


![]()
Hi all ! Hope everyone is fine.
Today we're going to talk about Data Augmentation, apply it to audio and why it's important.
In a Machine Learning model training, data is everything. With enough data, the model can learn better and perform better. At least, that's theory . 
Sometimes, because of the nature of the data or the problem trying to be solved, we can't always get enough or good data. In that cases, it's necessary to artificially augment the data.
Images
In case of images, there are several ways we can do this - creating new images:
- cropping
- rotating
- scale
- modify colors
- add some noise
The label of the image (another post with this) stays the same - because the subject hasn't changed - it's still the same image - but slightly altered. From the model's stand point, it is new data.
Audio
Just like for images, for audio there's also some techniques for audio augmentation. In the case of audio, the augmentation can be done on the raw audio before producing the spectrogram or after the generation of the spectrogram. Augmenting the spectrogram generally produces better results.
Let's generate some data.
Here's the original file - a Cuckoo call - waveform and spectrogram


Noise
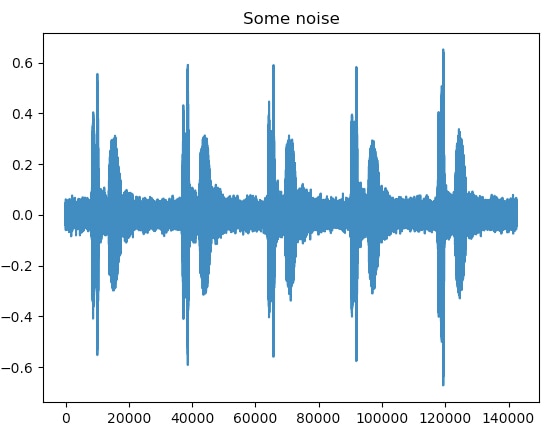
We can add some noise to the sample, randomly.
Here's the waveform, with a 0.02 noise factor:
Time shift
Here's the same waveform, time shifted by 1s to the right. We start with silence.

Pitch
Here's the same Cuckoo call with a change pitch, by factor of 3:

Speed
We can also change the speed of the audio. Here's the same cuckoo call with an increased speed by a factor of 10:

Conclusions
While this might help a bit, it's no substitution for real data. This will help the model get better, but it's always generated from real data. We can't just generate synthetic data from all the audio clips. It's necessary to understand the changes that these methods do to the original data and if they will help .
We can add all the transformations we can think off to the audio. I've only added one each time, but there's nothing that stops me to change the pitch and the speed to the same clip. The only thing is - does it make it any good ? Is it worth it ? Will it help the model ?
Because it's always better to hear than to see, the augmented audio files are attached to the post if you're interested to hear the differences.
Original file
Noise added
Pitch changed
Time shifted
Speed change
References
https://medium.com/@makcedward/data-augmentation-for-audio-76912b01fdf6
https://towardsdatascience.com/data-augmentation-for-speech-recognition-e7c607482e78
https://docs.scipy.org/doc/scipy/reference/generated/scipy.io.wavfile.write.html
-

DAB
-
Cancel
-
Vote Up
0
Vote Down
-
-
Sign in to reply
-
More
-
Cancel
Comment-

DAB
-
Cancel
-
Vote Up
0
Vote Down
-
-
Sign in to reply
-
More
-
Cancel
Children