the Pynq/Pythn side of things. It's image processing.
A friend of mine races kayaks and apparently the monitoring of kayaks crossing the finish like is manual and fraught with error. There are lots of "recounts" and nobody trusts the results at all. I decided to identify the numbers on the kayaks as they cross the finish line, so I started digging into OCR (Optical Character Recognition).
As nobody is racing kayaks at the moment I decided to make use of the slightly odd blue carpet that was fitted when we bought the house and fake it a bit. I have some video, but to start with I decided to use this image. I made the numbers reasonably easy to read and even used an OCR-B font. OCR-A will probably look reasonably familiar but is a bit too strange to convince anyone to use for racing!
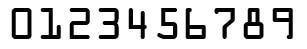
All image processing of this type like nice clean data to work with and so I grayscaled the data, used a threshold so I was just looking at black and white and applied a Gaussian blur to smooth any noise. All fairly standard stuff.
I also found that a "tophat" morphological operator removes the large elements, leaving just the smaller detail that we're interested in. So far so good. Here's a sample of the Python in my notebook:
import cv2
image = cv2.imread("kayak_ocr_b.jpg")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.threshold(gray, 100, 255, cv2.THRESH_BINARY_INV)[1]
gray = cv2.GaussianBlur(gray,(3,3),0)
cv2.imwrite("gray_ocr_b.jpg",gray)
# apply a tophat (whitehat) morphological operator to find smaller light regions against a dark background
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (18, 6))
tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel)
cv2.imwrite("tophat_ocr_b.jpg",tophat)
This is what my image now looks like. This should be a little easier for image processing.

Tesseract OCR
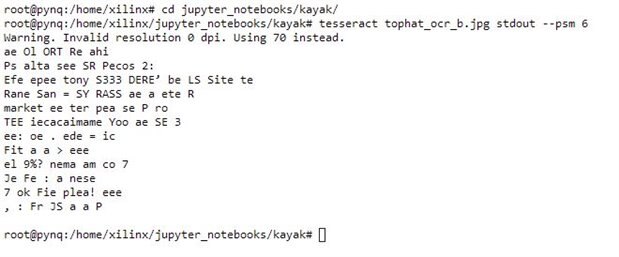
If you Google OpenCV OCR to tend to find that you're led towards Tesseract and (for Python) PyTesseract. You simple point Tesseract at your image and tell it where to put the text output. There are of course a few options, which I tweaked to tell it that I was looking for separate pieces fo text rather than a whole page. The output was pretty awful and also took about 10 seconds on the Pynq Z2. I managed to get something if I gave it the cleanest screenshot of some on-screen text but it was still pretty bad.
i decided that considering how slow it was, it wasn't worth pursuing much further. Time to look at a different approach.
Matching
It seems that rather than going for all-out OCR it is possible to pattern match to find the shapes of the digits I need. If it's possible to find eyes and faces and other such variable objects it shouldn't be too hard with 10 fairly well-defined digits. I have got control of the font after all.
I found this interesting tutorial on scanning for credit card numbers. It seemed to be fairly similar to what I needed and it wasn't too difficult to adapt it to look for some separate blocks of digits rather than the 4 sets of four used by credit cards. I even managed to get it to work a bit when I had used an image program to clearly paste some OCR-A numbers over the ones in the photograph. It wasn't unbearably slow either.
However, as soon as I switched to something even slightly realistic - using OCR B instead of OCR A or printing the numbers on paper where they may be ever so slightly angled, it all fell apart. I've spent days trying to tweak it to get something to work. I could even get ludicrous results like this cropping up - from an earlier attempt when using copy and pasted OCR A.

Rant almost over
Sorry this has been a bit of a rant rather than a helpful blog post, but I believe it can sometimes be as important to document failure as success. If anyone does have some tips on OCR then feel free to post below. I'm really enjoying a lot about Pynq, but right now image processing it not part of that! 
Top Comments