


Denial of Service attacks
We have Denial of Service (DoS) protections in place now on the site. We're aware that normal end users are being affected by this (i.e. you!) and we're getting people question why this is.
I am sure some have noticed that the site is fragile and is needing regular maintenance. We have a lot more outages than we'd like, and each time there's an outage, one of the team has to come online and do something to fix it, so I'm sure you can understand this is serious to us.
Whenever there's a crash we look into it and look to see what might have caused it. There's a lot can happen to a site put on the internet and the site has a lot of code and infrastructure backing it up, and there is plenty that can go wrong. To give you the impression that there is similarity in all outages would be misleading. But there are a few patterns that we noticed in our outages.
So we put in aggressive DoS protection to attempt to mitigate against that fragility. A denial of service attack is when someone attacks the site by hitting it really fast over and over, usually on a url that the server has to work hard to respond to. This is usually hostile - someone does this to bring the site down for whatever reason, or to cause normal site protections to collapse as the servers work hard to respond to the flood of requests coming through the door. The analogy being there are so many people trying to come through the front door, perhaps nobody will notice someone sneaking in via a back door.
 This is not happening - we aren't being regularly attacked by a hacker or a script kiddy trying to take the site down (well we are sometimes, but that's not what is taking the site down). Instead it's our membership doing it. Or rather, the code the membership is running is doing it. Something in our code causes your browser to suddenly wake up and start hammering the site.
This is not happening - we aren't being regularly attacked by a hacker or a script kiddy trying to take the site down (well we are sometimes, but that's not what is taking the site down). Instead it's our membership doing it. Or rather, the code the membership is running is doing it. Something in our code causes your browser to suddenly wake up and start hammering the site.
Outage scenarios
There are a bunch of scenarios here that we've found, but before I can detail those, a little bit of background is required.
Despite the name, a web server is not a single server. It's a collection of servers that together act as a single server. At the very core of almost every website is a collection of machines that have the exact same code on them and are there to share out the load of all the traffic coming through the front door. We call these nodes, and at times when we know there will be busy traffic (like a pi launch), we can bring more nodes online to serve that increased load. We can also make this automatic, so as servers get more load, we automagically spin up additional nodes.
When you connect to the site, you're assigned a node, and that becomes yours. Anything you do is on that node, unless something happens to kick you off. You share that node with other people, but anything you do will be with your node.
One scenario that we were seeing again and again is an outage brought about following a node outage. Should a node go out for whatever reason, anyone who was using that node gets transferred over to different nodes while that node is spun down and replaced, or goes off to complain about its woes until a human comes along to give it a kick. However, when that when a client loses its node, it can _sometimes_ flail around very hard trying to find a new node, to the extent that it floods the other nodes with traffic to the point that it ends up DoSing them. Because this traffic comes from otherwise normal traffic, it can be very hard for our automated checks to spot this, that traffic is allowed through the front door, and it takes down a second node. Then we get the whole thing repeat with a new node - that spammy client doesn't stop spamming just because the second node crashed. So it now moves onto the next node, which of course now has a chunk of traffic from the previous two nodes.
Our increased DoS protection is protecting against this scenario, but that does mean that should you be caught in this scenario, you will get errors or an access denied page when you weren't doing anything wrong. This scenario is something we're actively investigating. It doesn't happen often - when a node collapses (which also doesn't happen that often), most time you'll have a seamless trip to the next node.
Another scenario that we know happens is if you're a taboholic (I am a taboholic!) and you put your laptop to sleep and then wake it up, the many tabs you have open will all try to reconnect at the same time and can cause a similar situation. The DoS protection is working against this one, and when waking up your machine, you may find a few tabs that are showing an ugly error. This isn't a big deal to us and not somewhere we're spending time or effort - people are used to weird errors bringing things back from sleep and a simple refresh will fix the issue.
The most awkward scenario though is the one that stops me from scaling back the aggressive protection. I think we have a bug in the platform that means that sometimes, you can have a tab that just decides to go haywire and suddenly get very spammy in trying to reach the site. This can happen with a single tab, and you don't have to be at your machine for it to happen. I've seen it twice on my own machine, once when I left it for 16 hours and came back to see the issue happening, and a second time earlier today while looking into what had happened to Jan Cumps . 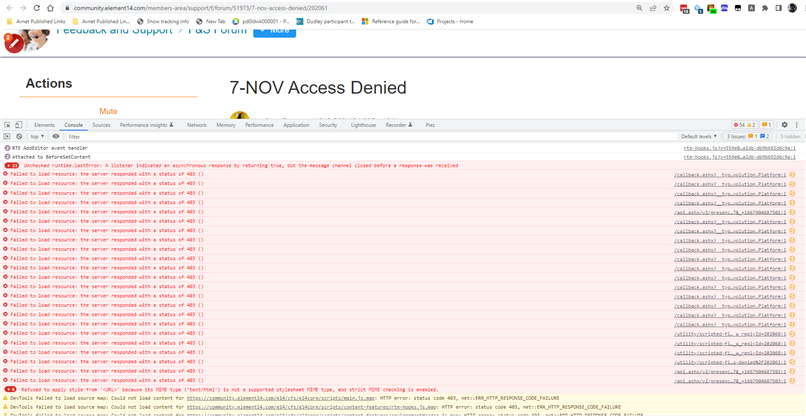
With this scenario, your tab will explode with activity (that you won't see unless you're watching for it), but unchecked, it can hit the site over 12000 times a minute with a high load request. Because you've previously been identified as friendly traffic because you're doing normal stuff, it can be difficult for us to spot this as unusual. The upgraded DoS protections in place definitely kick in for this scenario, and is almost certainly what happened to Jan in this post RE: 7-NOV Access Denied .
What are we doing about it?
So this all said, there are two questions I am here to answer for you. Should you be affected by this issue, what does it look like and what can you do about it? And has anything we've done here worked?
What does it look like? I had this earlier so I can show you what happened to me. I was looking at a screenshot when it happened behind the screenshot. I've also shown what shows in the dev console.
Should this happen to you, the first thing to understand is that it wasn't anything you did that caused it. You aren't getting this because of something you did or didn't do. This would be so much easier and simpler if it was!
The most likely scenario is that you've got a tab misbehaving, so the best thing to do is close down a few tabs (there is no guarantee that the tab you are looking at is the badly behaving tab - even if you've had a wall of errors like in my screenshot), and go make a hot drink of your choice. By the time you get back, you should be able to access the site again. Should you still have problems, maybe close down a few more tabs or restart your browser and take a second break. Anything you are halfway through posting should be saved and you should be able to jump right back in to continue what you were doing. It also might not be the device you are working on that caused the issue, the DoS protections activate against all devices on your local network.
As for if the pain and suffering this is putting you through is worth it? We're still getting outages, and it doesn't feel like we're getting less, so this was definitely not the panacea I'd hoped it might be. The pattern of one node collapses and the traffic moves on to the next node taking it down has disappeared entirely (at least to date!), so that is positive.
We can also see the times it kicks in and protects the site, and the vast majority of times it is the codebase suddenly getting spammy, so I'm happy this is having a positive effect and the protection will stay in its present form in the short term. It's certainly not true that every time you're getting this, the site would have crashed should that protection not stopped you, but it definitely stopped the issue causing others on the node to have a sluggish experience.
Next steps
We are fully aware that this is not good enough and not up to the standards you our membership ask of us.
The correct solution should be that we track down whatever it is that is causing the code you have in your browsers from suddenly getting active and hammering the site and we continue to work down that avenue. We are progressing this with Verint, but it's a complicated issue that we can't reproduce in our test environments and that makes it very difficult for us to make changes.
We are also investigating what causes nodes to randomly drop. If we can fix that, then we won't get everyone suddenly being shunted around. Breaking the chain of events means we don't get to the catastrophic end point!
Until we've made progress on these two points, the DoS protection is in to stay at its present limits. Our number one priority is site health and uptime, and we're convinced the upped DoS protection is having a positive effect on site health.
Once we get somewhere, we'll keep the protections but maybe relax the thresholds a bit.
Lastly, we are moving to make the experience nicer should you get caught in DoS protection. The ugly Reference #18 error will be going soon!
How it initially looks when you get impacted by DoS protection
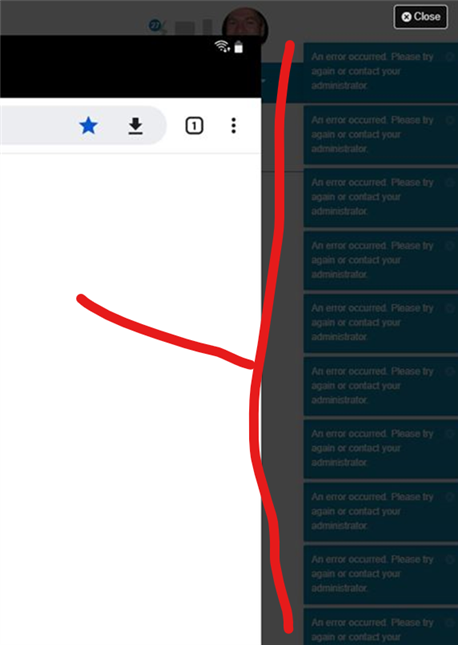
If you try to open a page, open a link, or reload the page, you'll get this (screenshot courtesy of Jan Cumps)

