


In previous blogs, all of the major components of the system were implemented, all that’s left is to write some code to tie everything together.
DPU over ZMQ
As the Arty Z7 will be connected over Ethernet, I need a way to send it images, and get back detections. I landed on the usual choice, ZeroMQ. There is a C++ wrapper library available for libzmq called cppzmq, which simplifies usage even further.
I used the provided inference example C++ code as a starting point. ZMQ is then used to listen on a socket, receive JPEG encoded images, load the image, do inference using the DPU, then send the detections back as JSON.
#include <algorithm>
#include <vector>
#include <atomic>
#include <queue>
#include <iostream>
#include <fstream>
#include <iomanip>
#include <chrono>
#include <mutex>
#include <zconf.h>
#include <thread>
#include <sys/stat.h>
#include <dirent.h>
#include <iomanip>
#include <iosfwd>
#include <memory>
#include <string>
#include <utility>
#include <csignal>
#include <math.h>
#include <arm_neon.h>
#include <opencv2/opencv.hpp>
#include <dnndk/n2cube.h>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/opencv.hpp>
#include "zmq.hpp"
#include "zmq_addon.hpp"
using namespace std;
using namespace cv;
using namespace std::chrono;
// confidence and threshold
#define CONF 0.5
#define NMS_THRE 0.1
// dpu kernel info
#define YOLOKERNEL "yolo"
#define INPUTNODE "conv2d_1_convolution"
vector<string> outputs_node = {"conv2d_59_convolution", "conv2d_67_convolution", "conv2d_75_convolution"};
// yolo parameters
const int classification = 59;
const int anchor = 3;
vector<float> biases{116, 90, 156, 198, 373, 326, 30, 61, 62, 45, 59, 119, 10, 13, 16, 30, 33, 23};
vector<string> class_names = {
"bike_green", "bike_red", "bike_redyellow", "bike_yellow", "caution", "city_begin", "city_end", "height_limit", "left_prohibited", "license_plate", "main_route", "main_route_end", "overtake_prohibited", "overtake_prohibited_end", "pedestrian_crossing", "pedestrian_crossing_early", "prohibited", "region", "right_prohibited", "speedlimit100", "speedlimit110", "speedlimit120", "speedlimit20", "speedlimit30", "speedlimit30_zone", "speedlimit30_zone_end", "speedlimit40", "speedlimit50", "speedlimit60", "speedlimit70", "speedlimit80", "speedlimit_end", "stop", "trafficlight_green", "trafficlight_green_forward", "trafficlight_green_left", "trafficlight_green_leftforward", "trafficlight_green_right", "trafficlight_green_rightforward", "trafficlight_red", "trafficlight_red_forward", "trafficlight_red_left", "trafficlight_red_leftforward", "trafficlight_red_right", "trafficlight_red_rightforward", "trafficlight_red_turnaround", "trafficlight_redyellow", "trafficlight_redyellow_forward", "trafficlight_redyellow_left", "trafficlight_redyellow_leftforward", "trafficlight_redyellow_right", "trafficlight_redyellow_rightforward", "trafficlight_yellow", "trafficlight_yellow_forward", "trafficlight_yellow_left", "trafficlight_yellow_leftforward", "trafficlight_yellow_right", "trafficlight_yellow_rightforward", "yield"};
// ANSI escape codes for text colors
#define ANSI_COLOR_RED "\x1b[31m"
#define ANSI_COLOR_GREEN "\x1b[32m"
#define ANSI_COLOR_YELLOW "\x1b[33m"
#define ANSI_COLOR_BLUE "\x1b[34m"
#define ANSI_COLOR_MAGENTA "\x1b[35m"
#define ANSI_COLOR_CYAN "\x1b[36m"
#define ANSI_COLOR_RESET "\x1b[0m"
class image
{
public:
int w;
int h;
int c;
float *data;
image(int ww, int hh, int cc, float fill) : w(ww), h(hh), c(cc)
{
data = new float[h * w * c];
for (int i = 0; i < h * w * c; ++i)
data[i] = fill;
};
void free() { delete[] data; };
};
void detect(vector<vector<float>> &boxes, vector<float> result, int channel, int height, int weight, int num, int sh, int sw);
image load_image_cv(const cv::Mat &img);
image letterbox_image(image im, int w, int h);
void get_output(int8_t *dpuOut, int sizeOut, float scale, int oc, int oh, int ow, vector<float> &result)
{
vector<int8_t> nums(sizeOut);
memcpy(nums.data(), dpuOut, sizeOut);
for (int a = 0; a < oc; ++a)
{
for (int b = 0; b < oh; ++b)
{
for (int c = 0; c < ow; ++c)
{
int offset = b * oc * ow + c * oc + a;
result[a * oh * ow + b * ow + c] = nums[offset] * scale;
}
}
}
}
void set_input_image(DPUTask *task, const Mat &img, const char *nodename)
{
Mat img_copy;
int height = dpuGetInputTensorHeight(task, nodename);
int width = dpuGetInputTensorWidth(task, nodename);
int size = dpuGetInputTensorSize(task, nodename);
int8_t *data = dpuGetInputTensorAddress(task, nodename);
// cout<<"set_input_image height:"<<height<<" width:"<<width<<" size"<<size<<endl;
image img_new = load_image_cv(img);
image img_yolo = letterbox_image(img_new, width, height);
vector<float> bb(size);
for (int b = 0; b < height; ++b)
for (int c = 0; c < width; ++c)
for (int a = 0; a < 3; ++a)
bb[b * width * 3 + c * 3 + a] = img_yolo.data[a * height * width + b * width + c];
float scale = dpuGetInputTensorScale(task, nodename);
// cout<<"scale: "<<scale<<endl;
for (int i = 0; i < size; ++i)
{
data[i] = int(bb.data()[i] * scale);
if (data[i] < 0)
data[i] = 127;
}
img_new.free();
img_yolo.free();
}
inline float sigmoid(float p)
{
return 1.0 / (1 + exp(-p * 1.0));
}
inline float overlap(float x1, float w1, float x2, float w2)
{
float left = max(x1 - w1 / 2.0, x2 - w2 / 2.0);
float right = min(x1 + w1 / 2.0, x2 + w2 / 2.0);
return right - left;
}
inline float cal_iou(vector<float> box, vector<float> truth)
{
float w = overlap(box[0], box[2], truth[0], truth[2]);
float h = overlap(box[1], box[3], truth[1], truth[3]);
if (w < 0 || h < 0)
return 0;
float inter_area = w * h;
float union_area = box[2] * box[3] + truth[2] * truth[3] - inter_area;
return inter_area * 1.0 / union_area;
}
vector<vector<float>> apply_nms(vector<vector<float>> &boxes, int classes, const float thres)
{
vector<pair<int, float>> order(boxes.size());
vector<vector<float>> result;
for (int k = 0; k < classes; k++)
{
for (size_t i = 0; i < boxes.size(); ++i)
{
order[i].first = i;
boxes[i][4] = k;
order[i].second = boxes[i][6 + k];
}
sort(order.begin(), order.end(),
[](const pair<int, float> &ls, const pair<int, float> &rs)
{ return ls.second > rs.second; });
vector<bool> exist_box(boxes.size(), true);
for (size_t _i = 0; _i < boxes.size(); ++_i)
{
size_t i = order[_i].first;
if (!exist_box[i])
continue;
if (boxes[i][6 + k] < CONF)
{
exist_box[i] = false;
continue;
}
// add a box as result
result.push_back(boxes[i]);
// cout << "i = " << i<<" _i : "<< _i << endl;
for (size_t _j = _i + 1; _j < boxes.size(); ++_j)
{
size_t j = order[_j].first;
if (!exist_box[j])
continue;
float ovr = cal_iou(boxes[j], boxes[i]);
if (ovr >= thres)
exist_box[j] = false;
}
}
}
return result;
}
static float get_pixel(image m, int x, int y, int c)
{
assert(x < m.w && y < m.h && c < m.c);
return m.data[c * m.h * m.w + y * m.w + x];
}
static void set_pixel(image m, int x, int y, int c, float val)
{
if (x < 0 || y < 0 || c < 0 || x >= m.w || y >= m.h || c >= m.c)
return;
assert(x < m.w && y < m.h && c < m.c);
m.data[c * m.h * m.w + y * m.w + x] = val;
}
static void add_pixel(image m, int x, int y, int c, float val)
{
assert(x < m.w && y < m.h && c < m.c);
m.data[c * m.h * m.w + y * m.w + x] += val;
}
image resize_image(image im, int w, int h)
{
image resized(w, h, im.c, 0);
image part(w, im.h, im.c, 0);
int r, c, k;
float w_scale = (float)(im.w - 1) / (w - 1);
float h_scale = (float)(im.h - 1) / (h - 1);
for (k = 0; k < im.c; ++k)
{
for (r = 0; r < im.h; ++r)
{
for (c = 0; c < w; ++c)
{
float val = 0;
if (c == w - 1 || im.w == 1)
{
val = get_pixel(im, im.w - 1, r, k);
}
else
{
float sx = c * w_scale;
int ix = (int)sx;
float dx = sx - ix;
val = (1 - dx) * get_pixel(im, ix, r, k) + dx * get_pixel(im, ix + 1, r, k);
}
set_pixel(part, c, r, k, val);
}
}
}
for (k = 0; k < im.c; ++k)
{
for (r = 0; r < h; ++r)
{
float sy = r * h_scale;
int iy = (int)sy;
float dy = sy - iy;
for (c = 0; c < w; ++c)
{
float val = (1 - dy) * get_pixel(part, c, iy, k);
set_pixel(resized, c, r, k, val);
}
if (r == h - 1 || im.h == 1)
continue;
for (c = 0; c < w; ++c)
{
float val = dy * get_pixel(part, c, iy + 1, k);
add_pixel(resized, c, r, k, val);
}
}
}
part.free();
return resized;
}
image load_image_cv(const cv::Mat &img)
{
int h = img.rows;
int w = img.cols;
int c = img.channels();
image im(w, h, c, 0);
unsigned char *data = img.data;
for (int i = 0; i < h; ++i)
{
for (int k = 0; k < c; ++k)
{
for (int j = 0; j < w; ++j)
{
im.data[k * w * h + i * w + j] = data[i * w * c + j * c + k] / 255.;
}
}
}
// bgr to rgb
for (int i = 0; i < im.w * im.h; ++i)
{
float swap = im.data[i];
im.data[i] = im.data[i + im.w * im.h * 2];
im.data[i + im.w * im.h * 2] = swap;
}
return im;
}
image letterbox_image(image im, int w, int h)
{
int new_w = im.w;
int new_h = im.h;
if (((float)w / im.w) < ((float)h / im.h))
{
new_w = w;
new_h = (im.h * w) / im.w;
}
else
{
new_h = h;
new_w = (im.w * h) / im.h;
}
image resized = resize_image(im, new_w, new_h);
image boxed(w, h, im.c, .5);
int dx = (w - new_w) / 2;
int dy = (h - new_h) / 2;
for (int k = 0; k < resized.c; ++k)
{
for (int y = 0; y < new_h; ++y)
{
for (int x = 0; x < new_w; ++x)
{
float val = get_pixel(resized, x, y, k);
set_pixel(boxed, dx + x, dy + y, k, val);
}
}
}
resized.free();
return boxed;
}
//------------------------------------------------------------------
void correct_region_boxes(vector<vector<float>> &boxes, int n, int w, int h, int netw, int neth, int relative = 0)
{
int new_w = 0;
int new_h = 0;
if (((float)netw / w) < ((float)neth / h))
{
new_w = netw;
new_h = (h * netw) / w;
}
else
{
new_h = neth;
new_w = (w * neth) / h;
}
for (int i = 0; i < n; ++i)
{
boxes[i][0] = (boxes[i][0] - (netw - new_w) / 2. / netw) / ((float)new_w / (float)netw);
boxes[i][1] = (boxes[i][1] - (neth - new_h) / 2. / neth) / ((float)new_h / (float)neth);
boxes[i][2] *= (float)netw / new_w;
boxes[i][3] *= (float)neth / new_h;
}
}
std::string getDetectionJson(DPUTask *task, Mat &img, int sw, int sh)
{
vector<vector<float>> boxes;
for (unsigned int i = 0; i < outputs_node.size(); i++)
{
string output_node = outputs_node[i];
int channel = dpuGetOutputTensorChannel(task, output_node.c_str());
int width = dpuGetOutputTensorWidth(task, output_node.c_str());
int height = dpuGetOutputTensorHeight(task, output_node.c_str());
int sizeOut = dpuGetOutputTensorSize(task, output_node.c_str());
int8_t *dpuOut = dpuGetOutputTensorAddress(task, output_node.c_str());
float scale = dpuGetOutputTensorScale(task, output_node.c_str());
vector<float> result(sizeOut);
boxes.reserve(sizeOut);
get_output(dpuOut, sizeOut, scale, channel, height, width, result);
detect(boxes, result, channel, height, width, i, sh, sw);
}
correct_region_boxes(boxes, boxes.size(), img.cols, img.rows, sw, sh);
vector<vector<float>> res = apply_nms(boxes, classification, NMS_THRE);
float h = img.rows;
float w = img.cols;
std::string json = "[";
for (size_t i = 0; i < res.size(); ++i)
{
float xmin = (res[i][0] - res[i][2] / 2.0) * w;
float ymin = (res[i][1] - res[i][3] / 2.0) * h;
float xmax = (res[i][0] + res[i][2] / 2.0) * w;
float ymax = (res[i][1] + res[i][3] / 2.0) * h;
int cls = static_cast<int>(res[i][4]);
string class_name = class_names[cls];
float conf = res[i][5];
json += "{\"class\": \"" + class_name + "\",";
json += "\"confidence\": " + std::to_string(conf) + ",";
json += "\"bounding_box\": {";
json += "\"xmin\": " + std::to_string(xmin) + ",";
json += "\"ymin\": " + std::to_string(ymin) + ",";
json += "\"xmax\": " + std::to_string(xmax) + ",";
json += "\"ymax\": " + std::to_string(ymax);
json += "}}";
if(i != res.size() - 1) {
json += ",";
}
}
json += "]";
return json;
}
void detect(vector<vector<float>> &boxes, vector<float> result, int channel, int height, int width, int num, int sh, int sw)
{
{
int conf_box = 5 + classification;
float swap[height * width][anchor][conf_box];
for (int h = 0; h < height; ++h)
{
for (int w = 0; w < width; ++w)
{
for (int c = 0; c < channel; ++c)
{
int temp = c * height * width + h * width + w;
swap[h * width + w][c / conf_box][c % conf_box] = result[temp];
}
}
}
for (int h = 0; h < height; ++h)
{
for (int w = 0; w < width; ++w)
{
for (int c = 0; c < anchor; ++c)
{
float obj_score = sigmoid(swap[h * width + w][c][4]);
if (obj_score < CONF)
continue;
vector<float> box;
box.push_back((w + sigmoid(swap[h * width + w][c][0])) / width);
box.push_back((h + sigmoid(swap[h * width + w][c][1])) / height);
box.push_back(exp(swap[h * width + w][c][2]) * biases[2 * c + anchor * 2 * num] / float(sw));
box.push_back(exp(swap[h * width + w][c][3]) * biases[2 * c + anchor * 2 * num + 1] / float(sh));
box.push_back(-1); // class
box.push_back(obj_score); // this class's conf
for (int p = 0; p < classification; p++)
{
box.push_back(obj_score * sigmoid(swap[h * width + w][c][5 + p]));
}
boxes.push_back(box);
}
}
}
}
}
DPUKernel* kernel;
DPUTask* task;
void signal_handler(int signal) {
if (signal == SIGINT) {
std::cout << "\nSIGINT received. Shutting down..." << std::endl;
dpuDestroyTask(task);
dpuDestroyKernel(kernel);
dpuClose();
exit(0);
}
}
int main()
{
std::signal(SIGINT, signal_handler);
dpuOpen();
kernel = dpuLoadKernel(YOLOKERNEL);
task = dpuCreateTask(kernel, 0);
int sh = dpuGetInputTensorHeight(task, INPUTNODE);
int sw = dpuGetInputTensorWidth(task, INPUTNODE);
zmq::context_t context(1);
zmq::socket_t socket(context, ZMQ_REP);
socket.bind("tcp://*:5555");
std::cout << "Server started" << std::endl;
while (true) {
zmq::message_t request;
socket.recv(request, zmq::recv_flags::none);
std::cout << "Received image of size " << request.size() << " bytes" << std::endl;
std::vector<uchar> image_data(request.size());
std::memcpy(image_data.data(), request.data(), request.size());
try {
cv::Mat recv_image = cv::imdecode(image_data, cv::IMREAD_COLOR);
if (recv_image.empty()) {
std::cerr << "Failed to decode image" << std::endl;
socket.send(zmq::str_buffer("Failed to decode image"), zmq::send_flags::none);
continue;
}
std::cout << "Parsed image" << std::endl;
set_input_image(task, recv_image, INPUTNODE);
dpuRunTask(task);
std::cout << "DPU done" << std::endl;
std::string rep = getDetectionJson(task, recv_image, sw, sh);
std::cout << rep << std::endl;
zmq::message_t reply{rep};
socket.send(reply, zmq::send_flags::none);
}
catch (const cv::Exception& e) {
std::cerr << "Failed to process image: " << e.what() << std::endl;
socket.send(zmq::str_buffer("Failed to process image"), zmq::send_flags::none);
continue;
}
}
return 0;
}
To build the program, libzmq must be compiled first. This is quite simple, but took a decent amount of time on the slow Cortex-A9 cores.
Start by getting the source code:
wget https://github.com/zeromq/libzmq/releases/download/v4.3.5/zeromq-4.3.5.tar.gz tar -xf zeromq-* rm zeromq-4.3.5.tar.gz cd zeromq-*
Then run the configure script to prepare the sources:
./configure
If the source is not from a release, instead cloned from the libzmq git repo, autogen.sh must be run first.
Afterwards, compile and install:
make -j2 && make install
And finally, run ldconfig to make sure the shared object files are available to use.
Now our code can be built. I wrote the following simple makefile to do so:
YOLO := yolo_image
CXX := g++
CC := gcc
# linking libraries of OpenCV
LDFLAGS := $(shell pkg-config --libs opencv) -lpthread -lhineon -ln2cube -ldputils -lzmq
CUR_DIR := $(shell pwd)
MODEL := $(CUR_DIR)/dpu_yolo.elf
CFLAGS := -O2 -Wall -Wpointer-arith -std=c++11 -ffast-math -mcpu=cortex-a9 -mfloat-abi=hard -mfpu=neon -I.
# Single source file
SRC := main.cpp
OBJ := $(SRC:.cpp=.o)
.PHONY: all clean
all: $(YOLO)
# Rule to compile .cpp into .o
%.o: %.cpp zmq.hpp zmq_addon.hpp
$(CXX) -c $(CFLAGS) $< -o $@
# Rule to build the final executable
$(YOLO): $(OBJ)
$(CXX) $(CFLAGS) $^ $(MODEL) -o $@ $(LDFLAGS)
rm -f $(OBJ)
clean:
rm -f $(OBJ) $(YOLO)
After running the compiled program, let's test it. Here's a short python script that loads all .jpg images in the current directory, sends them over to the Arty for inference, then overlays the results on the images, and saves them.
import zmq
import json
import numpy as np
import cv2
import glob
def write_image(image_data, annotations, filename):
# Convert the binary image data into a NumPy array and decode it into an image
nparr = np.frombuffer(image_data, np.uint8)
image = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
if image is None:
print("Error: Unable to decode the image")
return
# Loop through the annotations and draw the bounding boxes and class labels
for annotation in annotations:
class_name = annotation["class"]
confidence = annotation["confidence"]
bbox = annotation["bounding_box"]
# Extract bounding box coordinates
xmin = int(bbox["xmin"])
ymin = int(bbox["ymin"])
xmax = int(bbox["xmax"])
ymax = int(bbox["ymax"])
# Draw the bounding box
cv2.rectangle(image, (xmin, ymin), (xmax, ymax), (0, 255, 0), 2)
# Create the label text with the class name and confidence
label = f"{class_name}: {confidence:.2f}"
# Put the label text above the bounding box
cv2.putText(image, label, (xmin, ymin - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 1)
cv2.imwrite(filename, image) # Save the image to the file
context = zmq.Context()
# Create a REQ (request) socket
socket = context.socket(zmq.REQ)
# Connect to the server
server_address = "tcp://10.0.9.39:5555"
print(f"Connecting to server at {server_address}...")
socket.connect(server_address)
# Loop through *.jpg files in the current directory
for filename in glob.glob("*.jpg"):
# Read the image file
with open(filename, "rb") as img_file:
image_data = img_file.read()
# Send the image data to the server
print(f"Sending image data to server ({filename})...")
socket.send(image_data)
# Receive the response from the server
response = socket.recv_string()
json_response = json.loads(response)
# Display the response
write_image(image_data, json_response, f"output_{filename}")
I got a few test images, then ran the script. The following images were produced:
| {gallery}Objects Detected |
|---|
|
Test Image 1: A partially obscured stop sign was missed above the traffic light |
|
Test Image 2: The license plate at the top of the garbage truck was missed, but I missed it too at first |
|
Test Image 3: Everything detected |
|
Test Image 4: The large traffic light in the front missed, but the tiny one further back is recognized. This seems to be a common occurrence. |




Now that the DPU code works, time to set it up to automatically start on boot. To do this, I made a script in /etc/init.d/dpu with the following contents:
stop() {
echo "Stopping $NAME..."
if [ -f $PIDFILE ]; then
kill -2 $(cat $PIDFILE) && rm -f $PIDFILE
else
echo "$NAME is not running."
fi
}
restart() {
stop
start
}
status() {
if [ -f $PIDFILE ]; then
if kill -0 $(cat $PIDFILE) 2>/dev/null; then
echo "$NAME is running with PID $(cat $PIDFILE)."
else
echo "$NAME is not running."
fi
else
echo "$NAME is not running."
fi
}
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
restart
;;
status)
status
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
exit 1
;;
esac
Then made it executable, and set it to start on boot:
chmod +x /etc/init.d/dpu
update-rc.d dpu defaults
(for some reason, I cannot put this in code blocks, I get a 403 error)
One more thing, also set a static IP on the Ethernet interface, in case DHCP is not available - like when directly connected to the Raspberry Pi. In /etc/network/interfaces, I changed the eth0 section to this:
auto eth0
iface eth0 inet dhcp
fallback inet static
iface eth0 inet static
address 192.168.5.2
netmask 255.255.255.0
Now, the Arty is working without any user interaction required. Give it power, send a JPG to the ZMQ socket, and it responds with detections.
JPGs From The Camera
Sticking with the microservice architecture I started this project with, next I modified my camera capture script to not just sync to the remote server, but also encode a lower resolution, MJPEG stream, using the Raspberry Pi 4's hardware accelerated JPEG encoder.
from picamera2 import Picamera2
from picamera2.encoders import H264Encoder, Quality, MJPEGEncoder
from picamera2.outputs import FileOutput
from libcamera import Transform, controls
import time
from syncbuf_source import SyncbufSource
import signal
import sys
import zmq
import io
import json
import influxdb_client
import collections
from influxdb_client.client.write_api import ASYNCHRONOUS, SYNCHRONOUS
from typing import Deque
import threading
DB_LOG_INTERVAL = 5
STATUS_PRINT_INTERVAL = 30
SYNC_SPEED_AVG_WINDOW_SECS = 10
API_TOKEN="x"
class MJPEGStreamOutput(io.BufferedIOBase):
def __init__(self, port: int = 11223):
self.context = zmq.Context()
# Internal socket pair - practically zero overhead
self.internal_socket = self.context.socket(zmq.PUSH)
self.internal_socket.set_hwm(1)
self.internal_socket.bind("inproc://frames")
# Start sender thread
threading.Thread(target=self._sender_thread, args=(port,), daemon=True).start()
def write(self, data):
try:
# PUSH to inproc is extremely fast, practically no blocking
self.internal_socket.send(data, copy=False, flags=zmq.NOBLOCK)
except zmq.ZMQError:
pass
return len(data)
def _sender_thread(self, port):
# This thread handles the actual network sending
receiver = self.context.socket(zmq.PULL)
receiver.connect("inproc://frames")
sender = self.context.socket(zmq.PUB)
sender.set_hwm(1)
sender.bind(f"tcp://*:{port}")
print(f"Started MJPEG publisher on port {port}")
while True:
try:
frame = receiver.recv()
sender.send(frame, copy=False)
except zmq.ZMQError:
continue
def signal_handler(sig, frame):
print("Stopping camera")
picam2.stop()
picam2.stop_encoder()
print("Exiting")
sys.exit(0)
signal.signal(signal.SIGINT, signal_handler)
# Keep track of the last time picamera gave us data
last_write = time.time()
def write_callback(write_size):
global last_write
if write_size > 0:
last_write = time.time()
# Measure sync speed
sync_stats = collections.deque()
def sync_callback(synced_bytes):
sync_stats.append((time.time(), synced_bytes))
tuning = Picamera2.load_tuning_file("imx477.json")
algo = Picamera2.find_tuning_algo(tuning, "rpi.agc")
for x in range(len(algo["channels"])):
algo["channels"][x]["metering_modes"]["custom"] = {"weights": [1,1,1,0,1,1,1,1,1,0,1,0,0,1,1]}
picam2 = Picamera2(tuning=tuning)
config = picam2.create_video_configuration(
raw = None,
main = {
"size": (1440, 1080)
},
lores={
"size": (640, 480),
"format": "YUV420"
},
buffer_count = 8,
transform=Transform(hflip=True, vflip=True)
)
picam2.align_configuration(config)
picam2.configure(config)
picam2.set_controls({"FrameDurationLimits": (62_500, 62_500)}) # 16 FPS default
picam2.set_controls({"AeMeteringMode": controls.AeMeteringModeEnum.Custom})
print(picam2.controls)
syncbuf = SyncbufSource("tcp://10.255.3.2:5555", write_callback=write_callback, sync_callback=sync_callback)
output = FileOutput(syncbuf)
encoder = H264Encoder(repeat=True, iperiod=8, enable_sps_framerate=True, framerate=16, bitrate=6_000_000)
mjpeg_output = FileOutput(MJPEGStreamOutput())
mjpeg_encoder = MJPEGEncoder(bitrate=10_000_000)
picam2.start_encoder(mjpeg_encoder, mjpeg_output, name="lores")
picam2.start_encoder(encoder, output)
picam2.start()
context = zmq.Context()
sub_socket = context.socket(zmq.SUB)
sub_socket.connect("tcp://localhost:5050")
sub_socket.setsockopt_string(zmq.SUBSCRIBE, "") # Subscribe to all messages
client = influxdb_client.InfluxDBClient(url="127.0.0.1:8086", token=API_TOKEN, org="org")
write_api = client.write_api(write_options=ASYNCHRONOUS)
hq_mode = True # Whether we are running in high-FPS high-bitrate mode, or low-FPS low-bitrate mode
time.sleep(1) # Don't immediately switch from high to low bitrate mode if the generator voltage is low on startup
db_log_timer = time.time()
status_print_timer = time.time()
while True:
try: # This is ugly, but this loop really shouldn't crash. The main priority is to keep the camera running in the thread managed by picamera2, and crashing the main loop will stop the picamera2 thread.
time.sleep(0.05)
# Check for messages from the MCU
if sub_socket.poll(0) & zmq.POLLIN != 0:
line = sub_socket.recv_string().strip()
try:
data = json.loads(line)
generatorVoltage = float(data.get("generatorVoltage"))
if generatorVoltage < 10 and hq_mode:
print("Switching to low bitrate mode")
hq_mode = False
picam2.stop()
picam2.stop_encoder(encoder)
picam2.stop_encoder(mjpeg_encoder)
encoder = H264Encoder(repeat=True, iperiod=8, enable_sps_framerate=True, framerate=4, bitrate=1_000_000)
picam2.set_controls({"FrameDurationLimits": (250_000, 250_000)}) # 4 FPS
picam2.start_encoder(encoder, output)
picam2.start_encoder(mjpeg_encoder, mjpeg_output, name="lores")
picam2.start()
if generatorVoltage >= 10 and not hq_mode:
print("Switching to high bitrate mode")
hq_mode = True
picam2.stop()
picam2.stop_encoder(encoder)
picam2.stop_encoder(mjpeg_encoder)
encoder = H264Encoder(repeat=True, iperiod=8, enable_sps_framerate=True, framerate=16, bitrate=6_000_000)
picam2.set_controls({"FrameDurationLimits": (62_500, 62_500)}) # 16 FPS
picam2.start_encoder(encoder, output)
picam2.start_encoder(mjpeg_encoder, mjpeg_output, name="lores")
picam2.start()
except json.JSONDecodeError:
print("Failed to decode JSON")
continue
if last_write + 10 < time.time():
print("Camera has stopped writing data, attempting restart")
picam2.stop()
picam2.stop_encoder(encoder)
picam2.stop_encoder(mjpeg_encoder)
time.sleep(1)
picam2.start_encoder(encoder, output)
picam2.start_encoder(mjpeg_encoder, mjpeg_output, name="lores")
picam2.start()
last_write = time.time()
if db_log_timer + DB_LOG_INTERVAL < time.time():
db_log_timer = time.time()
# Calculate average sync speed in the last 5 seconds
# Remove stats older than 5 seconds
threshold = time.time() - SYNC_SPEED_AVG_WINDOW_SECS
while sync_stats and sync_stats[0][0] < threshold:
sync_stats.popleft()
# Sum up transferred bytes
transferred_bytes = 0
stat_count = len(sync_stats)
for x in range(stat_count):
transferred_bytes += sync_stats[x][1]
# Calculate average sync speed
transferred_bytes /= SYNC_SPEED_AVG_WINDOW_SECS
# Log buffer stats
buf_stats = syncbuf.get_buffer_stats()
points = [
influxdb_client.Point("misc")
.field("bufferSize", buf_stats['buffer_size'])
.field("bufferCount", buf_stats['buffer_len'])
.field("syncSpeed", transferred_bytes)
]
write_api.write(bucket="mvpp", org="org", record=points)
if status_print_timer + STATUS_PRINT_INTERVAL < time.time():
status_print_timer = time.time()
buf_stats = syncbuf.get_buffer_stats()
print(f"Buffer length: {buf_stats['buffer_len']}, total size: {buf_stats['buffer_size']} bytes")
except Exception as e:
print(f"Main loop exception: {e}")
Now the camera script is also a ZMQ server(surprising that I picked ZMQ, I know) that sends JPG frames from the camera to every connected client.
ADAS Functionality
With JPG images available from the camera, the Arty-Z7 can be used to run object detection on the images, and the detections, along with sensor data (mainly from gpsd) can now be used to provide ADAS functionality.
The two main functions I implemented are speed limit warnings, and traffic light change notifications. The first one is quite self-explanatory, the second one is a bit more complex. The goal is to let the user select a traffic light, and whenever it changes state, play a warning sound.
Here's what the code has to do:
- Get an image from the camera
- Send it to the Arty, wait for the detections back
- Overlay the detections on the original image, like in the testing script shown before
- If any speed limit sign was detected, get the current speed from gpsd, and issue a warning to the user if speeding
- If any traffic light is detected, offer the user an option to somehow select it. Store the location of the selected traffic light(by location, I mean the coordinates of the bounding boxes), and if that detection changes to a different class, play a warning sound to the user
The most elegant way I could come up with for the user interactions and showing the camera image/detections was to make a webpage, which consists of a canvas filling the screen. Over a websocket (kind of a mix between a regular TCP socket and ZMQ), receive image data from the backend, and render it on the canvas. If the user clicks/touches anything on the canvas, send the coordinates of the interaction back to the backend.
To play sounds as well, I just added two <audio> elements in the HTML, that are played when certain JSON "commands" are received over the websocket.
<!DOCTYPE html>
<html>
<head>
<style>
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
html, body {
width: 100%;
height: 100%;
overflow: hidden;
}
body {
display: flex;
justify-content: center;
align-items: center;
background-color: black;
}
#streamCanvas {
position: absolute;
width: 100%;
height: 100%;
cursor: crosshair;
}
</style>
</head>
<body>
<audio id="audio_speeding" src="speeding.mp3"></audio>
<audio id="audio_changed" src="changed.mp3"></audio>
</audio>
<canvas id="streamCanvas"></canvas>
<script>
const canvas = document.getElementById('streamCanvas');
const ctx = canvas.getContext('2d');
const ws = new WebSocket('ws://' + window.location.hostname + ':8766');
const VIDEO_ASPECT_RATIO = 640 / 480;
// Send the size of the canvas to the backend, so it can fully utilize the available display resolution if required. Currently unused.
function sendDimensions(width, height) {
if (ws.readyState === WebSocket.OPEN) {
ws.send(JSON.stringify({
type: 'dimensions',
width: Math.round(width),
height: Math.round(height)
}));
}
}
// Function to resize canvas to fill screen
function resizeCanvas() {
canvas.width = window.innerWidth;
canvas.height = window.innerHeight;
sendDimensions(canvas.width, canvas.height);
}
// Calculate dimensions for centered, aspect-ratio preserved image
function getImageDimensions() {
const canvasAspectRatio = canvas.width / canvas.height;
let drawWidth, drawHeight, drawX, drawY;
if (canvasAspectRatio > VIDEO_ASPECT_RATIO) {
// Canvas is wider than video
drawHeight = canvas.height;
drawWidth = drawHeight * VIDEO_ASPECT_RATIO;
drawY = 0;
drawX = (canvas.width - drawWidth) / 2;
} else {
// Canvas is taller than video
drawWidth = canvas.width;
drawHeight = drawWidth / VIDEO_ASPECT_RATIO;
drawX = 0;
drawY = (canvas.height - drawHeight) / 2;
}
return { drawX, drawY, drawWidth, drawHeight };
}
// Initial resize
ws.onopen = () => {
resizeCanvas();
};
// Debounce function to prevent too frequent resize events
function debounce(func, wait) {
let timeout;
return function executedFunction(...args) {
const later = () => {
clearTimeout(timeout);
func(...args);
};
clearTimeout(timeout);
timeout = setTimeout(later, wait);
};
}
// Handle window resize with debounce
window.addEventListener('resize', debounce(() => {
resizeCanvas();
}, 250));
ws.onmessage = (event) => {
const message = JSON.parse(event.data);
// Data received over websocket is a new frame
if (message.type === 'frame') {
const img = new Image();
img.onload = () => {
// Clear canvas before drawing new frame
ctx.clearRect(0, 0, canvas.width, canvas.height);
// Draw black background
ctx.fillStyle = 'black';
ctx.fillRect(0, 0, canvas.width, canvas.height);
// Draw image maintaining aspect ratio
const { drawX, drawY, drawWidth, drawHeight } = getImageDimensions();
ctx.drawImage(img, drawX, drawY, drawWidth, drawHeight);
};
img.src = 'data:image/jpeg;base64,' + message.data;
}
// Data received is a command to play audio
else if (message.type === 'alert') {
if(message.data == 'changed') {
document.getElementById('audio_changed').play();
}
else if(message.data == 'speeding') {
document.getElementById('audio_speeding').play();
}
}
};
// Handle clicks/touches on the canvas
function handleInteraction(e) {
const rect = canvas.getBoundingClientRect();
const { drawX, drawY, drawWidth, drawHeight } = getImageDimensions();
// Get click position relative to canvas
const canvasX = e.clientX - rect.left;
const canvasY = e.clientY - rect.top;
// Convert canvas coordinates to image coordinates
const imageX = ((canvasX - drawX) / drawWidth) * 640;
const imageY = ((canvasY - drawY) / drawHeight) * 480;
// Only send click if it's within the image bounds
if (imageX >= 0 && imageX < 640 && imageY >= 0 && imageY < 480) {
ws.send(JSON.stringify({
type: 'click',
x: Math.round(imageX),
y: Math.round(imageY)
}));
}
}
canvas.addEventListener('click', handleInteraction);
canvas.addEventListener('touchstart', (e) => {
e.preventDefault();
handleInteraction(e.touches[0]);
});
</script>
</body>
</html>
To serve this page, I installed nginx on the Raspberry Pi, and copied this file into /var/www/html/index.html. nginx is overkill for this, there is no server side processing at all, as the page is a completely static site.
And now, the backend, handling everything mentioned in the list above, along with communicating with the frontend:
import asyncio
import cv2
import numpy as np
from datetime import datetime
from WebSocketStreamer import WebSocketStreamer
import zmq
import os
from typing import List, Dict
import json
import threading
from threading import Lock
import gps
import time
speedlimit_classes = {
"speedlimit20": 20,
"speedlimit30": 30,
"speedlimit40": 40,
"speedlimit50": 50,
"speedlimit60": 60,
"speedlimit70": 70,
"speedlimit80": 80,
"speedlimit100": 100,
"speedlimit120": 120
}
trigger_box = None
trigger_class = None
last_detections = []
def overlap_percentage(box1, box2):
box1_xmin, box1_xmax = int(box1["xmin"]), int(box1["xmax"])
box1_ymin, box1_ymax = int(box1["ymin"]), int(box1["ymax"])
box2_xmin, box2_xmax = int(box2["xmin"]), int(box2["xmax"])
box2_ymin, box2_ymax = int(box2["ymin"]), int(box2["ymax"])
x_overlap = max(0, min(box1_xmax, box2_xmax) - max(box1_xmin, box2_xmin))
y_overlap = max(0, min(box1_ymax, box2_ymax) - max(box1_ymin, box2_ymin))
box1_area = (box1_xmax - box1_xmin) * (box1_ymax - box1_ymin)
box2_area = (box2_xmax - box2_xmin) * (box2_ymax - box2_ymin)
overlap_area = x_overlap * y_overlap
total_area = box1_area + box2_area - overlap_area
return overlap_area / total_area
gps_speed = 0
def gps_threadf():
global gps_speed
session = gps.gps(mode=gps.WATCH_ENABLE)
while 0 == session.read():
try:
if not (gps.MODE_SET & session.valid):
continue
if gps.isfinite(session.fix.speed):
gps_speed = session.fix.speed * 3.6 * 1.1
except Exception as e:
print(f"Failed to get GPS data: {e}")
continue
time.sleep(0.1)
def draw_detections(jpeg_bytes: bytes, detections: List[Dict]) -> bytes:
# Decode JPEG bytes to numpy array
nparr = np.frombuffer(jpeg_bytes, np.uint8)
img = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
for detection in detections:
# Extract information
class_name = detection["class"]
confidence = detection["confidence"]
bbox = detection["bounding_box"]
# Get coordinates
xmin, xmax = int(bbox["xmin"]), int(bbox["xmax"])
ymin, ymax = int(bbox["ymin"]), int(bbox["ymax"])
color = (0, 255, 0) if (not trigger_box) or overlap_percentage(bbox, trigger_box) < 0.33 else (0, 0, 255)
# Draw rectangle
cv2.rectangle(img, (xmin, ymin), (xmax, ymax), color, 2)
# Prepare label text
label = f"{class_name} {confidence:.2f}"
# Get label size for background rectangle
(text_width, text_height), baseline = cv2.getTextSize(
label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 2
)
# Draw label background
cv2.rectangle(
img,
(xmin, ymin - text_height - baseline - 5),
(xmin + text_width, ymin),
color,
-1
)
# Draw label text
cv2.putText(
img,
label,
(xmin, ymin - baseline - 5),
cv2.FONT_HERSHEY_SIMPLEX,
0.5,
(0, 0, 0),
2
)
# draw speed in bottom left in white
cv2.putText(
img,
f"{gps_speed:.2f} km/h",
(10, img.shape[0] - 10),
cv2.FONT_HERSHEY_SIMPLEX,
0.5,
(255, 255, 255),
2
)
# Encode back to JPEG bytes
_, buffer = cv2.imencode('.jpg', img)
return buffer.tobytes()
def handle_coordinates(x: float, y: float):
global trigger_box
global trigger_class
# Reset trigger box if clicked on background
bboxes = [detection["bounding_box"] for detection in last_detections]
if trigger_box is not None:
if not any(detection["xmin"] <= x <= detection["xmax"] and detection["ymin"] <= y <= detection["ymax"] for detection in bboxes):
trigger_box = None
trigger_class = None
# set trigger box if clicked on a detection
for detection in last_detections:
xmin, xmax = detection["bounding_box"]["xmin"], detection["bounding_box"]["xmax"]
ymin, ymax = detection["bounding_box"]["ymin"], detection["bounding_box"]["ymax"]
if xmin <= x <= xmax and ymin <= y <= ymax:
trigger_box = detection["bounding_box"]
trigger_class = detection["class"]
break
class FrameReceiver:
def __init__(self, context, address):
self.context = context
self.address = address
self.latest_frame = None
self.lock = Lock()
self.running = False
def start(self):
self.running = True
self.thread = threading.Thread(target=self._receive_frames, daemon=True)
self.thread.start()
def stop(self):
self.running = False
self.thread.join()
def _receive_frames(self):
socket = self.context.socket(zmq.SUB)
socket.set_hwm(1)
socket.connect(self.address)
socket.subscribe(b"")
while self.running:
frame = socket.recv()
with self.lock:
self.latest_frame = frame
def get_latest_frame(self):
with self.lock:
return self.latest_frame
async def main():
global trigger_box
global trigger_class
global last_detections
streamer = WebSocketStreamer(on_coordinates=handle_coordinates)
stream_task = asyncio.create_task(streamer.start())
context = zmq.Context()
# Start the frame receiver thread
frame_receiver = FrameReceiver(context, "tcp://192.168.4.1:11223")
frame_receiver.start()
# Setup DPU socket
dpu_socket = context.socket(zmq.REQ)
dpu_socket.connect("tcp://192.168.5.2:5555")
# Start GPS thread
gps_thread = threading.Thread(target=gps_threadf, daemon=True)
gps_thread.start()
try:
while True:
# Get the latest frame
frame = frame_receiver.get_latest_frame()
if frame is None:
await asyncio.sleep(0.01) # Wait for a frame to be received
continue
# Send to DPU and get detections
dpu_socket.send(frame)
detections = dpu_socket.recv_json()
last_detections = json.loads(json.dumps(detections))
# If no detections are in the trigger box, reset trigger box
if trigger_box is not None:
if all(overlap_percentage(detection["bounding_box"], trigger_box) < 0.33 for detection in detections):
trigger_box = None
trigger_class = None
# If there are detections in the trigger box, but not the trigger class, send alert
if trigger_class is not None:
if all(detection["class"] != trigger_class for detection in detections if overlap_percentage(detection["bounding_box"], trigger_box) > 0.33):
await streamer.send_alert("changed")
# check if any detections in speedlimit classes
for detection in detections:
if detection["class"] in speedlimit_classes:
speedlimit = speedlimit_classes[detection["class"]]
print(detection["class"])
print(speedlimit)
print(gps_speed)
if gps_speed > speedlimit:
print("alerted")
await streamer.send_alert("speeding")
print(detections)
# Draw detections on frame
annotated_frame = draw_detections(frame, detections)
# Send annotated frame to websocket
await streamer.send_frame(annotated_frame)
await asyncio.sleep(1)
except KeyboardInterrupt:
print("\nStopping server...")
streamer.stop()
frame_receiver.stop()
await stream_task
if __name__ == "__main__":
asyncio.run(main())
The WebSocketStreamer class used in the code above:
import asyncio
import websockets
import json
import base64
from typing import Callable, Optional
class WebSocketStreamer:
def __init__(self,
host: str = "0.0.0.0",
port: int = 8766,
on_coordinates: Optional[Callable[[float, float], None]] = None,
on_dimensions: Optional[Callable[[float, float], None]] = None):
self.host = host
self.port = port
self.clients = set()
self.running = False
self.on_coordinates = on_coordinates or (lambda x, y: print(f"Received coordinates: x={x}, y={y}"))
self.on_dimensions = on_dimensions or (lambda width, height: print(f"Received dimensions: width={width}, height={height}"))
async def register(self, websocket):
self.clients.add(websocket)
try:
await self.handle_client(websocket)
finally:
self.clients.remove(websocket)
async def handle_client(self, websocket):
try:
async for message in websocket:
# Handle incoming click/touch coordinates
data = json.loads(message)
if data['type'] == 'dimensions':
self.on_dimensions(data['width'], data['height'])
elif data['type'] == 'click':
self.on_coordinates(data['x'], data['y'])
except websockets.exceptions.ConnectionClosed:
pass
def jpeg_to_base64(self, jpeg_bytes: bytes) -> str:
"""Convert JPEG bytes to base64 string"""
return base64.b64encode(jpeg_bytes).decode('utf-8')
async def send_frame(self, frame_bytes: bytes):
"""Send a JPEG frame to all connected clients"""
if not self.clients:
return
frame_data = self.jpeg_to_base64(frame_bytes)
message = json.dumps({
"type": "frame",
"data": frame_data
})
websockets.broadcast(self.clients, message)
async def send_alert(self, alert_type):
if not self.clients:
return
message = json.dumps({
"type": "alert",
"data": alert_type
})
websockets.broadcast(self.clients, message)
async def start(self):
"""Start the WebSocket server"""
self.running = True
async with websockets.serve(self.register, self.host, self.port):
print(f"Server started at ws://{self.host}:{self.port}")
# Keep the server running
while self.running:
await asyncio.sleep(0.1)
def stop(self):
"""Stop the WebSocket server"""
self.running = False
And with that, everything is ready. Before showing the end results, I want to mention a few things I've been playing around with.
Larger and faster DPU in the Zynq-7020
The largest officially supported DPU is the "B1152" size(that I am currently using). I tried to squeeze a larger one into the FPGA, but ultimately failed.
I disabled features not used during YOLO inference, namely DepthWiseConv and AveragePool. Set the DPU to use a shared clock for both M-AXI and S-AXI, enabled "Low DSP Usage" mode, and simplified the clocking by eliminating the 150Mhz output on the Clocking Wizard, and using the FCLK from the PS instead (which is 100MHz only, so it would've actually been slower, as the DPU's "2x" clock has to be reduced to 200MHz, but at this point, I was desperate)
I managed to get the LUT/DSP/BlockRAM usage to a value that would fit in the Zynq-7020, but Vivado still failed at the Implementation step, with this error:
[Place 30-487] The packing of instances into the device could not be obeyed. There are a total of 13300 slices in the device, of which 8760 slices are available, however, the unplaced instances require 9660 slices. Please analyze your design to determine if the number of LUTs, FFs, and/or control sets can be reduced.
Number of control sets and instances constrained to the design
Control sets: 1776
Luts: 32738 (combined) 54968 (total), available capacity: 53200
Flip flops: 78204, available capacity: 106400
NOTE: each slice can only accommodate 1 unique control set so FFs cannot be packed to fully fill every sliceUnfortunately it looks like that B1152 is really the largest DPU that can fit.
YOLOv7
YOLOv7 is both significantly faster and more accurate than YOLOv3, so it would've been great to get it working. After re-training a custom YOLOv7 based model multiple times, I do not have enough time left to fix the remaining issues until the deadline.
A Darknet implementation is available, so I started with modifying that to fit my dataset. The first issues appeared when trying to convert the Darknet weights to Keras. I realized that the "logistic" activation function is not supported by the DPU.
I changed the config to use linear activations instead. This means having to re-train the model again.
With the linear activations, I was able to convert the Darknet weights to a Tensorflow "frozen graph" model, quantize it with Decent, but a new problem popped up during compilation.
Apparently the DPU doesn't support stride=1 in the maxpool layers.
Changing this isn't as simple as the activation function, the shape of tensors in the model change if these values are edited, meaning other parts of the configuration have to be changed as well to make this work.
This shouldn't be impossible, but I am not knowledgeable enough about neural networks to be able to quickly fix this issue, so I abandoned this idea, and went back to using the YOLOv3 model I trained.
Finished Project - An Overview
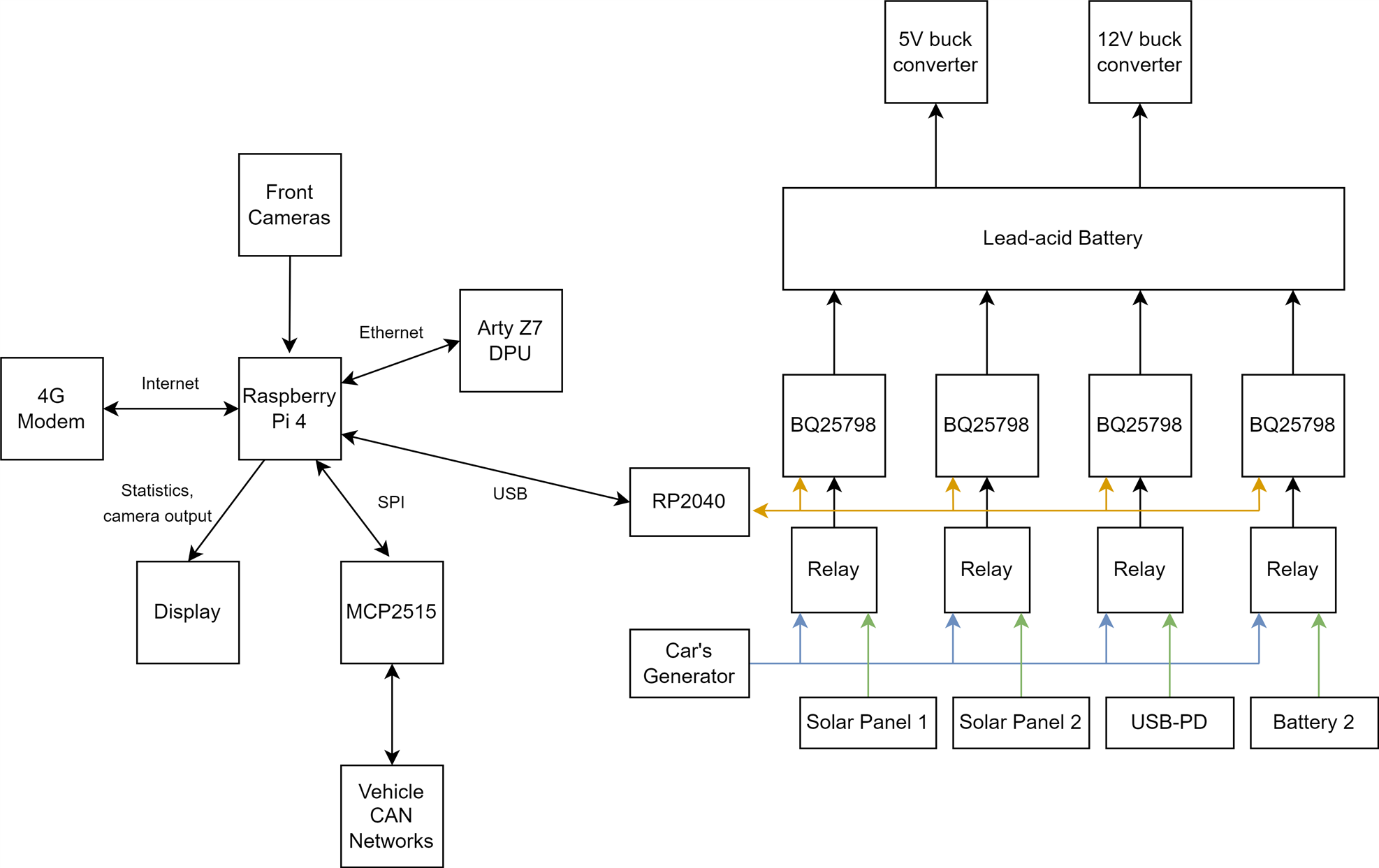
At its core, the system consists of a Raspberry Pi 4, a camera, a large battery, a 4G internet connection, multiple sensors, and a remote server with plenty of storage capacity.
The battery is charged by the vehicle's generator when driving, or solar panels when parked.
The main functions are the following:
- Record and stream live dashcam footage to the remote server
- Log vehicle related information in real-time
- Monitor the vehicle and its surroundings when parked
- Provide the driver with ADAS functionality, like speeding warnings and traffic light change notifications
Video Streaming
Video captured by the camera is streamed to the remote server, in real-time if network conditions allow. In case of inadequate internet speeds, captured video is locally buffered, and uploaded to the server when connection speeds improve. This process is completely transparent to the user, video files "just appear" in a folder on the server.
To implement this, the Raspberry Pi 4's hardware H264 encoder is used, along with a custom, fault-tolerant, (mostly) real-time streaming protocol. H264 encoded data chunks are put into a deque(doubly linked list) at one end, and the last element at the other end is selected for synchronization. ZeroMQ sockets are used for their reliability and ease of use, along with SHA256 checksumming and transmission order checking. Successfully synchronized elements are removed from the end of the deque.
To minimize network traffic and storage space utilization on the server, multiple optimizations are used. Encode bitrate and FPS are dynamically adjusted based on whether the car is driven or still. Synchronized video files can be re-encoded on the server with more efficient, but significantly more resource intensive codecs, such as AV1.
Vehicle Monitoring
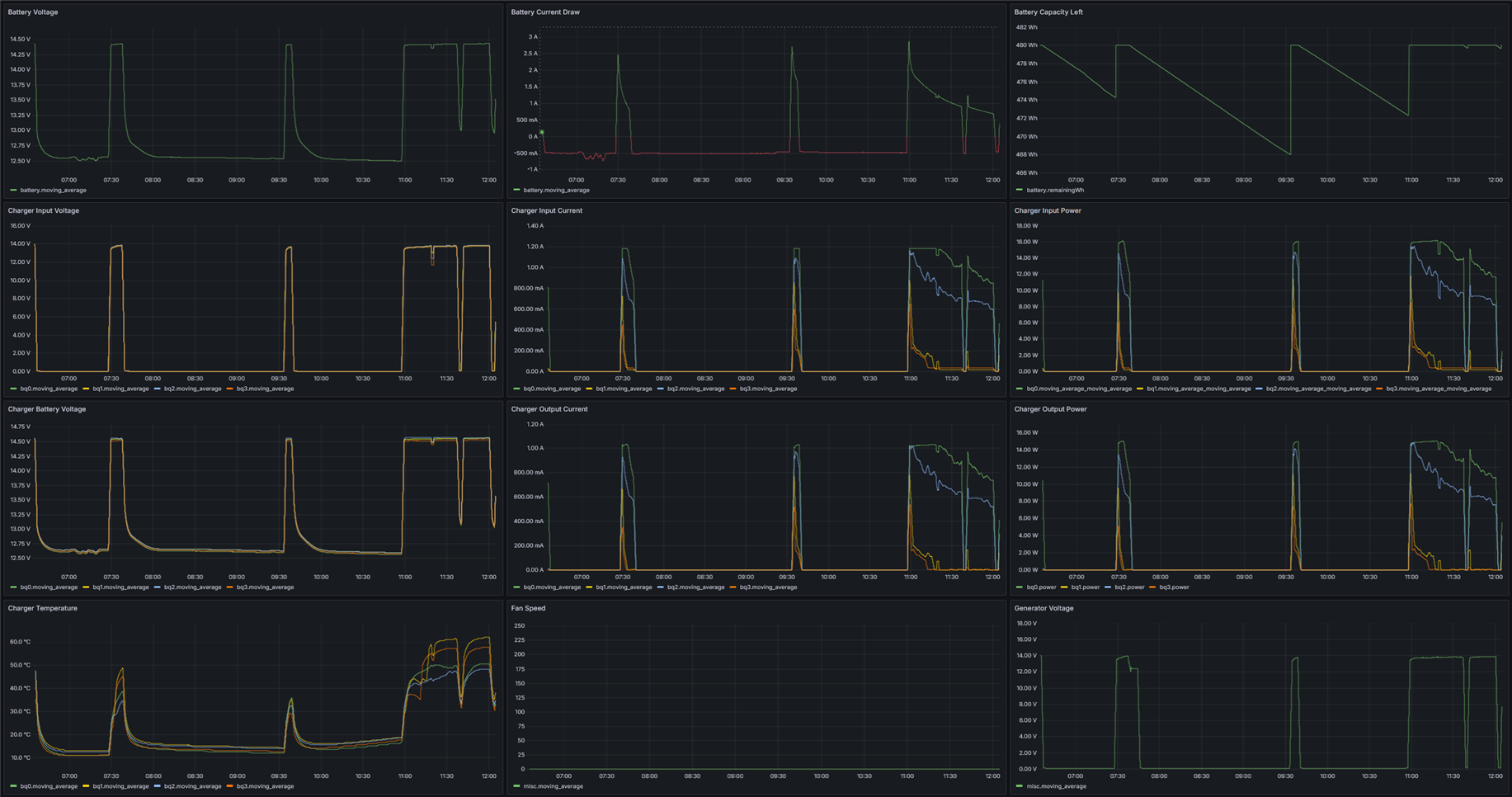
Along with a real-time view of the camera's image, many parameters are logged to a time-series database, which is also replicated to the remote server.
Some of the logged parameters available:
- Cranking battery voltage
- System battery voltage
- Vehicle speed
- Vehicle position
- Solar charging parameters
- Video synchronization latency and buffer health
The vehicle's CAN buses are also connected to the Raspberry Pi through dual MCP2515 CAN bus controllers. This provides a way to log even more parameters, such as RPM, engine temperature, fuel levels, mileage, and other statistics.
Logged parameters are available in real-time on Grafana dashboards.

ADAS
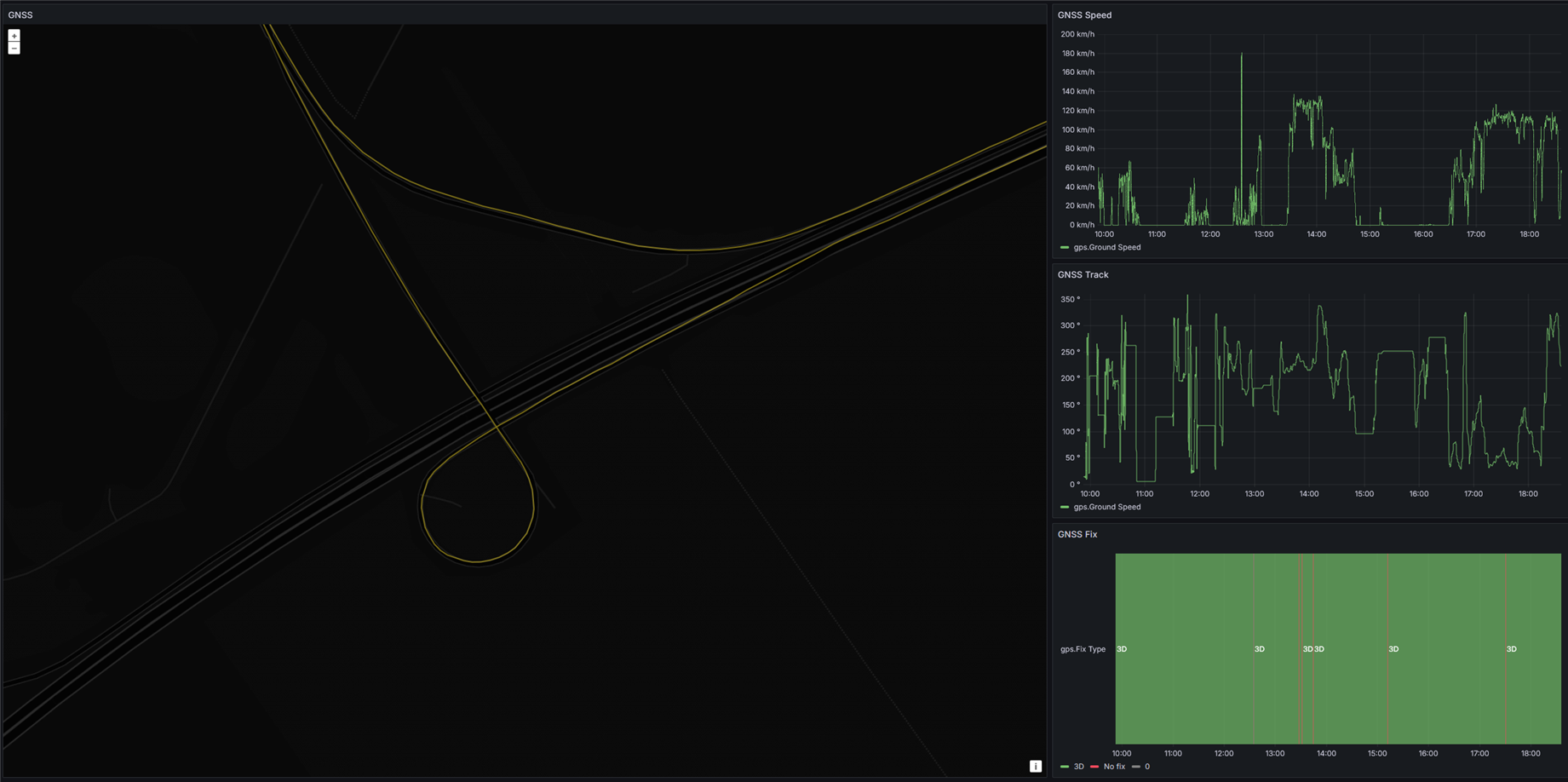
Utilizing the Deep Learning Processing Unit implemented in the Arty-Z7's FPGA, a custom trained YOLOv3-based object detection model is used to recognize traffic signs and traffic lights.
This data, along with speed information obtained from the GNSS unit, enables the system to warn the driver in case of speeding.
Another form of assistance available is traffic light change notifications, which alerts the user in case a traffic light transitions state. This can be especially useful, in case traffic lights are mounted in hard to see positions.
User Interface
All user interfaces are implemented as web applications, from parameter monitoring to ADAS control functions. This lets the driver use any internet-enabled device to interface with the system.
A CAN bus reverse engineering tool was also created, to help with identifying ArbIDs on the vehicle's CAN buses. Mapped ArbIDs can then be logged, along with the other sensor parameters, to provide more data about the vehicle.

Each byte of each message is graphed over time, with configurable graph scales, and user configured filters. ArbIDs can be assigned custom names(in the example above, the "Angle" line contains steering wheel angle information, so it was titled "Angle")
A simpler, cansniffer-like tool is also provided, with similar functionality:

All values are updated in real-time, utilizing a socketcan to websocket proxy running on the Raspberry Pi 4.
ADAS Demo
The web interface was recorded during a road trip running on an Android tablet, connected to the WiFi network created by the Raspberry Pi 4. This also "shares" internet access with connected devices, working similarly to a hotspot.
In the first video, the speeding warning system is showcased. The speed values obtained from the GNSS module are multiplied by 1.1, to help demonstrate the system without breaking any laws.
The Zynq-7020 is quite slow unfortunately, taking about 2 seconds per image to do object detection.
In this video, the traffic light change notification system is shown. The user can tap on a traffic light to select it, turning the bounding box red, and whenever the traffic light changes state, a notification sound will be played.
The Hardware
Main assembly:

4G modem:

CAN bus interface:

Main assembly mounted in glovebox:

Everything hooked up:

I completely forgot to print an enclosure for the Arty, I had it connected to my home network and used it through a VPN connection for testing, and it was too late to print something by the time I realized.
Future Plans and Ideas
Overall, I'm quite happy with how everything turned out. The single biggest issue is the Zynq-7020's processing speed, it was simply not designed for such demanding tasks. Coupled with the fact that newer models cannot run on the DPU, using the Raspberry Pi with a lightweight, performance optimized model, like YOLO-NAS, would've provided better results.
The wiring is also a bit of (=a huge) mess, but I didn't have a choice about it - the setup changed a lot during development, so creating custom PCBs multiple times wouldn't have been feasible during the challenge period.
I forgot to mention the supplied camera and light sensor module. The webcam ended up being mounted next to the Raspberry Pi HQ camera, but looking upwards. The HQ camera has a quite narrow field of view, so the webcam is meant to see traffic lights high above. I haven't finished implementing the software for it yet, but that is just another ZeroMQ socket, serving JPEG frames. The ADAS script is connected to both the Pi HQ camera and the webcam ZMQ servers, and will be able to switch between the two cameras based on user input on the web interface.
I haven't found a use for the ambient light sensor, hopefully that's not a huge issue. Since I already have solar panels, I can detect light levels by measuring their output power, so installing the ambient light sensor "just because" didn't seem like a particularly useful idea. I am thinking about installing a more permanent HDMI touchscreen though, and the light sensor could be used for automatic brightness adjustment.
A lot of the features are actually super useful, the live video streaming to the remote server saves me a lot of time by not having to bother with poorly thought out dashcams, and the position logging lets me have something similar to Google's Timeline feature for my car, just way more accurate.
I will be keeping the majority of the systems installed, and I'm planning on upgrading a few things, and potentially making a few blogs about it later.
The batteries are not holding up too well, in the last 2 months, their usable capacity dropped by about 30%. LiFePo4 batteries would be a great replacement, as they are relatively cheap, have high energy density, and they don't burn down my car.
A custom PCB would make a lot of sense now, it would shrink and simplify everything by a lot, and the hardware configuration / requirements are mostly final.
I was looking at the AMD KV260 (Kria K26 SoM), which includes a significantly larger and faster FPGA, 4x Cortex-A53 cores, and also has hardware H265 encoding, making it perfect for this use case, but unfortunately it is significantly beyond my budget for a hobby project. If I somehow manage to get my hands on it, or something similarly well suited for this project, I'll definitely make a blog series about designing and installing a hardware upgrade, and getting a better object recognition model to run on it.
-

flyingbean
-
Cancel
-
Vote Up
0
Vote Down
-
-
Sign in to reply
-
More
-
Cancel
Comment-

flyingbean
-
Cancel
-
Vote Up
0
Vote Down
-
-
Sign in to reply
-
More
-
Cancel
Children