


It's been 3 weeks since I verified that I could deploy an Arduino library of my audio classification model - Bee Healthy - Blog 8: Edge Impulse Model Deployment.
I verified it by using the Static Buffer program to reproduce the classification result for a test sample from my Edge Impulse project. I had also verified that I could do "Live Classification" of data from the Nicla Vision microphone via the edge-impulse-daemon interface. I had to take some time off for family issues, but now that I'm back I thought getting the inference working on the Nicla Vision would be a simple exercise. Of course, it turned out not to be so easy and this post is about the issues I encountered.
Inferencing on the Nicla Vision
Just a quick recap from the last post. I had used test data from the database used to train my model to run a "Live Classification" and copied the raw features into a static buffer program running on the Nicla Vision using the model library deployed from Edge Impulse. I got good correlation to the "Live Classification" result which gave me confidence that the model library had deployed correctly.
The next step was to do the same exercise with data that was captured using the PDM microphone on the Nicla Vision. Here is the result of the static buffer program using that data:
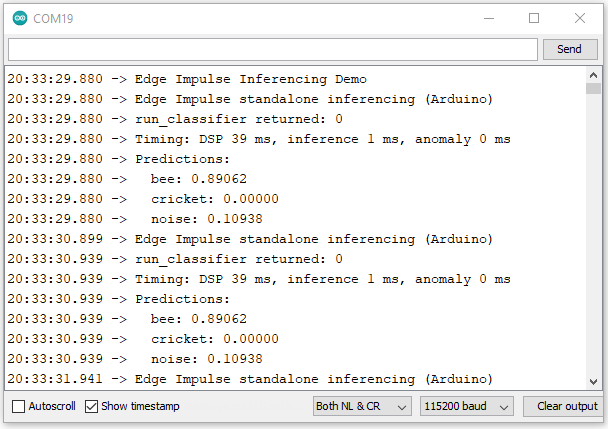
So, I've got confirmation that the capture of the microphone data is working correctly. The next step is to do live inferencing on the Nicla Vision. When the library is deployed, Edge Impulse includes example programs to run inferencing - in this case I tried the microphone example.
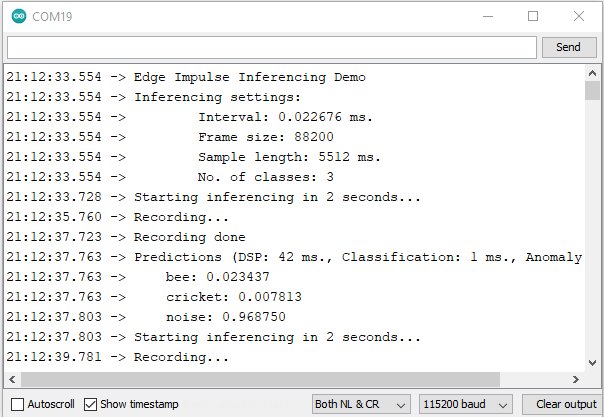
I guess I expected that there might be some accuracy degradation due to optimization done to run on the hardware resources, but I was surprised to find that the inferencing didn't seem to be working at all - I was getting a constant fixed result from a dynamic audio stream.
I suspected maybe some of the Arduino IDE compiler warnings that I had ignored might have been a problem, so I took a different approach. Instead of deploying a library and compiling a program - I decided to deploy a binary image and run it using the Edge Impulse CLI. That way I could determine if compiling was the issue.
So, I did that and flashed the binary model program. It flashed correctly, but when I went to run the impulse I discovered that the the binary required a later version of the impulse runner than I was using (something about the AT command version that I was using was not supported). I've encountered this problem before.... always version dependencies...
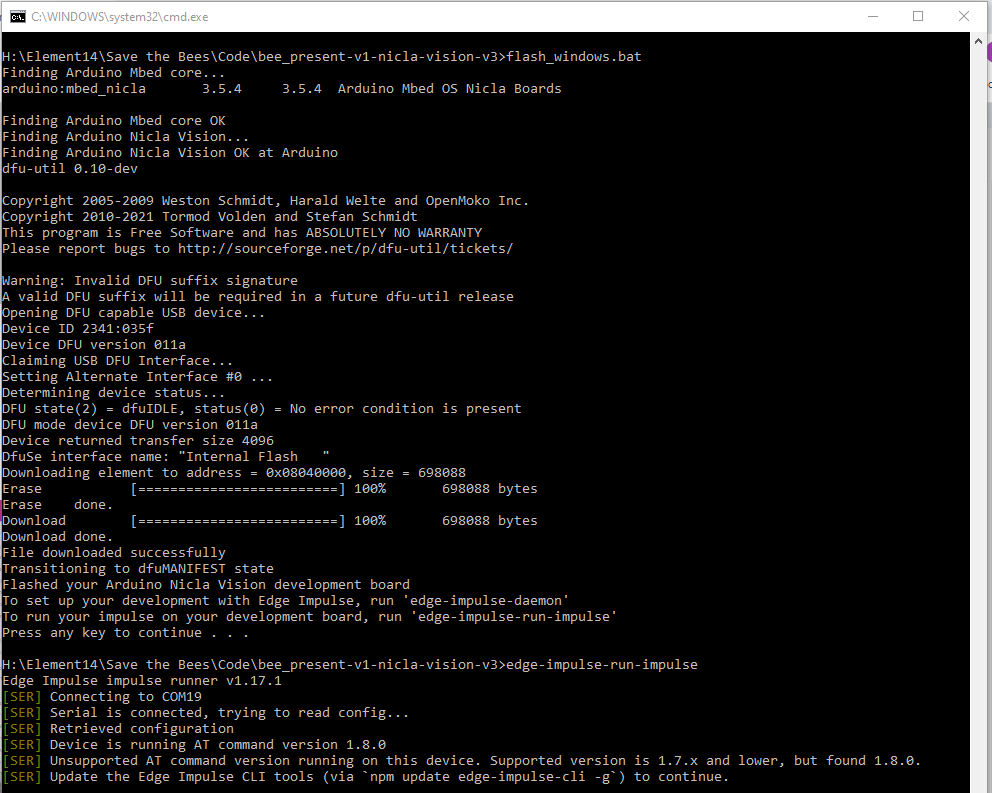
I updated the Edge Impulse CLI (which upgraded the impulse runner from v1.17.1 to v1.17.3 and apparently downgraded the AT command version from 1.8.0 to 1.7.x).
That allowed me to run the impulse, but I was getting a similar result as the compiled library - fixed non-changing values:
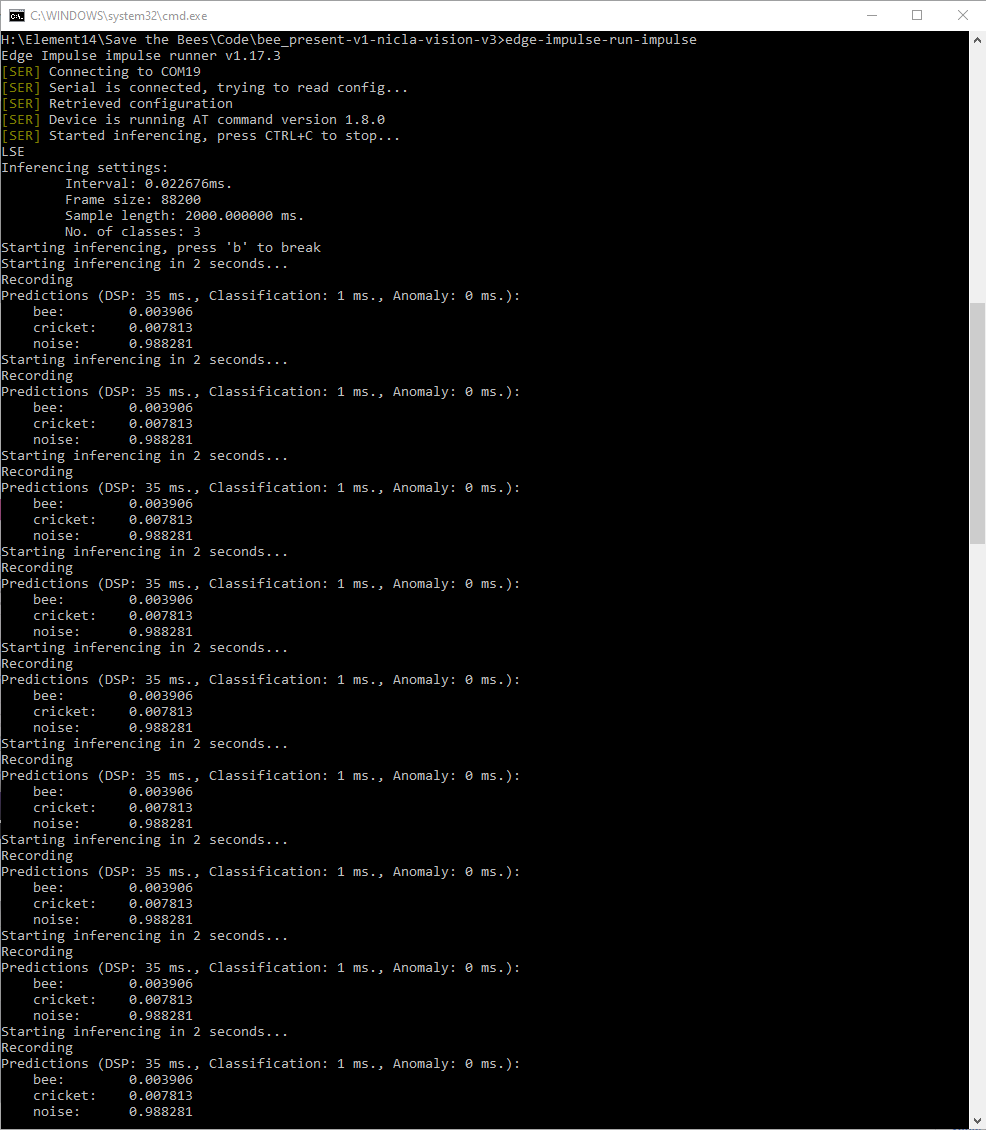
I happened to see that there is a debug flag option when running the impulse and that immediately trapped an error:
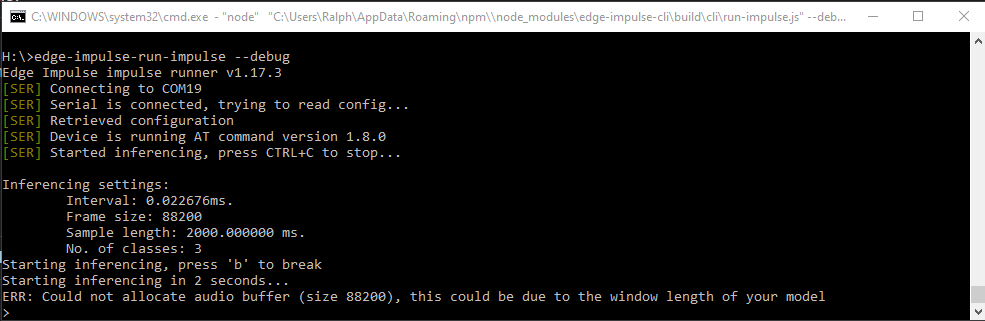
So, there was a problem allocating the audio buffer because of my sample size. I'm not sure why I had to use the debug flag to find that?
Also perplexing is that there is a what looks like a runtime check in the example Arduino program - which for some reason doesn't fail:

Anyway, at least I now had a problem that I could fix.
Fixing the buffer allocation problem
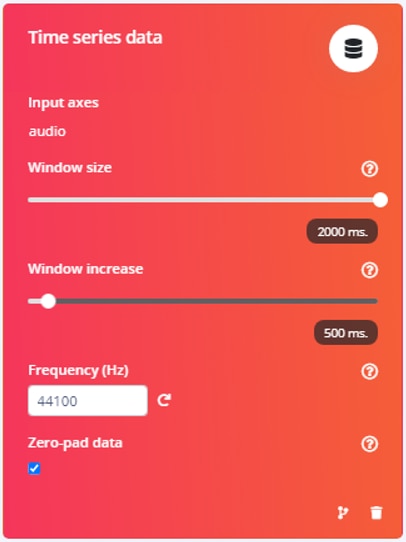
The cause of the large sample size (88,200) was easy to find and change. When I had designed the impulse, I had accepted the default sample frequency that Edge Impulse had selected based on the WAV dataset that I used for training. 44.1 KHz is the standard for CD quality audio, but probably not required for this model. I halved the sample freuency to 22.05 KHz and the new model still had reasonable accuracy and that fixed the buffer allocation error.
The bad news is that even though I was now getting data that was varying over time - I was not detecting any bees using the same audio stream that I used for "Live Classification".
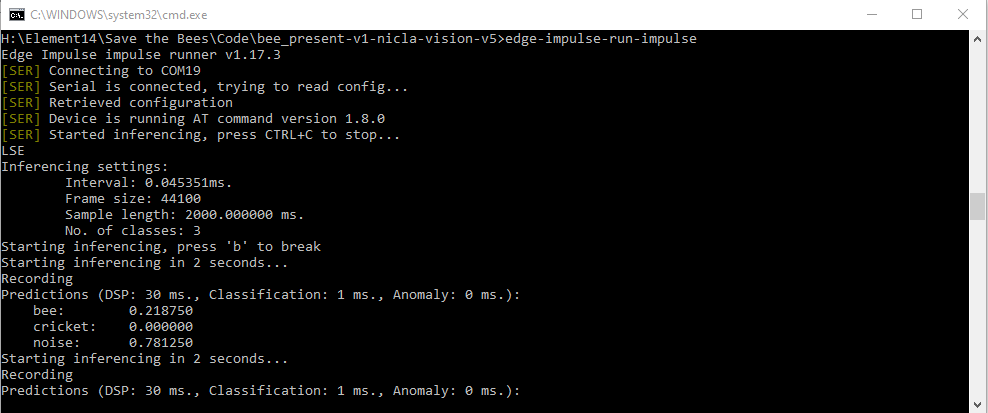
I sought some help on the Edge Impulse Forum and it was suggested that I needed to improve the dataset that I was using to train the model - by adding more input data using the Nicla Vision microphone and also by doing data augmentation and possibly mixing noise into the other data samples. This led me down the path of multiple iterations of model building and testing. I won't try to capture that here. One thing that I did discover is that training with time series audio data was requiring a lot of compute resources and many of my attempts failed because the parameter variations that I was trying would cause the compute time to exceed what is allowed for the "free" version of Edge Impulse Studio. Depending on the resources required, I could have gotten around this by using an appropriately priced Enterpise version.
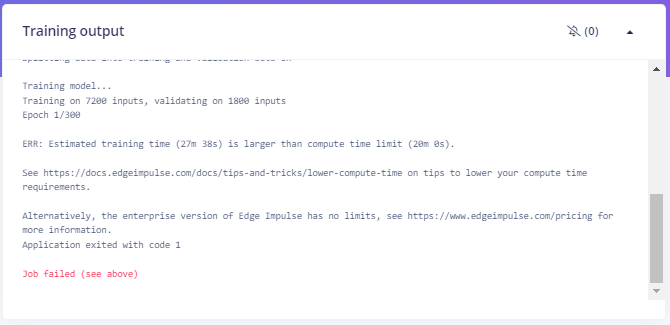
This prevented me from being able to do data augmentation (with the free version). I tried reducing the sample frequency to 16 KHz, but that only helped in some cases. I went through some painful iterations that would change the result, but still would not classify a bee from the audio stream. I was a bit confused about why "Live Classification" was working using the Nicla Vision microphone data, but the deployed model was not. I learned on the Forum that "Live Classification" was being done with the float32 model and I had deployed the quantized int8 model.
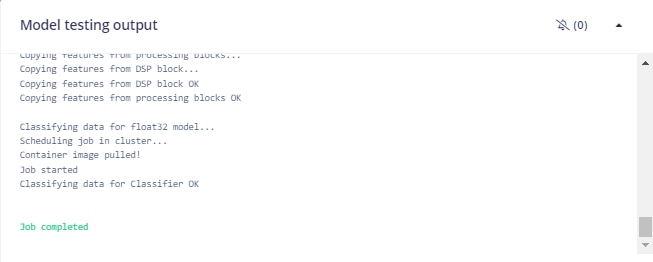
So, I tried a float32 version and that improved my results somewhat. I tried to deploy a version with the EON compiler turned off in case the optimizations were causing a problem, but that model would not fit in the available flash memory.
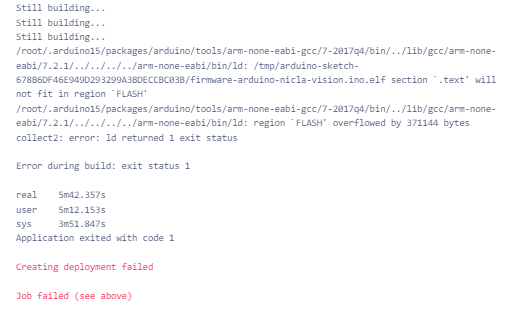
Since the float32 model (with EON compiler) was working better, I tried playing with the volume of my audio source and that was the missing piece. Not sure why the "Live Classification" was working, but the deployed model did not work at the same volume level. I am careful to use the same audio level and distance from the speaker to the microphone when testing.
But now I have a float32 model with 22.05 KHz sampling rate working at a specific volume.
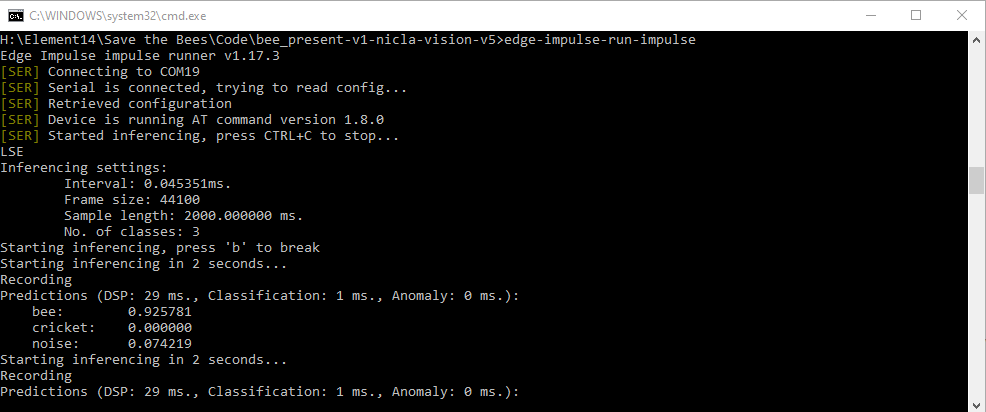
I think data augmentation would have helped if I had been able to run it or I could try to capture additional samples at different volume levels.
I believe that the programs are all using the default PDM gain settings, but that is the handle that I will try to tune if I get the opportunity to try this with a real hive. Here is the code segment from the microphone example that I am using (notice that it is commented out, so they are using the default setting of 24).

Anyway, now I have a program that I can work with. Next step is to get the I2C communication working between the Nicla Vision and MKR WAN 1310. After that I just need to get all the code integrated and test everything together.