


![]()
Hi all ! Hope everyone is fine.
What is Machine Learning (ML)
Since my project will deal with ML, fair is to briefly explain what is Machine Learning.
I'm not an expert on this and i'm still learning - this is a big big scientific field, with a lot of options to choose from and a lot to read and study.
Machine Learning is one of the most promising field currently on programming. People that deal with it are called Data Scientists.
ML is a subfield of Artificial Intelligence .
Kinds of ML
ML algorithms mainly fall into one of two categories - supervised learning and unsupervised learning
The difference is small, but significant
Supervised Learning
This type of learning is used when we already have data labeled that we will use to train our model to predict the future .
IE: You're a real estate agent. You have the a lot of data from previous sales that shows the values of houses, based on size, neighborhood, what similar houses have sold for, etc..
That data shows the relation of number of bedrooms, meters square, the neighborhood and the price it sold.
Using this data, we can train a network to predict the price of a house based on those parameters.
This is supervised learning. The computer will try to work out the relationship between all those fields.
Unsupervised learning
Using the same example from above, you have all these values, but this time, only the number of bedrooms, the size of the house and the neighborhood, but they don't have any labels on them, so you don't know which is which or what all means.
You don't know what all these values mean, but perhaps you can find a pattern in there.
You feed this to a ML algorithm that will try to find patterns in that data, without having previous knowledge of the data or knowing what it means.
Hey, can't we used ML to predict the lottery numbers ?
It turns out, you can't.
Unsurprisingly, studies have been done and a research has been made to prove that you can't. In one word - randomness.
Mathematicians and ML experts agree that AI can't be used to predict numbers randomly drawn. Sorry !
Here's an article in Medium, from Pavel Baidaus explaining this. It's fun to read.
Audio Classification
Sound Classification is one of the most widely used applications in Audio deep learning. Learning to classify sounds and predict the category of said sound.
What is sound ?
A sound signal is produced by variations in air pressure. We can measure the intensity of those variations and plot them over time.
Here's a very crude representation of a sound wave.
Digital Audio
To represent a sound digitally, we turn the sound waves into numbers. We do this by measuring the sound wave amplitude at fixed time intervals. Each measurement is a sample. The sample rate is the number of samples taken per second.
A common sample rate is 44.1KHz - 44.100 samples per second. Why this number ? (Remember, is a common sample rate, there are others)
According to Nyquist Sampling Theorem, the sampling frequency to produce the exact original waveform should be double the original frequency of the signal. The human hearing bandwidth is 20Hz-20KHz , hence the 44.1KHz more commonly used.
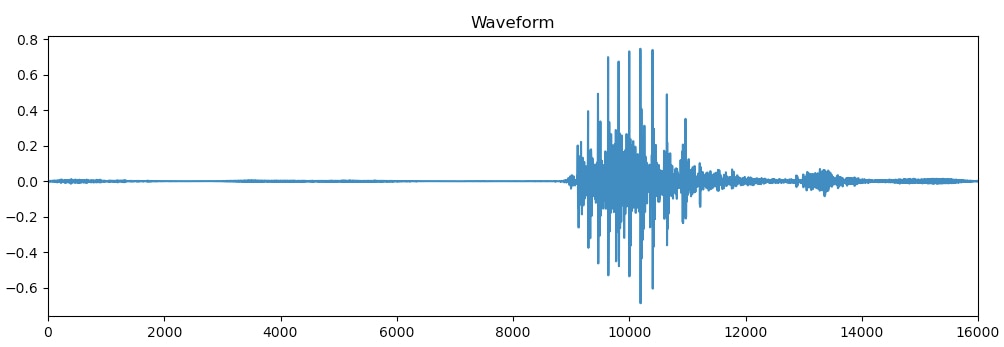
Waveform
A Waveform is a representation of the signal's amplitude at a specific time. Below we have an example of a waveform of a wav file with the word "right".
Spectrograms
Since a signal produces different sounds in time, its frequencies also vary with time.
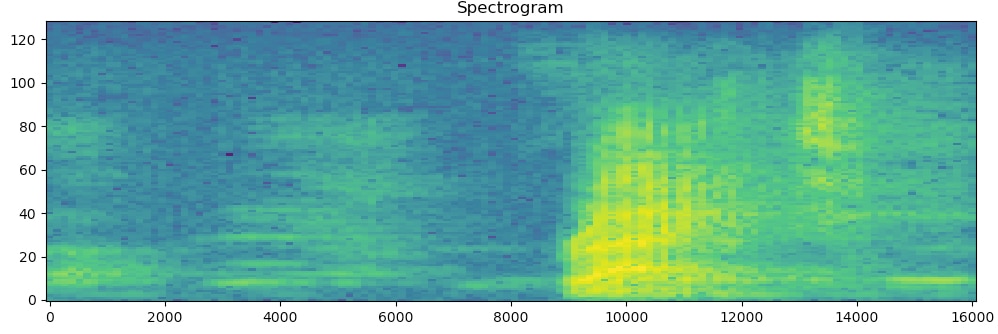
A Spectrogram is an image representation of the waveform of a signal. It shows its frequency intensity over time.
Here's the spectrogram of the word "right" - the same above
How is audio classified ?
Well, why bother with all this of getting the audio spectrogram ?
Because what we're going to feed our ML model is not the raw audio data, but a spectrogram of it .
Because deep learning CNNs - Convolutional neural nets - (this is for another post) are so great dealing with images, we feed them an image representation of our audio signal and let them learn with it.
The steps are (in a broad sense - there's a lot of fine details) :
- Audio raw data in a wave file (.wav)
- Convert the audio data into the spectrogram
- optional steps involve:
- augment the data (more on this on another post)
- crop or resize - normalize - the data
- feed the image data to the deep learning/shallow learning architecture for learning and feature extraction
- generate output predictions by passing it to a classifier of fully connected layers.

This project will use a classifier to try and classify the bird singing.
References
https://medium.com/@ageitgey/machine-learning-is-fun-80ea3ec3c471
https://micropyramid.com/blog/understanding-audio-quality-bit-rate-sample-rate/
-

Jan Cumps
-
Cancel
-
Vote Up
0
Vote Down
-
-
Sign in to reply
-
More
-
Cancel
-

robogary
in reply to Jan Cumps
-
Cancel
-
Vote Up
0
Vote Down
-
-
Sign in to reply
-
More
-
Cancel
Comment-

robogary
in reply to Jan Cumps
-
Cancel
-
Vote Up
0
Vote Down
-
-
Sign in to reply
-
More
-
Cancel
Children