RoadTest: Eclypse Z7: Zynq-7000 SoC Development Board
Author: bartokon
Creation date:
Evaluation Type: Development Boards & Tools
Did you receive all parts the manufacturer stated would be included in the package?: True
What other parts do you consider comparable to this product?: Zynq 7000 development boards.
What were the biggest problems encountered?: Poor documentation/support! I had to wait more than two weeks and write message to Digilent support to gain access to the forum.
Detailed Review:
I don't want to write specifics on this subject because Fred already done this in his review and I can't do it better than an official Digilent website 
So, What is Eclypse-Z7? In short Eclypse is Zynq-7000 SoC based development board, that can work like Arduino or Nvidia Jetson platforms. The one thing that distinguishes Zynq from other SoC's is access to programmable logic.
With it, you can do basically anything you imagine, from prototyping a design, to developing full-fledged product. Xilinx has made enormous progress in allowing software developers design they own hardware on FPGA with help of high level synthesis tools like Vitis and communicate on higher level of abstraction with PYNQ. Eclypse-Z7 want's to take advantage of this and according to Digilent it "allows new users to get started without touching hardware until desired. The software supports a variety of common programming languages, including Python, C/C++, and more." My goal is to test Eclypse-Z7 on this matter. Does it work out of the box? How does it perform? Is it a platform for new users? Let's find out...
| {gallery} Ecl |
|---|
 |
 |
Digilent provides many support materials for their development boards, so first let's take a look at getting started guide for Eclypse-Z7.
As you can see there are plenty of setup and installing guides. The first thing we should do is to set up working environment. We can follow Vivado and SDK guide. I think it is well documented and easy to follow. I had no problems installing boards and drivers, so it is a big + for Digilent.
One thing that I don't like is sometimes you can get lost in all of that documentation and loop from reference guide to reference guide.
The links you are looking for:
https://reference.digilentinc.com/reference/programmable-logic/eclypse-z7/git
https://reference.digilentinc.com/reference/zmod/zmodbaselibraryuserguide#environment_setup
Let's suppose we would like to create basic design and create petalinux for it. How we can do it?
The easiest way is to use demo one liner.
git clone https://github.com/Digilent/Eclypse-Z7 --recursive -b <demo>/master
Where <demo>:


As you can see we got 3 folders - hw, os, sw.
First we need to recreate block design from .tcl file. We need to open Vivado and in tcl console source our hw project.
After rebuilding project we have our block design ready.
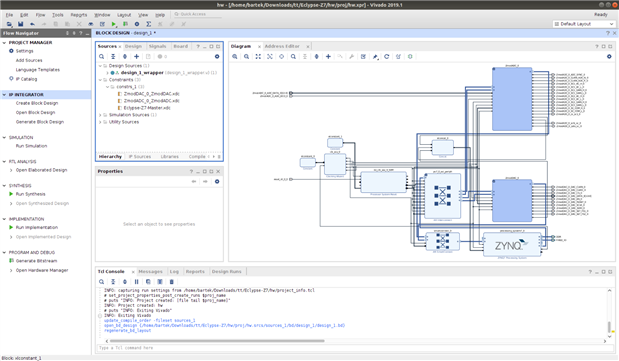
One thing I must say about this design that it is "raw" design. It does not support acceleration yet. You must manually enable platform interfaces, create clock etc... Eclypse-Z7 is considered "high level" platform but, is lacking acceleration interfaces for SDSoC/Vitis. New user without knowledge will get stuck and waste few days trying to create acceleration interfaces. I suggest creating reference guide for this kind of project (You can follow this, look for "creating the platform hardware component" and "creating the platform software component").
Now let's generate bitstream and follow the guide.
The next step "After generating a bitstream, a hardware handoff file (HDF) can be exported from Vivado through the File → Export → Export Hardware dialog in Vivado." (If you are creating acceleration platform you should export DSA, but guide doesn't mention a thing)
Let's export hdf and configure petalinux.
First we need to source petalinux 2019.1 (Not mentioned in guide) and go to "os" folder to configure petalinux project.
source <petalinux20191_install_dir/settings.sh> cd Eclypse-Z7/os petalinux-config --get-hw-description=<path exported hdf>
Also, petalinux system doesn't include decutil to control MCU. Why there isn't a proper .bbappend created for petalinux to use this is a mystery for me.
Petalinuxbsp.conf doesn't have DL_DIR and SSTATE_DIR specified, so rebuilding project will take more time because it will start from scratch, recompiling everything.
Please append these two lines to Eclypse-Z7/os/project-spec/meta-user/conf/petalinuxbsp.conf
DL_DIR = "/home/${USER}/petalinux/cache/downloads_2019.1/"
SSTATE_DIR = "/home/${USER}/petalinux/cache/sstate_2019.1/arm/"And build the project.
petalinux-build petalinux-package --boot --fsbl --fpga --uboot
That's where the guide ends. I suppose you know what files you should copy to SD-Card? How to flash SD-Card? How to prepare SD-Card for Eclypse-Z7? I know that I'm picking on details, but for me this is not new user-friendly. If you don't know how to prepare SD-Card visit petalinux reference guide page 172 (Appendix H). In my opinion the easiest way is to use "gparted". Ultimately you should aim for something like this:

| {gallery} SDCard |
|---|
 |
 |
As default file system is INITRAMFS, rootfs is volatile and all changes will be lost, that means also all files in rootfs partition (16 GB Volume) are not used. You should change root filesystem from INITRAMFS to SD card.
petalinux-config
| {gallery}Boots |
|---|
 |
 |
And rebuild project, now petalinux is ready hooray!
Debian image provided by Digilent is somehow broken. After flashing sd-card you must enter "sudo <any command>" or else you will get error. Each time after executing command with sudo you must wait +30seconds for command to execute. I suppose it is image fault, because the system that I made with petalinux works normally.
Now let's compare this workflow with Avnet's to get the same result.
git clone https://github.com/Avnet/petalinux.git -b 2020.1; git clone https://github.com/Avnet/hdl.git -b 2020.1; git clone https://github.com/Avnet/bdf.git -b master; source <Xilinx_Install_Dir/Vivado/2020.1/settings64.sh> source <Petalinux20201_Install_Dir/settings.sh> cd petalinux/scripts; ./make_some_board.sh;
I think that there is room for improvement for both of the companies. Digilent should make ./make_script.sh and Avnet should nest their GitHubs to avoid cloning the wrong version of repository. These are just a simple quality of life improvements for customers
Now let's compile ZMOD demos. Base library user guide is good and works as intended. I can't say bad thing about it, but...
Let's try to move to create custom project. Think for a second that we don't know DMA, flash etc. addresses. We have our custom hardware platform. Traditionally let's follow the guide.
Changing HDF for petalinux project doesn't change a thing, beacuse we are appedning to existing phandles. Device-tree compiler will find proper field for ZMOD's and apply changes.
If we made some changes to the original name of ZMOD's we could be in trouble, this is not the problem that is just how DTC works.
&ZmodADC_0_AXI_ZmodADC1410_1 {
compatible = "generic-uio";
};
&ZmodDAC_0_AXI_ZmodDAC1411_v1_0_0 {
compatible = "generic-uio";
};
&amba_pl {
axidma_chrdev_0: axidma_chrdev@0 {
compatible = "xlnx,axidma-chrdev";
dmas = <&ZmodADC_0_axi_dma_0 0>;
dma-names = "rx_channel";
index = <0>;
};
axidma_chrdev_1: axidma_chrdev@1 {
compatible = "xlnx,axidma-chrdev";
dmas = <&ZmodDAC_0_axi_dma_1 0>;
dma-names = "tx_channel";
index = <1>;
};
};System boots and axidma's are visible in /dev/ directory.

First we need to find IP base address. According to guide (2.1.1 IP Core Related Functionality):
Let's try it.

We have ZmodADC1410 base IP address. Now it is time for AXI_DMA. (2.1.2. AXI DMA Related Functionality)
"...The initialization function takes the AXI DMA base address and the AXI DMA interrupt number as parameters..."

So AXI DMA address is the same as Zmod's? There must be some mistake in documentation, and now we are forced to search elsewhere for DMA base address for example device-tree.

It is time for IIC adress (2.1.3. Flash Related Functionality)

Okay but for using library we need also DAC flash address and DMA IRQ
#define DAC_BASE_ADDR 0x43C10000 //Found #define DAC_DMA_BASE_ADDR 0x40410000 //Found in device-tree #define IIC_BASE_ADDR 0xE0005000 //Found #define DAC_FLASH_ADDR 0x31 //???? #define DAC_DMA_IRQ 63 //???? ?(-1)? ZMODDAC1411 dacZmod(DAC_BASE_ADDR, DAC_DMA_BASE_ADDR, IIC_BASE_ADDR, DAC_FLASH_ADDR, DAC_DMA_IRQ);
As you can the guide is clearly lacking something, you can't find some basic parameters for ZMOD class. Maybe they are constants, but I still didn't find a word in documentation about this. I know this will be fixed soon as somebody will look at this review. Let's keep our fingers crossed.
What about using PYNQ?
I have created porting guide, so you could try it on your own
https://www.hackster.io/bartosz-rycko/eclypse-z7-pynq-porting-guide-3dd24c
The only problem I have encountered is lack of documentation on how can I integrate ZMOD's with device-tree-overlay. I have found some workaround but, still after running basic ZMOD example on overlay, I'm getting segmentation fault.
First design had some issues with GPIO, but I think the issue is board definition from Vivado, because in the next overlay I have manually sliced GPIO pins, used constrains file and as you can see let there be light!
These led's are really bright and as you can see each is tri-color!
Porting PYNQ to Eclypse-Z7 was an easy task, even upgrading to petalinux project to 2020.1. Upgrading 2019.1 Vivado ZMOD project will lead to issues with ZMOD ip'cores, the cores are locked and upgrading them to the latest version of Vivado, changes internal axi clock speed and that could lead to timing problems with ZMOD DMA's.
Before I have started developing this project, I had to think about the workflow. How should I start? What is the best way to work with PYNQ? I have come to a conclusion that I will start by building software only solution and then use it as go to design, then move some calculations to PL. Let me show you what I have done right and what went wrong
The first step was to develop simple neural network with help of Python. This was a great opportunity to learn how neural networks work and what are the disadvantages of using one. I have found a great tutorial that explains how neural network works and how to implement backpropagation.
As this was my first project besides creating petalinux systems and running examples this was somehow a challenge  The initial thought was to take ready list of weights and create neural network based on it. At this moment I didn't think much how should I implement this. Now after the project is somehow ready I know I have made some major mistakes. This design is not flexible by any way... You can just use "rectangle" two-layer neural network without problems but adding more type of layers need higher level of abstraction. Each layer should be independent to one another and linked to next layer that propagates, that means adding more information about activation functions, derivatives, internal layer linkage and type of previous layers. This kind of design would expand gradually and I don't think I would have been able to do it in two months.
The initial thought was to take ready list of weights and create neural network based on it. At this moment I didn't think much how should I implement this. Now after the project is somehow ready I know I have made some major mistakes. This design is not flexible by any way... You can just use "rectangle" two-layer neural network without problems but adding more type of layers need higher level of abstraction. Each layer should be independent to one another and linked to next layer that propagates, that means adding more information about activation functions, derivatives, internal layer linkage and type of previous layers. This kind of design would expand gradually and I don't think I would have been able to do it in two months.
class nn:
weights = list()
#dnet/dw -> dnetL1/dw5 x.outputs[0][0]
outputs = list()
#dout/dnet -> doutL1/dnetL1 outputs_transfer_derivative[1][0]
outputs_transfer_derivative = list()
inputs = list()
def __init__(self, weights):
self.weights = np.array(weights, dtype=np.float32)
layers_count, neurons_count, weights_count = self.weights.shape
self.outputs = np.zeros((layers_count, neurons_count), dtype=np.float32)
self.outputs_transfer_derivative = self.outputs.copy()
def transfer_derivative(self, output):
if output > 0:
return 1
else:
return 0
#return output*(1-output)
def activation_function(self, output):
if output > 0:
return output
else:
return 0.000001
#return 1/(1+np.exp(-output))
def calculate_error(self, target):
target = np.array(target, dtype=np.float32)
target_size = target.shape[0]
buf = 0
for i in range(target_size):
buf = buf + ((self.outputs[self.outputs.shape[0]-1][i] - target[i])**2)/2
return buf
def output_error(self, target):
target = np.array(target, dtype=np.float32)
target_size = target.shape[0]
buf = np.zeros(target.shape)
for i in range(target_size):
buf[i] = (self.outputs[self.outputs.shape[0]-1][i] - target[i])
return buf
def calculate_delta_outputs(self, target, neuron_nb):
buf = self.output_error(target)
s = 0
for w in range(self.weights.shape[0]):
wyn = buf[w]*self.outputs_transfer_derivative[self.weights.shape[0]-1][w]*self.weights[self.weights.shape[0]-1][w][neuron_nb]
s = s + wyn
buf[w] = wyn
return buf
#{l}{n}{w}
def forward_propagate(self, inputs):
output_buf = inputs
layers_count, neurons_count, weights_count = self.weights.shape
self.inputs = inputs
#krnl
for l in range(layers_count):
for_prop = output_buf.copy()
for n in range(neurons_count):
activation_value = 0
for w in range(weights_count-1):
activation_value = activation_value + self.weights[l][n][w] * output_buf[w]
activation_value = activation_value + self.weights[l][n][w+1]
for_prop[n] = self.activation_function(activation_value)
self.outputs_transfer_derivative[l][n] = self.transfer_derivative(for_prop[n])
output_buf = for_prop.copy()
self.outputs[l][:] = output_buf.copy()
#krnl
def backpropagationG(self, target, lr):
layers_count, neurons_count, weights_count = self.weights.shape
wnew = self.weights.copy()
self.outputs = np.insert(self.outputs, 0, values=self.inputs, axis=0)
#krnl
l = layers_count
en = self.output_error(target)
#krnl
for n in range(neurons_count):
for w in range(weights_count-1):
wnew[l-1][n][w] = self.weights[l-1][n][w] - lr*en[n] * self.outputs_transfer_derivative[l-1][n] * self.outputs[l-1][w] #self.outputs[l-1][w]
l = layers_count-1
for n in range(neurons_count):
en = self.calculate_delta_outputs(target, n)
for w in range(weights_count-1):
wnew[l-1][n][w] = self.weights[l-1][n][w] - lr* sum(en) * self.outputs_transfer_derivative[l-1][n] * self.outputs[l-1][w] #self.outputs[l-1][w]
#krnl
self.outputs = np.delete(self.outputs, 0, axis=0)
self.weights = wnew.copy()
def nn_software_trainer(self, iterations, lr):
img_white_vector = np.ones((self.inputs.shape), np.float32)
img_black_vector = np.zeros((self.inputs.shape), np.float32)
inputsw = img_white_vector
goldenw = np.array([3 for i in range(img_white_vector.shape[0])])
inputsb = img_black_vector
goldenb = np.array([0 for i in range(img_black_vector.shape[0])])
errordataw = {}
errordatab = {}
for i in range(iterations):
clear_output(wait=True)
self.forward_propagate(inputsw)
self.backpropagationG(goldenw, lr)
errordataw[i]=(self.calculate_error(goldenw))
print(f"ERRORZw: {i} {self.calculate_error(goldenw)}")
print(f"Max of outputs: {np.average(self.outputs[1])}")
self.forward_propagate(inputsb)
self.backpropagationG(goldenb, lr)
errordatab[i]=(self.calculate_error(goldenb))
print(f"ERRORZb: {i} {self.calculate_error(goldenb)}")
print(f"Max of outputs: {np.average(self.outputs[1])}")
lists = sorted(errordataw.items()) # sorted by key, return a list of tuples
x, y = zip(*lists) # unpack a list of pairs into two tuples
plt.plot(x, y)
plt.xlabel('iteration')
plt.ylabel('loss')
plt.show()
lists = sorted(errordatab.items()) # sorted by key, return a list of tuples
x, y = zip(*lists) # unpack a list of pairs into two tuples
plt.plot(x, y)
plt.xlabel('iteration')
plt.ylabel('loss')
plt.show()
So with the base design ready, I have marked calculations that I could move to PL with #krnl and created few accelerators with Vivado HLS. Working with HLS was pleasant. I have managed to create accelerators that use DMA, s_axi and m_axi interfaces which was good opportunity to learn how to use them with PYNQ. There were few problems I have encountered. Can you see //Addon in back_propagate__L2_N? Original function just changed buffer physical address in python but that leads to some kind of errors and kernel would crash after 3-4 calls (But backpropagation means even thousands of iterations!). M_axi interfaces have issues with pointer arithmetic, if for example in HLS you would define array arr[64][32] and in python just allocate space for arr[32][32] accelerator wouldn't work, even if you define arrays [x][y] with arguments passed to function interface for example like m_lay or m_neu. Now with this //Addon kernel handles all the m_axi transactions properly and is working fine.
#include "hls_stream.h"
#include "ap_axi_sdata.h"
#define MAX_NEURONS 768
#define MAX_LAYERS 2
float activation_function(float x, float leak){
#pragma HLS INLINE off
if (x > 0) {
return x;
}
else {
return leak;
}
}
bool transfer_derivative(float x){
if (x > 0) {
return 1;
}
else {
return 0;
}
}
template<int D,int U,int TI,int TD>
struct ap_axiu_my{
float data;
ap_uint<(D+7)/8> keep;
ap_uint<(D+7)/8> strb;
ap_uint<U> user;
ap_uint<1> last;
ap_uint<TI> id;
ap_uint<TD> dest;
};
typedef ap_axiu_my<32,1,1,1> custom_stream;
void calc_error(custom_stream *nn_out, custom_stream *target, custom_stream *out){
#pragma HLS INTERFACE ap_ctrl_none port=return
#pragma HLS INTERFACE axis port=nn_out
#pragma HLS INTERFACE axis port=target
#pragma HLS INTERFACE axis port=out
out->data = nn_out->data - target->data;
out->dest = nn_out->dest;
out->id = nn_out->id;
out->keep = nn_out->keep;
out->last = nn_out->last;
out->strb = nn_out->strb;
out->user = nn_out->user;
};
void forward_propagate_L2_N(int m_lay, int m_neu, float leak, float weight[MAX_LAYERS][MAX_NEURONS][MAX_NEURONS+1], float output[MAX_LAYERS+1][MAX_NEURONS]){
#pragma HLS INTERFACE s_axilite port=return bundle=ctrl
#pragma HLS INTERFACE ap_ctrl_hs port=return bundle=ctrl
#pragma HLS INTERFACE m_axi port=weight offset=slave bundle=weights
#pragma HLS INTERFACE m_axi port=output offset=slave bundle=outputs
#pragma HLS INTERFACE s_axilite port=m_lay bundle=ctrl
#pragma HLS INTERFACE s_axilite port=m_neu bundle=ctrl
#pragma HLS INTERFACE s_axilite port=leak bundle=ctrl
#pragma HLS INTERFACE s_axilite port=weights bundle=ctrl
#pragma HLS INTERFACE s_axilite port=output bundle=ctrl
float leak_loc = leak;
float activation_value;
for (unsigned int l = 0; l < m_lay; l++){
for (unsigned int n = 0; n < m_neu; n++){
activation_value = 0;
for (int w = 0; w < m_neu; w++){
#pragma HLS PIPELINE
activation_value = activation_value + weight[l][n][w] * output[l][w];
}
activation_value = activation_value + weight[l][n][m_neu];
output[l+1][n] = activation_function(activation_value, leak_loc);
}
}
};
void back_propagate_L2_New(unsigned int m_lay, unsigned int m_neu, float learning_rate, float weight[MAX_LAYERS][MAX_NEURONS][MAX_NEURONS+1],
float new_weight[MAX_LAYERS][MAX_NEURONS][MAX_NEURONS+1], float output[MAX_LAYERS][MAX_NEURONS], float en[MAX_NEURONS]){
#pragma HLS INTERFACE s_axilite port=return bundle=ctrl
#pragma HLS INTERFACE m_axi port=weight offset=slave bundle=weights depth=1024
#pragma HLS INTERFACE m_axi port=output offset=slave bundle=outputs depth=1024
#pragma HLS INTERFACE s_axilite port=weight bundle=ctrl
#pragma HLS INTERFACE s_axilite port=output bundle=ctrl
#pragma HLS INTERFACE m_axi port=new_weight offset=slave bundle=new_weights depth=1024
#pragma HLS INTERFACE s_axilite port=new_weight bundle=ctrl
#pragma HLS INTERFACE m_axi port=en offset=slave bundle=ens depth=64
#pragma HLS INTERFACE s_axilite port=en bundle=ctrl
#pragma HLS INTERFACE s_axilite port=m_lay bundle=ctrl
#pragma HLS INTERFACE s_axilite port=m_neu bundle=ctrl
#pragma HLS INTERFACE s_axilite port=learning_rate bundle=ctrl
float local_learning_rate = learning_rate;
unsigned int local_m_lay = m_lay;
unsigned int local_m_neu = m_neu;
for (unsigned int n = 0; n < local_m_neu; n++){
#pragma HLS LOOP_TRIPCOUNT min=8 max=768
for (unsigned int w = 0; w < local_m_neu; w++){
#pragma HLS PIPELINE
#pragma HLS LOOP_TRIPCOUNT min=8 max=768
new_weight[local_m_lay-1][n][w] = weight[local_m_lay-1][n][w] - local_learning_rate * en[n] * transfer_derivative(output[local_m_lay-1][n]) * output[local_m_lay-1][w];
}
}
for (unsigned int n = 0; n < m_neu; n++){
float wyn = 0;
#pragma HLS LOOP_TRIPCOUNT min=8 max=768
for (unsigned int w = 0; w < m_neu; w++){
#pragma HLS LOOP_TRIPCOUNT min=8 max=768
#pragma HLS PIPELINE
wyn = wyn + en[w]*transfer_derivative(output[local_m_lay-1][w])*weight[local_m_lay-1][w][n];
}
for (unsigned int w = 0; w < m_neu; w++){
#pragma HLS PIPELINE
#pragma HLS LOOP_TRIPCOUNT min=8 max=768
new_weight[local_m_lay-2][n][w] = weight[local_m_lay-2][n][w] - local_learning_rate * wyn * transfer_derivative(output[local_m_lay-2][n])* output[local_m_lay-2][w];
}
}
//Addon
for (unsigned int l = 0; l < m_lay; l++){
#pragma HLS LOOP_TRIPCOUNT min=2 max=2
for (unsigned int n = 0; n < m_neu; n++){
#pragma HLS LOOP_TRIPCOUNT min=8 max=768
for (unsigned int w = 0; w < m_neu+1; w++){
#pragma HLS PIPELINE
#pragma HLS LOOP_TRIPCOUNT min=8 max=769
weight[l][n][w] = new_weight[l][n][w];
}
}
}
//EndOfAddon
};
With exported IP's I have connected them in Vivado project like this:
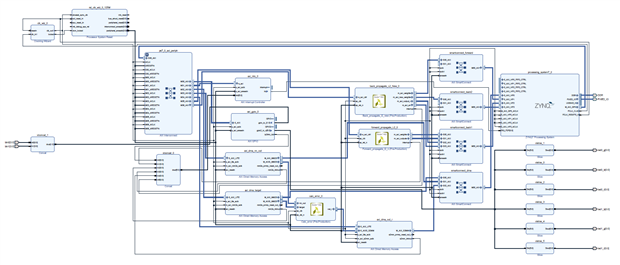
Button and LED's Constrains:

This design is in attachments named design_1.pdf. I have generated bitstream and copied .hwh and .bit to Eclypse-Z7 running PYNQ.
Now with proper design ready I modified "nn" class to use programmable logic instead of CPU.
class nn_hw_accel:
#31 speedup (192 image vector)
def __init__(self, weights):
self.nn_overlay = Overlay("/home/xilinx/jupyter_notebooks/design_neural.bit")
print("Turning off leds...")
self.led_0_control(0)
self.led_1_control(0)
print("Translating weight list to numpy array...")
self.w_state = 0
w = np.array(weights, dtype=np.float32)
layers_count, neurons_count, weights_count = w.shape
self.layers_count = layers_count
self.neurons_count = neurons_count
self.weights_count = weights_count
print("Allocating dma...")
self.target = allocate(shape=(768), dtype=np.float32)
self.calc_error = allocate(shape=(768), dtype=np.float32)
print("Allocating weights...")
self.weights_new = allocate((2, 768, 769), dtype=np.float32)
self.weights = allocate((2, 768, 769), dtype=np.float32)
for x in range(w.shape[0]):
for y in range(w.shape[1]):
for z in range(w.shape[2]):
self.weights[x][y][z]=weights[x][y][z]
self.weights_new[x][y][z]=weights[x][y][z]
print("Allocating neural network outputs...")
self.outputs = allocate(shape=(3, 768), dtype=np.float32)
print("Setting physical adresses for IP's")
print("Forward propagation IP")
lk = self.float_to_uint(0.0)
self.nn_overlay.forward_propagate_L2_0.register_map.leak = lk
self.nn_overlay.forward_propagate_L2_0.register_map.weight = self.weights.physical_address
self.nn_overlay.forward_propagate_L2_0.register_map.output_r = self.outputs.physical_address
self.nn_overlay.forward_propagate_L2_0.register_map.m_lay = layers_count
self.nn_overlay.forward_propagate_L2_0.register_map.m_neu = neurons_count
print("Back propagation IP")
self.nn_overlay.back_propagate_L2_New_0.register_map.m_lay = layers_count
self.nn_overlay.back_propagate_L2_New_0.register_map.m_neu = neurons_count
self.nn_overlay.back_propagate_L2_New_0.register_map.new_weight = self.weights_new.physical_address
self.nn_overlay.back_propagate_L2_New_0.register_map.weight = self.weights.physical_address
self.nn_overlay.back_propagate_L2_New_0.register_map.output_offset = self.outputs.physical_address
self.nn_overlay.back_propagate_L2_New_0.register_map.en_offset = self.calc_error.physical_address
print("Finished")
def calculate_error(self, target):
target = np.array(target, dtype=np.float32)
target_size = target.shape[0]
buf = 0
for i in range(target_size):
buf = buf + ((self.outputs[2][i] - target[i])**2)/2
return buf
def output_error(self):
self.nn_overlay.axi_dma_target.sendchannel.transfer(self.target)
self.nn_overlay.axi_dma_nn_out.sendchannel.transfer(self.outputs[2])
self.nn_overlay.axi_dma_out_r.recvchannel.transfer(self.calc_error)
self.nn_overlay.axi_dma_nn_out.sendchannel.wait()
self.nn_overlay.axi_dma_target.sendchannel.wait()
self.nn_overlay.axi_dma_out_r.recvchannel.wait()
#free running kernel
def float_to_uint(self, f):
return int(struct.unpack('<I', struct.pack('<f', f))[0])
def uint_to_float(self, f):
return float(struct.unpack('<f', struct.pack('<I', f))[0])
def backpropagationG(self, targ, lr):
for i in range(targ.shape[0]):
self.target[i] = targ[i]
#krnl_dma
self.output_error()
#krnl_dma
#krnl
le_lr = self.float_to_uint(lr)
self.nn_overlay.back_propagate_L2_New_0.register_map.learning_rate = le_lr
self.nn_overlay.back_propagate_L2_New_0.register_map.CTRL.AP_START = 1
#krnl
while True:
done_idle = self.nn_overlay.back_propagate_L2_New_0.register_map.CTRL.AP_IDLE
done_start = self.nn_overlay.back_propagate_L2_New_0.register_map.CTRL.AP_START
if (done_idle == 1 and done_start == 0):
break
print(f"Waiting...")
def forward_propagate(self, inputs):
inputs = np.array(inputs, dtype=np.float32)
for x in range(inputs.shape[0]):
self.outputs[0][x] = inputs[x]
#krnl
self.nn_overlay.forward_propagate_L2_0.register_map.CTRL.AP_START = 1
#krnl
def led_1_control(self, to_leds):
#Use this to manipulate leds
actual_led_vals = self.nn_overlay.axi_gpio_0.channel2.read()
led_val = (actual_led_vals & 0b000111) | to_leds << 3
self.nn_overlay.axi_gpio_0.channel2.write(led_val, 0xffffff)
def led_0_control(self, to_leds):
#Use this to manipulate leds
actual_led_vals = self.nn_overlay.axi_gpio_0.channel2.read()
led_val = (actual_led_vals & 0b111000) | to_leds
self.nn_overlay.axi_gpio_0.channel2.write(led_val, 0xffffff)
def button_0_control(self):
button_status = self.nn_overlay.axi_gpio_0.channel1.read()
return button_status
and created few helper functions to setup camera
def setup_camera():
for id in range(8):
camera_module = cv2.VideoCapture(id)
if (camera_module.isOpened() == True):
return camera_module
else:
print(f"No camera found on {id}...")
continue
raise Exception("No camera has been found or camera is already connected")
def get_camera_frame(camera_module, width = 32, height = 32):
dsize = (width, height)
failed = 0
while True:
ret, frame = camera_module.read()
if (ret == False):
print("Failed to get frame!")
failed += 1
clear_output(wait=True)
time.sleep(0.5)
if (failed > 8):
break
else:
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
resized_frame = cv2.resize(frame, dsize)
return resized_frame
def normalise_image(image):
#Image normalisation
image = image/255
return image
def show_image(image):
plt.imshow(image)
plt.show()
#print(f"frame.shape: {frame.shape}")
def generate_weights_based_on_image(img_vector):
w = np.empty(shape=(2, img_vector.shape[0], img_vector.shape[0]+1), dtype=np.float32)
for l in range(w.shape[0]):
for n in range(w.shape[1]):
w[l][n] = np.random.uniform(low=0.01, high=0.2, size=(w.shape[2],))
return w
Now we are ready to go. First we need to load necessary python packages.
import cv2 import numpy as np import os import time from IPython.display import clear_output import matplotlib.pyplot as plt from random import randrange import pynq from pynq import Overlay from pynq import allocate import struct
And test new design
#This is for camera learning :)
cam_module = setup_camera()
#Gaussian blur
kernel = np.ones((5,5),np.float32)/25
#Flatten image and normalise
image = get_camera_frame(cam_module, width = 16, height = 16)
img_vector = np.reshape(image.astype(np.float32), -1)
img_vector = normalise_image(img_vector)
print(f"Image shape: {img_vector.shape[0]}")
#Generate weights
weights = generate_weights_based_on_image(img_vector)
xn = nn_hw_accel(weights)
goldenw = np.array([3 for i in range(img_vector.shape[0])], dtype=np.float32)
goldenb = np.array([0 for i in range(img_vector.shape[0])], dtype=np.float32)
while True:
#time.sleep(0.1)
clear_output(wait=True)
image = get_camera_frame(cam_module, width = 16, height = 1)
image = cv2.filter2D(image,-1,kernel)
img_vector = np.reshape(image.astype(np.float32), -1)
img_vector = normalise_image(img_vector)
xn.forward_propagate(img_vector)
#If button one is pressed learn new image pattern to light up leds
if (xn.button_0_control() == 1):
#blue led will light up to learn "white" pattern
print("White")
xn.led_1_control(to_leds=1)
xn.backpropagationG(goldenw, 0.01)
elif (xn.button_0_control() == 2):
#green led will light up to learn "black" pattern
print("Black")
xn.led_1_control(to_leds=2)
xn.backpropagationG(goldenb, 0.01)
elif (xn.button_0_control() == 3):
xn.led_1_control(to_leds=0b000)
break
else:
xn.led_1_control(to_leds=0b000)
to_L = np.int(np.round(np.average(xn.outputs[2][0:img_vector.shape[0]])))
if (to_L > 3):
to_L = 3
elif (to_L < 0):
to_L = 0
xn.led_0_control(to_leds=to_L)
print(f"To leds: {to_L}")
print(f"NN: {np.average(xn.outputs[2][0:img_vector.shape[0]])}")It work's like this:


If you hold button 0, neural network will be trained to recognize flatten image vector and light up led based on rounded neural network output.
If you hold button 1, neural network will be trained when it should turn off led's.
If you hold both of buttons program stops. If you just interrupted jupyter-notebook, the PL-server could crash and the only option left is to reboot whole system.
Before learning:

After learning:
FPGA's bring great processing power to exploit, even without previous experience and much code refactoring I have managed to speedup software system more than x30 times. I think with different approach to the problem you could get even better results. The FPGA bottleneck is data transfer, it doesn't have enough capacity to hold all the neural network weights so you are forced to use PS dram, on the other hand all the calculations can be parallelized and executed in few clock cycles. I think the best approach is to prepare data in sequential matter, even if that means some time is wasted on preparing it and then use DMA's to offload processor. While DMA is doing heavy lifting, processing system could prepare another batch of data asynchronously and send it to the buffer.
I think Eclypse-Z7 as an development board is good product, it was designed to be modular platform that you can modify by adding PMOD's and ZMOD's. As for now there have been only a few ZMOD's released which puts Eclypse-Z7 in weird position. This isn't a starter nor a hi-end board. I couldn't gain access to Digilent forums and for now support didn't respond to my questions about PYNQ integration with ZMOD's. I think that in future this situation will change and I will successfully integrate DAC/ADC with neural network. Digilent should update more frequent their github repositories, because as the time passes the next version of Vivado will be released and these tutorial will become more and more outdated.
My goal was to test Eclypse-Z7 as HLS acceleration platform with ZMOD's, I can say that the project was fun to make and I have learned so many new things about PYNQ and HLS. The biggest obstacle was to integrate Zmods with PYNQ. Without necessary skills and tutorials this is a problem that I couldn't overcome yet... probably I could rewrite whole library to support ZMOD's but I think that's not the point of the roadtest. I would like to say thank you to Diligent and rscasny for giving me a change to develop as an Engineer and learn more things about FPGA and ZYNQ. This was a great journey. Thank you for choosing me as a new roadtester.
Bartosz Rycko.





