


This is the 5th of a series exploring TensorFlow. The primary source of material used is the Udacity course "Intro to TensorFlow for Deep Learning" by TensorFlow. My objective is to document some of the things I learn along the way and perhaps interest you in a similar journey.
Recap
In previous posts regression, grey scale image categorization, and convolutional neural networks were discussed. The images used were low resolution and of a uniform size represented with a two dimensional matrix.
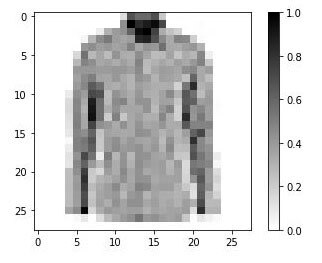
In this post the convolutional neural network concept will be expanded to cover images of different sizes and color images.
Images of Different Size
Neural networks require images of the same size. Previously the images were all low resolution grey scale of the same size with 28 x 28 = 784 pixels which were then flattened. When drawing images from different sources it is not unusual for them to be of different size and resizing is necessary. In the example below taken from the Udacity training a large image is resized down to 150 x 150 pixels.

In a previous post on facial recognition I explored the impact of image size on classification accuracy. In general, larger images should be better but this must be traded off against speed. Note that the image above has been "squished" and shortened in the horizontal dimension. While this can be done it would be better to crop to a square image in this case and then resize.
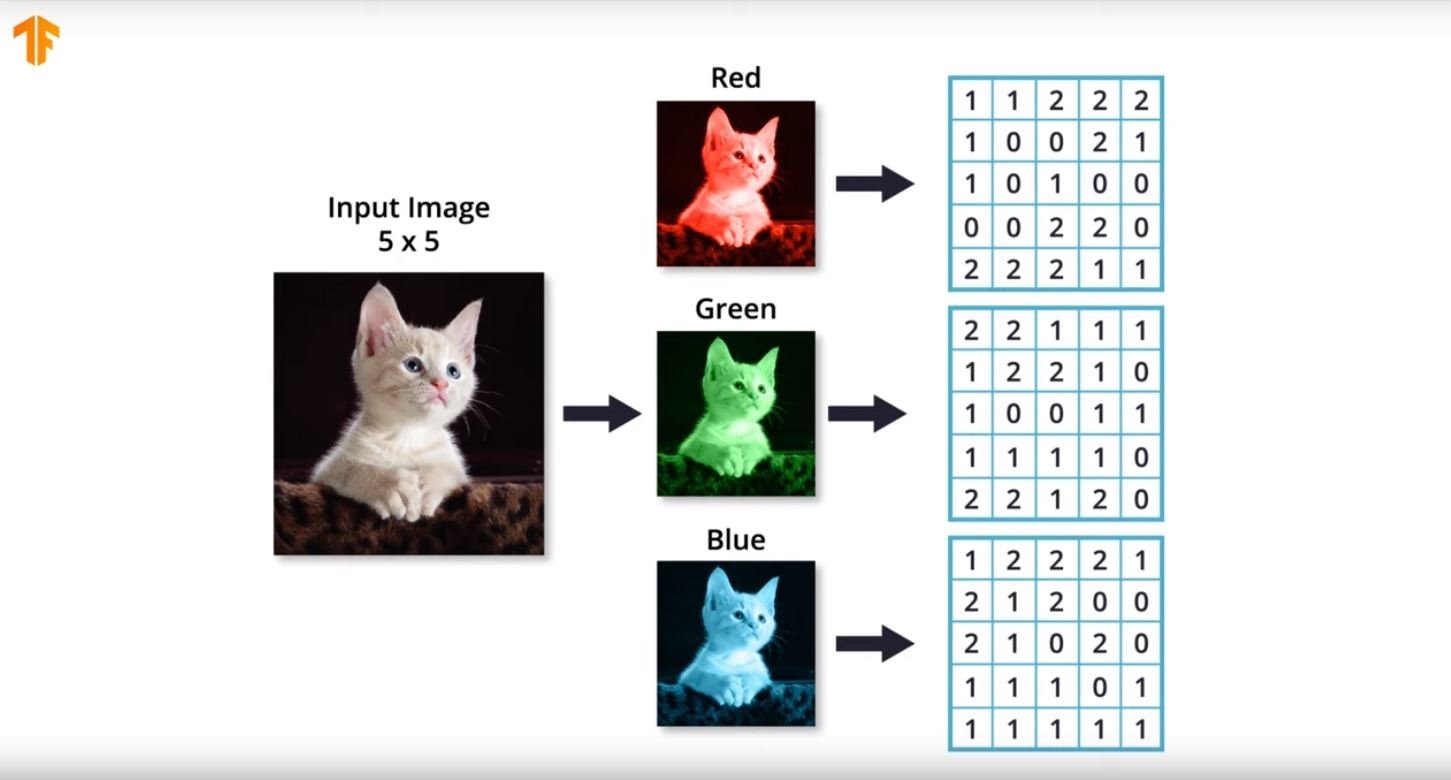
Color Image Representation
Color RGB images have 3 channels: Red, Green, and Blue. They can be represented in a 3 dimensional matrix as shown in the much simplified slide below taken from the Udacity course.
Convolution
For a color image a 3D filter (aka kernel) can be defined in a similar manner to what was done for grey scale but with 2D filters for each channel.

The convolution is then applied to pixels channel by channel. The sum of each filter is added for the pixel and a bias, typically 1, is added to make the convolved output. The edges can be padded as shown in the example below.

It is common to use more than one filter on each channel. In this case the convoluted output is multi-dimensional with the depth equal to the number of filters. In the example below the depth is 3.

While training the model, the filters are updated as the training progresses to minimize the loss function.
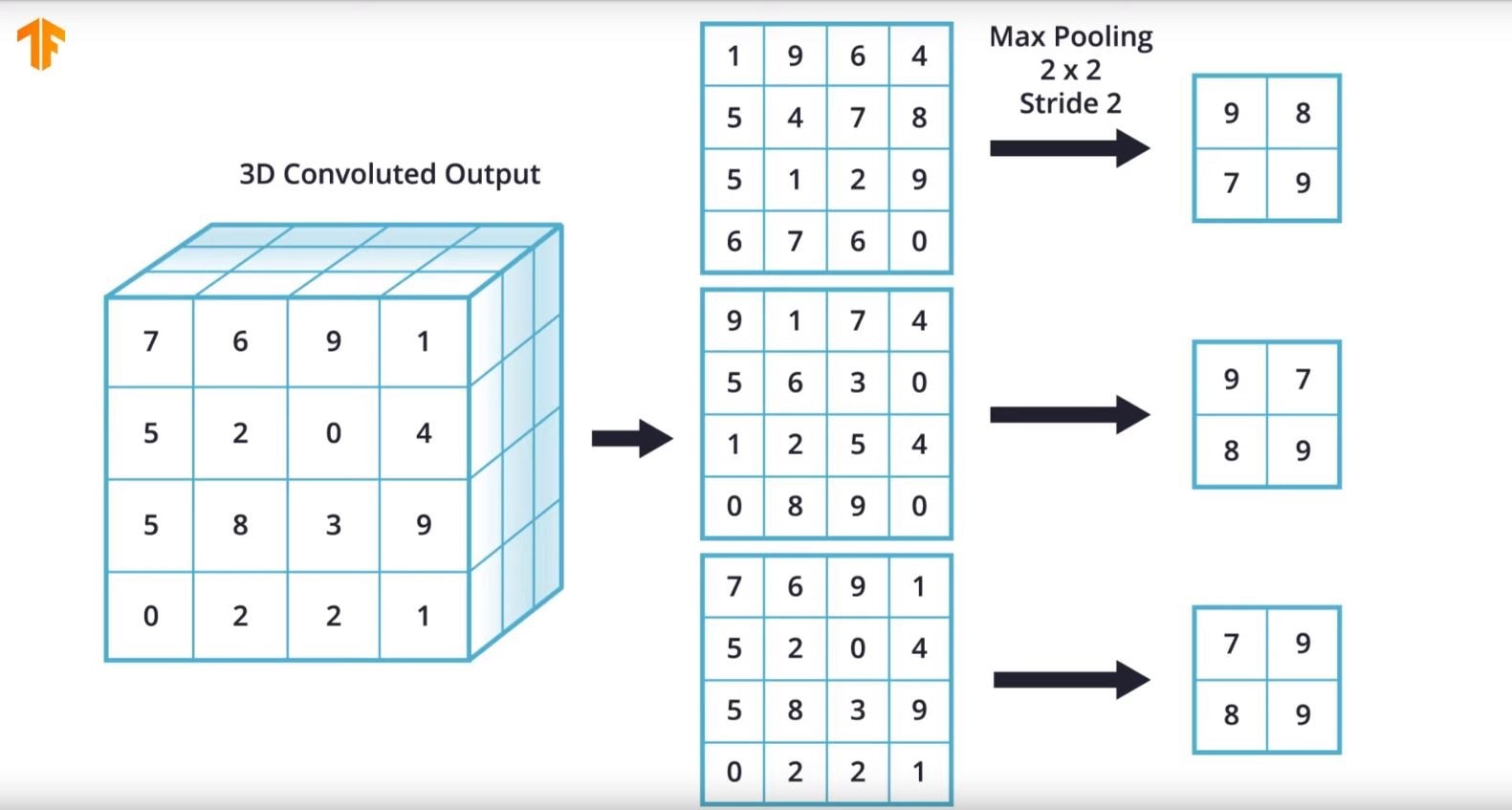
Max pooling is also used and works in a similar way to grey scale. In the example below a 2x2 window is moved across with a stride of 2 which downsizes the 4x4x3 matrix to a 2x2x3 matrix.
Validation
In the previous models a test dataset was used to determine how well the model worked after training is complete. A validation dataset checks how well a model is doing as it completes each epoch. Note that the model does not use the validation dataset to modify the weights and biases.

Validation allows us to develop a model that is accurate and general without overfitting. Since the model architecture and variables can be modified to better fit the validation dataset it is still necessary to have a dataset since the modification can develop a bias.
Developing a Model
The Colab tutorial describes how to build data input pipelines for the images but that will not be discussed here. The model classifies images of dogs and cats and the dataset is broken down as follows:
- Training: 1000 cat images
- Training: 1000 dog images
- Validation: 500 cat images
- Validation: 500 dog images
The models are getting more complicated in the training now and lengthier but conceptually are similar. To keep my posts a reasonable length I will bypass much of the code and direct you to the Udacity course instead. The first 5 images in the training dataset are shown below:

Note the squished images, partially covered images, busy backgrounds and foregrounds, kitten, and unusual stance of the dog. For general classification a large and varied dataset is required.
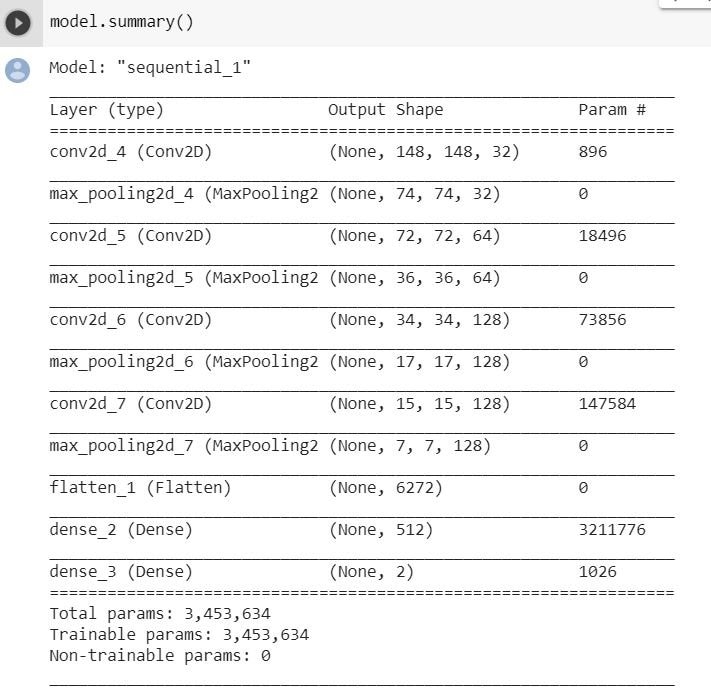
The model is shown below and should look familiar if you have been following this series:
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(2, activation='softmax')
])There are four convolutional blocks with a max pool layer. Note that the convolutional blocks start small with 32 units, followed by 64, 128, and 128. It is typical to have an increasing number of units with each layer as the detail being captured builds. Notice also that they are factors of 2 in size which is also normal. After flattening there is a dense layer with 512 neurons followed by the classification layer using SoftMax.
Compiling is done with the 'adam' optimizer as usual and the loss function is 'sparse_categorical_crossentropy'. Below is a model summary. Note that there are almost 3.5 million trainable parameters!
To demonstrate overtraining, 100 epochs are used. The resulting accuracy and loss obtained with each epoch is shown below for both the training and validation sets.
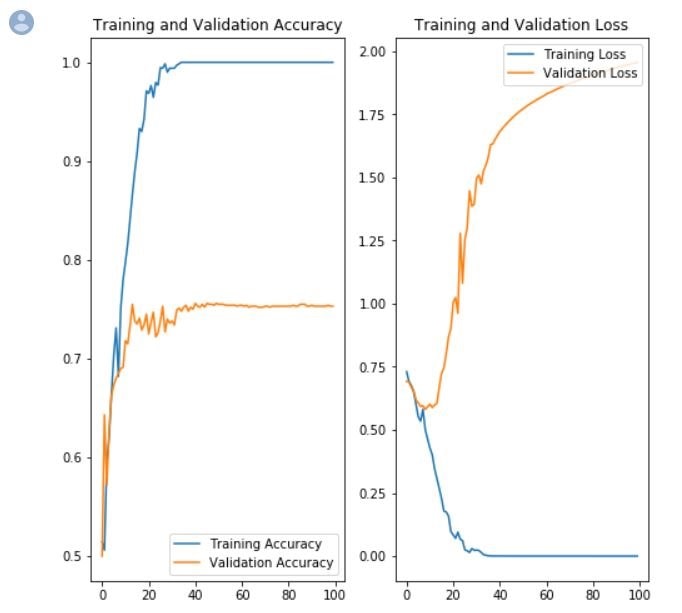
The training dataset reaches an accuracy of 1.0 (complete memorization) around epoch 20. However, the validation dataset reaches a maximum of 75% and does not improve further. In fact, the model was overtrained well before epoch 20.
Conclusions and Looking Ahead
In this post machine learning was extended to handle color and images of different sizes. The concept of validation datasets to assess how well the model is progressing during training was introduced and overtraining was discussed.
It is obvious upon reflection that it is relatively easy to train a model to memorize but less so to make it general. The ability to memorize without generality is less an issue though if the application will be for images that are very similar to the training set (at least that is my hypothesis). For example if the items being categorized are always lit in a similar way to the training dataset, oriented in the same direction, the same size, have a clean background, etc. then accuracy should be nearer 100%. The project I have in mind will take advantage of that.
In the next post the use of image augmentation and dropout to improve generalization will be explored. Thanks for reading (those few of you who are still with me - it is rather dry material :-) and as always comments and corrections are welcome.
Useful Links
RoadTest of Raspberry Pi 4 doing Facial Recognition with OpenCV
Picasso Art Deluxe OpenCV Face Detection
Udacity Intro to TensorFlow for Deep Learning
A Beginning Journey in TensorFlow #1: Regression
A Beginning Journey in TensorFlow #2: Simple Image Recognition
A Beginning Journey in TensorFlow #3: ReLU Activation
A Beginning Journey in TensorFlow #4: Convolutional Neural Networks
A Beginning Journey in TensorFlow #6: Image Augmentation and Dropout
Top Comments