Introduction
An important feature of every sophisticated test bench is the ability to read stimuli and report the result so it can be analysed outside the simulator. For simple HDL designs one can generate the stimuli within the test bench environment, however, as the design complexity increases, the requirements for the applied input data also become stricter.Therefore at certain point it becomes difficult and time consuming to generate the desired input data within the test bench.
Instead it would be easier if the designer has a stimuli generator, like as python script that generates a text file with the desired data.
Then the only thing left for the test bench to do is to read the data from the file and apply it to the DUT.
Similarly for the output analysis - instead of “manually” reading the timing diagram, one can quickly browse through a summary of the output that has been written into a text file.
In order to be able to do this, the designer has to make use of the Text IO libraries included in the respective HDL language.
Therefore I am going to show you how to use the VHDL textio and std_logic_textio libraries.
But first open the two libraries and see what they can do.
textio summary: https://www.csee.umbc.edu/portal/help/VHDL/textio.vhdl
In textio you can find the read write operations for the following data types:
- Bit
- bit_vector
- Boolean
- Character
- Integer
- Real
- String
- time
Notice that there are no operations for:
- std_logic
- ustd_logic,
- std_logic_vector
- ustd_logic_vector.
The definitions for these data types are found in std_logic_textio (std_logic_textio summary: https://www.csee.umbc.edu/portal/help/VHDL/std_logic_textio.vhdl )
Also std_logic_textio gives you the ability to write a binary value in hexadecimal as well as octal format, which can be handy in certain situations.
The first thing to do before the actual R/W operation, is... to add the libraries in the design.
use STD.textio.all;
use ieee.std_logic_textio.all;
Then declare the file(s) of interest in the process, but before “begin”:
file input_file : text is in "Text_IO_Demo.txt";
Warning: the line above is in VHDL87 style. This may cause errors or warnings. If so then use the following syntax:
file input_file : text open read_mode is "Text_IO_Demo.txt";
Note that 'input_file' is 'file' object and its type is 'text'.
"Is in" specifies the directory of the text file. If it is included in the project, then you can use only the filename, otherwise you have to include the file directory as well such as:
file input_file : text is in "C:\Text_IO_Demo.txt";
There is also an alternative way of accessing the file, which is written like:
file input_file : text open read_mode is “Text_IO_Demo.txt”;
and respectively
file input_file : text open read_mode is “C:\Text_IO_Demo.txt”;
Also other than "text" type, there is "intf", which stands for "integer file", but I wasn't able to find enough info about it, so I decided to skip it.
As for the file extension - I have seen all kind of examples like ".csv", ".vec" and ".out", however I have worked only with ".txt", therefore I prefer to stick to it for now.
Next, there should be a variable of type ‘line’ that is used to store each individual line - the text file is processed line by line. The individual line objects are added/extracted separately. This will be demonstrated later.
variable input_line : line;
Then the user must declare the carriers of each individual line element, and because I would like to evaluate every single type of the above mentioned,
I have 16 different variables in my process. Variables are needed only for the reading operation.
variable bit_input_v : bit;
variable bit_vector_input_v : bit_vector(Vector_Length-1 downto 0);
variable boolean_input_v : boolean;
variable char_input_v : character;
variable int_input_v : integer;
variable real_input_v : real;
variable str_input_v : string;
variable time_input_v : time;
variable std_logic_input_v : std_logic;
variable std_vector_input_v : std_logic_vector(Vector_Length-1 downto 0);
variable std_ulogic_input_v : std_ulogic;
variable std_uvector_input_v : std_ulogic_vector(Vector_Length-1 downto 0);
variable hex_vector_input_v : std_logic_vector(Vector_Length-1 downto 0);
variable hex_uvector_input_v : std_ulogic_vector(Vector_Length-1 downto 0);
variable oct_vector_input_v : std_logic_vector(Vector_Length-1 downto 0);
variable oct_uvector_input_v : std_ulogic_vector(Vector_Length-1 downto 0);

Now it is time to do the actual R/W operations which happen in two stages.
READING
Read a row from the text file. This is done with the following predefined command:
readline(input_file, input_line);
Where the first argument is the file of interest and the second is the variable that will hold the extracted line.
2. Copy the elements from the current row (line), which happens like this:
read(input_line, bit_input_v);
Where the first argument is the current text line and the second argument is the object to be read from the row. Read(), Hread() and Oread() can take only variables as argument,
which means that it is not possible to copy more than 2 objects at once. Also if you want to access the 3rd object from the row, first, you have to extract the first and the second object.
Once the data is read, it can be applied to the desired destination, in this case it is a signal.
bit_input_s <= bit_input_v;
This is how to read a file in an essence! Of course there are a lot more details that are not so obvious, like what to do when the end of the file is approached.
End of file
To solve this problem the textio package includes function called "endline" that takes the input file as an argument and returns true or false where "false" indicates that the file is not completely read yet
and "true" means that the file has been read completely. Therefore the designer can encapsulate the reading operation in the following statement in order to detect the end of the file:
if (not endfile(input_file)) then
--==================
-- Reading operation
--==================
else
assert (false) report "Reading operation completed!" severity failure;
end if;
Of course the else condition and the assertion are not necessary.
Reading characters
If you have a column of characters separated from other values by a white space like I have in my Text_I_Demo.txt file, then you must put two read statements in order to read the correct object.
This is because the first read will copy the white space between the previous object and the character, and the second statement will read the character itself.
Note the apart from reading characters and strings, it is not necessary to read the white space between two separate objects.
Speaking of "white space", it is the only legal separator recognised by VHDL along with tab separation, therefore no commas etc (at least when reading .txt files).
Reading strings
Another thing that one should be careful with is working with strings:
- Note that I declared the string as
string(Vector_Length-1 downto 1);
and not
string(Vector_Length-1 downto 0);
This is because the second statement generates index out of range error (at least in Vivado):
[VRFC 10-923] index value <0> is out of range [1:2147483647] of array <string>
Therefore in the declaration the LSB of the string should never be '0'.
2. Just like reading characters, reading strings also begins from the whitespace that separates the objects,
hence if you want to read "cat", instead of " ca", then add one character reading operation before the string read, in order to compensate for the white space.
3. For example when the string is 3 characters long (3 downto 1), any words shorter than 3 characters will be omitted, and any word with more than 3 characters will be truncated,
therefore instead of reading "my ", "cat", "sleeps", you get " ", "cat", "sle" and in general (not only for strings) it may happen that the signal is not be updated with the word from the text file.
To avoid this problem always add white spaces before or after shorter words in order to comply with the amount of characters declared in the string definition.
This means that in the file instead of writing "my", I should have written "my " or " my". Also in case of "my ",
there should be white space between the filling white space and the next element in the row unless the next object is also a character or a string
Reading time
Space between the value and the time order of magnitude is not required, hence both
10ns
and
10 ns
are accepted (at least in Vivado) . In this example the time read from the text file is used to determine the duration of the next waiting period.
Working with std_logic and std_ulogic
1. All values other than '0', '1' and '-', should be in upper case otherwise they will be read as 'U's
2. Reading values in Hexadecimal Octal format can be performed only with hread and oread respectively.
3. Hread and oread cannot be applied to std_logic and std_ulogic, only vectors can be used.
4. Characters other than 0-F for hexadecimal and 0-7 for octal force the vector to 'U's
5. Hexadecimal requires signals multiple of 4 bits and octal requires multiple of 3 bits.
6. Similarly to string, the data in the file must match the vector width defined in the VHDL file(s)
Notice that whenever the value in the text file does not match the predefined type in the test bench, the signal is ether filled with U's or not updated at all.
To detect this kind of situations, you can use the third argument of read(), hread() and oread() operations, which is a feedback (of type boolean) that indicates the 'integrity' of the object.
Hence if the element in the text file contains only characters that are valid for the respective variable, then the feedback is true,
else if the object contains characters other then the expected ones the feedback is false.
Example: if you want two read a hex value composed of 2 characters, let's say x"0f", but in the file there is x"0k" or x"0", then the feedback returns false.
The idea of the feedback is to detect bad objects and eventually take certain action in order to apply a legal value to your signal.

Note that you can only read the same amount of elements that are in the current row or less, but not more. This means that the text file rows can have variable amount of elements,
but the code should never try to extract more elements than there really are in the current row, else the variable will not be updated or it will be filled with U's.
Cool!
But what if I want to read the same file 2 time or read a specific row?
As far as I know VHDL does not allow the user to change the text row index, however, a possible solution is to copy the whole content of the file into a variable(s) and then access it as you like.
There may be other ways around this problem and if you know them, please let me know in the comments below 
WRITING
When writing, the order of operations is the opposite:
1. Write data to the line.
2. Write the line to the text file
But first the output file and the line has to be declared:
file outfile : text is out "Report.txt";
variable outline : line;
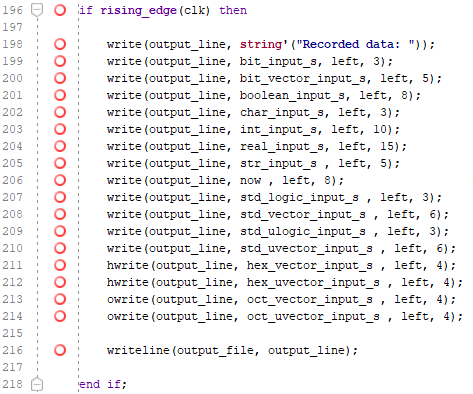
Unlike the reading operations the arguments when writing don't have to be variables, therefore in this example I fill the output file with the data contained in the signals from the reading process.
The only difference is that the data is "resampled" every 10ns, instead of being exact copy of original.
To write data the following function is used:
write(output_line, bit_input_s, left, 4);
Where the first argument is the output line, the second is the object of interest (the signal or variable),
the third one is the position of the object within the allocated amount of characters defined for the writing operation (therefore it can have values only of “left” and “right”) and the last one is the amount of characters reserved for this object.
For example if the amount of characters you want to write is '1', but you allocate '4', then in the text file you will see one character and three white spaces.
The by using "left" or "right", you can adjust the staring position of the input string relative to the reserved space. Hence, setting "left" will result in "1 " and setting "right" will result in " 1".
You can add more objects to the line with additional write() statements or you can write the current content of the line to the text file by having the “writeline” command.
That is it.
One suggestion is when you write multiple objects in a line always put some space between them. This can be done by allocating a bit more space than the object really needs.
On the other hand if you define too few character, the object will not be truncated and if you write another object, then they will be concatenated.
Writing strings
It is also possible to write text directly instead through a signal or variable.
One of the possible ways is like that:
write(output_line, string'("Recorded data: "));
Note that the string has to be casted.
There is another way
write(output_file,"Recorded data: ");
However, note that the first argument is not the text line but the text file. Moreover the string will be placed in the beginning of the line, no matter where the statement is placed.
At least that's what is happening in Vivado 2017.4.
This is how I perform the Text IO operations in my designs. Sometimes if the read operation is not valid, then you should check the spacing between the line objects.
I'm quite sure there are some features I haven't covered in this post therefore if you thin something more can be added then let me know in the comments.
You can get the source code as well as the Vivado project from Github repository. Try to modify the values and see what happens.
Hope you found this useful
============================================================================================================================================================================================================================
Resources
Source files
https://github.com/DHMarinov/FPGA/tree/master/Xilinx/Misc
Input file content
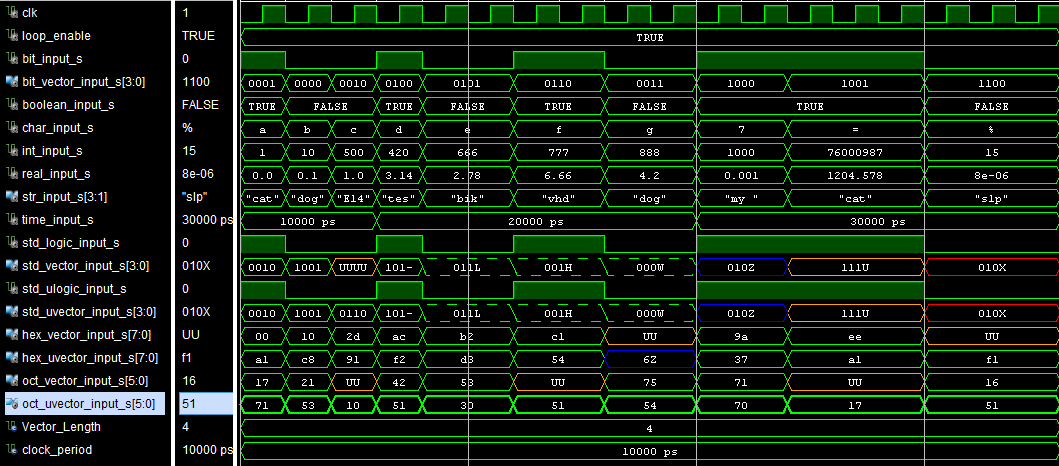
1 0001 true a 1 0.0 cat 10ns 1 0010 1 0010 00 a1 17 71
0 0000 false b 10 0.1 dog 10 ns 0 1001 0 1001 10 c8 21 53
0 0010 false c 500 1.0 E14 10ns 0 0112 0 0110 2d 91 3p 10
1 0100 true d 420 3.14 test 20ns 1 101- 1 101- ac f2 42 51
0 0101 false e 666 2.78 bike 20ns 0 011L 0 011L b2 d3 53 30
1 0110 true f 777 6.66 vhdl 20 ns 1 001H 1 001H c1 54 68 51
0 0011 false g 888 4.20 dogs 20ns 0 000W 0 000W 1k 6Z 75 54
1 1000 true 7 1000 0.001 my 30ns 1 010Z 1 010Z 9a 37 71 70
1 1001 true = 76000987 1204.578 cat 30ns 1 111U 1 111U ee a1 19 17
0 1100 false % 15 0.000008 slps 30ns 0 010X 0 010X ek f1 16 51
Output file content
Recorded data: 1 0001 TRUE a 1 0.000000e+00 cat 5 ns 1 0010 1 0010 00 A1 17 71
Recorded data: 0 0000 FALSE b 10 1.000000e-01 dog 15 ns 0 1001 0 1001 10 C8 21 53
Recorded data: 0 0010 FALSE c 500 1.000000e+00 E14 25 ns 0 UUUU 0 0110 2D 91 XX 10
Recorded data: 1 0100 TRUE d 420 3.140000e+00 tes 35 ns 1 101- 1 101- AC F2 42 51
Recorded data: 0 0101 FALSE e 666 2.780000e+00 bik 45 ns 0 011L 0 011L B2 D3 53 30
Recorded data: 0 0101 FALSE e 666 2.780000e+00 bik 55 ns 0 011L 0 011L B2 D3 53 30
Recorded data: 1 0110 TRUE f 777 6.660000e+00 vhd 65 ns 1 001H 1 001H C1 54 XX 51
Recorded data: 1 0110 TRUE f 777 6.660000e+00 vhd 75 ns 1 001H 1 001H C1 54 XX 51
Recorded data: 0 0011 FALSE g 888 4.200000e+00 dog 85 ns 0 000W 0 000W XX 6Z 75 54
Recorded data: 0 0011 FALSE g 888 4.200000e+00 dog 95 ns 0 000W 0 000W XX 6Z 75 54
Recorded data: 1 1000 TRUE 7 1000 1.000000e-03 my 105 ns 1 010Z 1 010Z 9A 37 71 70
Recorded data: 1 1000 TRUE 7 1000 1.000000e-03 my 115 ns 1 010Z 1 010Z 9A 37 71 70
Recorded data: 1 1001 TRUE = 76000987 1.204578e+03 cat 125 ns 1 111U 1 111U EE A1 XX 17
Recorded data: 1 1001 TRUE = 76000987 1.204578e+03 cat 135 ns 1 111U 1 111U EE A1 XX 17
Recorded data: 1 1001 TRUE = 76000987 1.204578e+03 cat 145 ns 1 111U 1 111U EE A1 XX 17
Recorded data: 0 1100 FALSE % 15 8.000000e-06 slp 155 ns 0 010X 0 010X XX F1 16 51
Recorded data: 0 1100 FALSE % 15 8.000000e-06 slp 165 ns 0 010X 0 010X XX F1 16 51
Recorded data: 0 1100 FALSE % 15 8.000000e-06 slp 175 ns 0 010X 0 010X XX F1 16 51
Waveform diagram