



In my last blog I prepared my Raspberry Pi 4 for doing OCR using Python. In this blog post I will try to find which OCR technique fits best for my case. I will do some experiment with some images of multimeter, blood pressure meter and digital weight scale. From the experiment results I will try to find the best OCR technique for our use cases. Before going to the experiment I want to give some idea about OCR and some way to get a good result of the OCR.
What is OCR?
Optical Character Recognition (OCR) is a course of perceiving text inside pictures and changing it into an electronic structure. These pictures could be of manually written text, printed text like records, receipts, name cards, and so forth, or even a characteristic scene photo. OCR uses two techniques together to extract text from any image. First, it must do text detection to determine where the text resides in the image. In the second technique, OCR recognizes and extracts the text using text recognition techniques.
Nothing is perfect in this world and OCR is no exception. When it comes to increasing accuracy, it always boils down to two things, getting our data from the best source and choosing the right OCR engine for our use case.
The quality of image should be such that it is visible to the human eye. If that is the case then the OCR will produce good results. The better quality of image we have in our hand, better our OCR results will be. For accurate results, it requires the image to be vertically aligned, sized properly, and as clear as possible. Not every image meets those requirements! Some preprocessing of the image can improve the quality of input image so that the OCR engine gives you an accurate output. Although some OCR engines come with built in image preprocessing filters to improve the quality of the text image, they cannot tweak the images according to our use case. In order to achieve the best results, it is crucial to understand different components of preprocessing that improves OCR result.
These are a few preprocessing techniques, that can improve the quality of OCR output.

Preprocessing Techniques for better OCR
These are some preprocessing techniques that can improve our OCR result. We can make all these preprocessing very easily using OpenCV and Python.
- Inversion
- Rescaling
- Binarization
- Noise Removal / Denoising
- Dilation and Erosion
- Rotation / Deskewing
- Removing Borders
- Missing Borders
- Transparency / Alpha Channel
Inversion: Inversion works with Black and white image. Inversion refers to an image processing technique where light areas are mapped to dark, and dark areas are mapped to light. In other words, after image inversion black becomes white and white becomes black. We can invert the image using the bitwise_not function of OpenCV:
inverted_image = cv2.bitwise_not(image)
 |
 |
Binarization: In layman’s terms Binarization means converting a coloured image into an image which consists of only black and white pixels (Black pixel value=0 and White pixel value=255). As a basic rule, this can be done by fixing a threshold (normally threshold=127, as it is exactly half of the pixel range 0–255). If the pixel value is greater than the threshold, it is considered as a white pixel, else considered as a black pixel.
The threshold value may differ based on image contrast and brightness. The best practice is to find the minimum and maximum pixel value through the image and then consider the median value as a threshold.

Denosing: Noise is a random variation of brightness or color information in an image, that can make the text of the image more difficult to read. Most of the common noises are handled in Image Binarization and Contrast, and Sharpness Adjustment steps. But, based on the nature of the source image, different types of noises may be present which needs to be handled in a specific way. Noise decrease the readability of text from an image and should be remove for better OCR.

Image Scaling: Image rescaling is important for image analysis. Mostly OCR engine give an accurate output of the image which has 300 DPI. DPI describes the resolution of the image or in other words, it denotes printed dots per inch. For regular text (font size > 8), it is recommended to go with 300 DPI itself. For smaller text (font size < 8), it is recommended to have 400–600 DPI. Anything above 600 DPI will only increase the image size thereby increasing the processing time but shows no improvement with OCR accuracy.

Deskewing / Skew Correction: While scanning or taking a picture of any document, it is possible that the scanned or captured image might be slightly skewed sometimes. For the better performance of the OCR, it is good to determine the skewness in image and correct it.

Dilation and Erosion: Dilation adds pixels to the boundaries of objects in an image, while erosion removes pixels on object boundaries. The number of pixels added or removed from the objects in an image depends on the size and shape of the structuring element used to process the image.
Bold characters or Thin characters (especially those with Serifs) may impact the recognition of details and reduce recognition accuracy. Heavy ink bleeding from historical documents can be compensated for by using an Erosion technique. Erosion can be used to shrink characters back to their normal glyph structure.

Removing Borders: Big borders (especcially single letter/digit or one word on big background) can cause problems on OCR result. In that case cropping the input image to text area with a reasonable border (e.g. 10 pt) can improve the result. Scanned pages often have dark borders around them. These can be erroneously picked up as extra characters, especially if they vary in shape and gradation.

Missing Borders: If an image has just text without any border OCR can provide bad result. Adding a small white border e.g. 10 px can improve the result.
Transparency / Alpha channel: Some image formats (e.g. png) can have an alpha-channel for providing a transparency feature. Users should remove the alpha channel from the image before using the image in OCR engine.
For understanding how to perform the above preprocessing using OpenCV I strongly recommend this Python notebook: https://github.com/wjbmattingly/ocr_python_textbook/blob/main/02_02_working%20with%20opencv.ipynb
Experimenting with Multimeter Image
I already discussed about the preprocessing of an image before OCR. Now, lets do the experiment with the practical image. Before trying with the actual image taken by my Raspberry Pi I want to do the experiment on some sample image of multimeter and weight scale collected from the internet. Lets first start with the multimeter image. Below are the two sample image I have chosen for the experiment.
 |
 |
My target is to convert the voltage reading from the images to text using OCR. Consider left image as m1.jpg and right image as m2.jpg. Lets try to find the text from the above images without any preprocessing. I am using tesseract OCR engine from command line and following image shows the result I found:
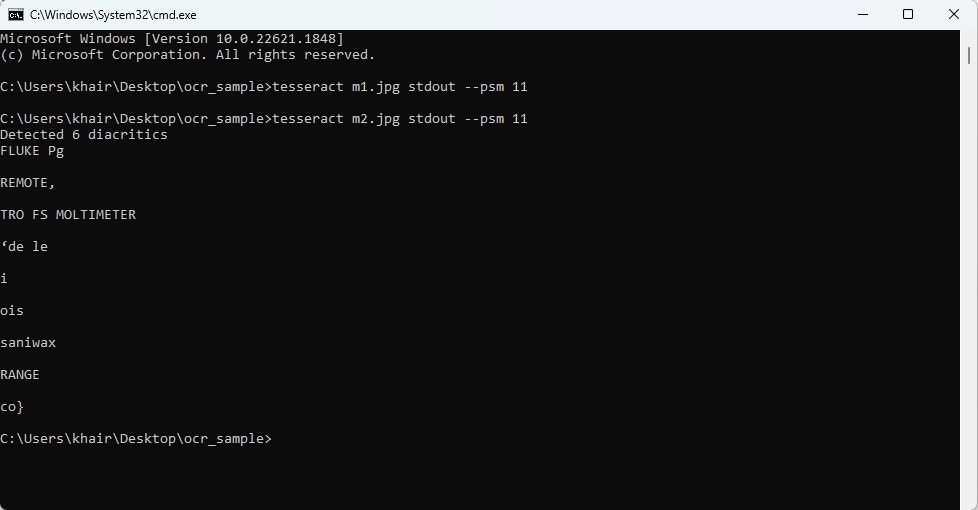
From the above image it is clear that I did not find any text from left image, but for right image tesseract was able to detect some text from meter body, not the actual reading on which we are interested.
Now I will observe the result after binarization as binarazation can give us more accurate result. I will use OpenCV and Python Jupyter Notebook for binarization. This is the sample code I used:
import cv2
import numpy as np
import matplotlib.pyplot as plt
import pytesseract
image1 = cv2.imread('m1.jpg')
gray_image1 = cv2.cvtColor(image1, cv2.COLOR_BGR2GRAY)
thresh, image1_bw = cv2.threshold(gray_image1, 175, 255, cv2.THRESH_BINARY)
cv2.imwrite("m1_bw.jpg", image1_bw)
img = cv2.imread('m1_bw.jpg')
plt.figure(figsize=[10,10])
plt.imshow(img);plt.title("Black White Image");plt.axis("off")
text = pytesseract.image_to_string(img, config='')
print (text)
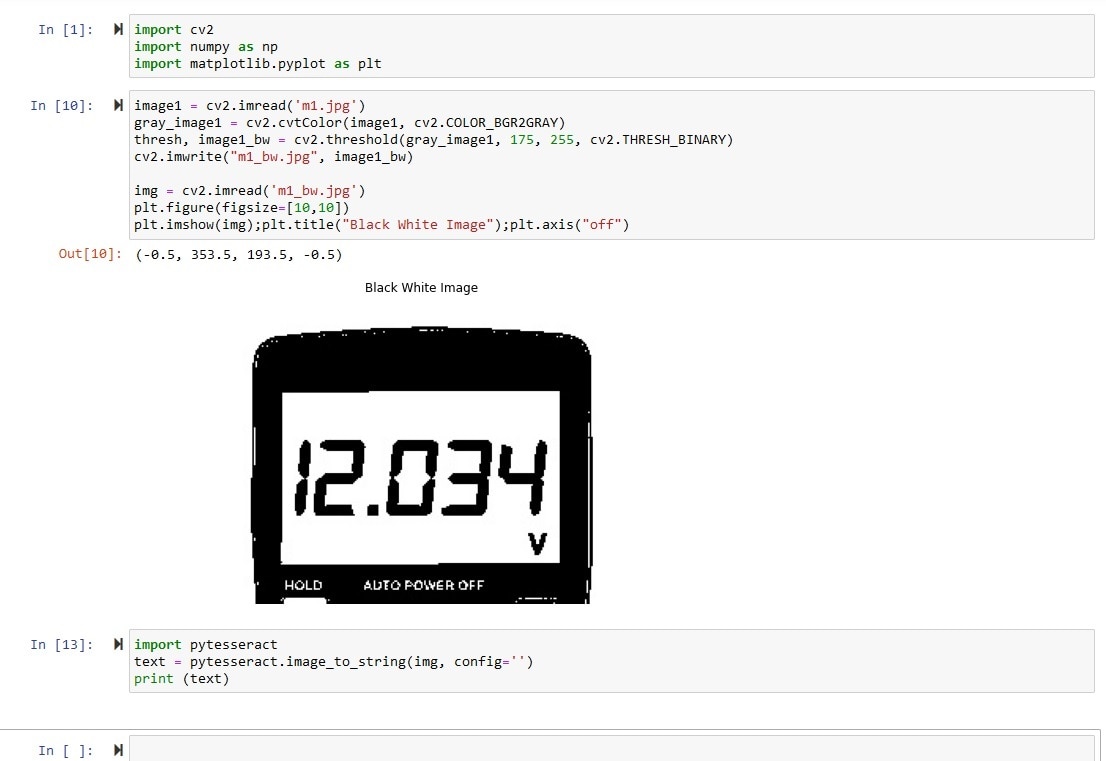
After making the image black and white I run the OCR engine again but there was no improvement on the result for left multimeter image.
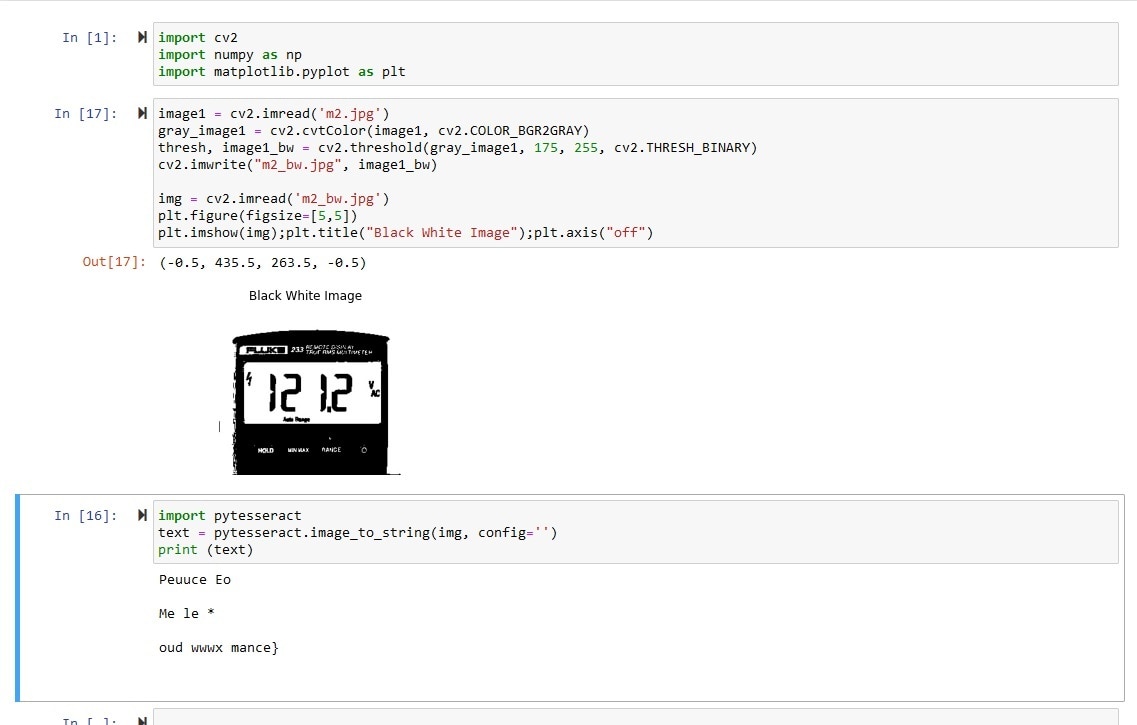
Same happens with the right image. This happens maybe for the big black border around the text. So, lets cut the border using the Photoshop. This is the image after removing the black border:
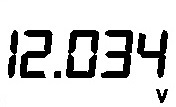
After removing the border I run the OCR engine again using same configuration.
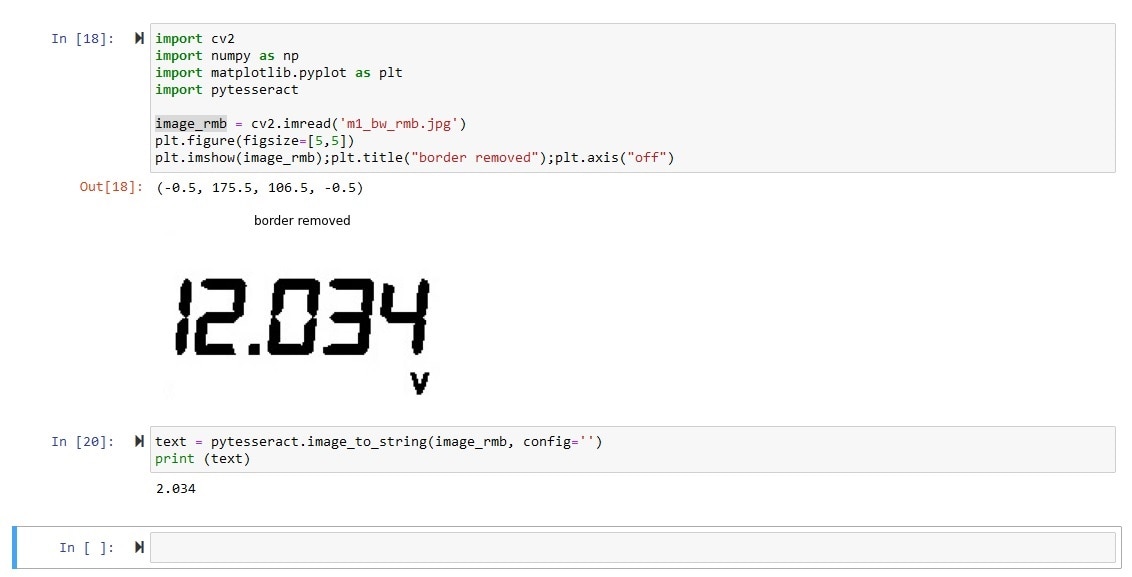
After removing the border I got an interesting result. The value is correct without the first 1. I am not sure about this behavior, maybe the font is too big. So, I added some white border and tested the image again with OCR.
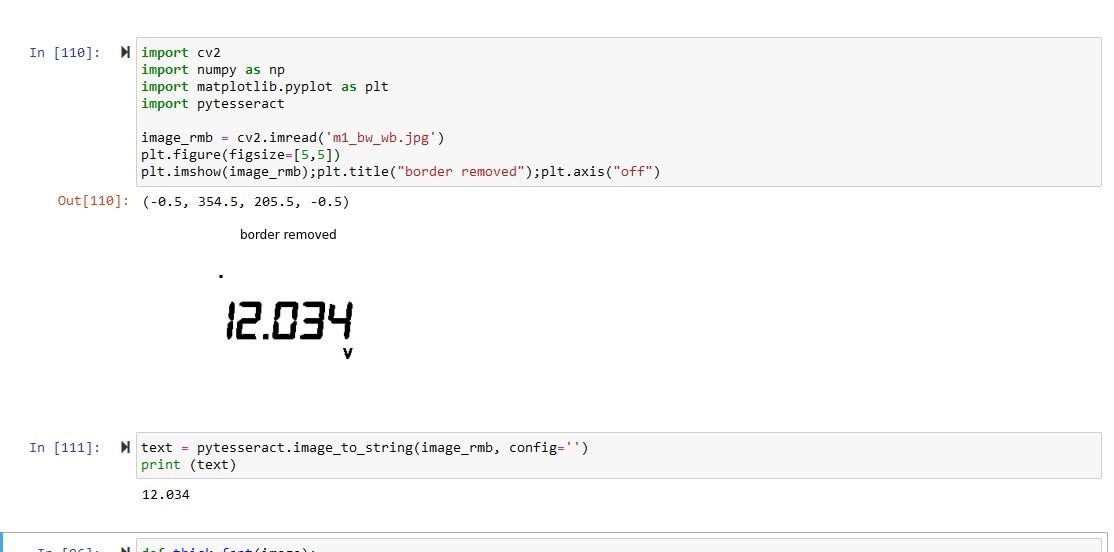
Finally, I got the expected output from the OCR.
So final result came out after following this sequential steps:
Binarization of the image -> removing the black border -> adding a white boarder -> Tesseract OCR
Lest do the same thing for few more image and observe the result. Following is from another multimeter. I did the same thing but did not get perfect answer. The value is same but with a random " at the beginning. It is solvable.
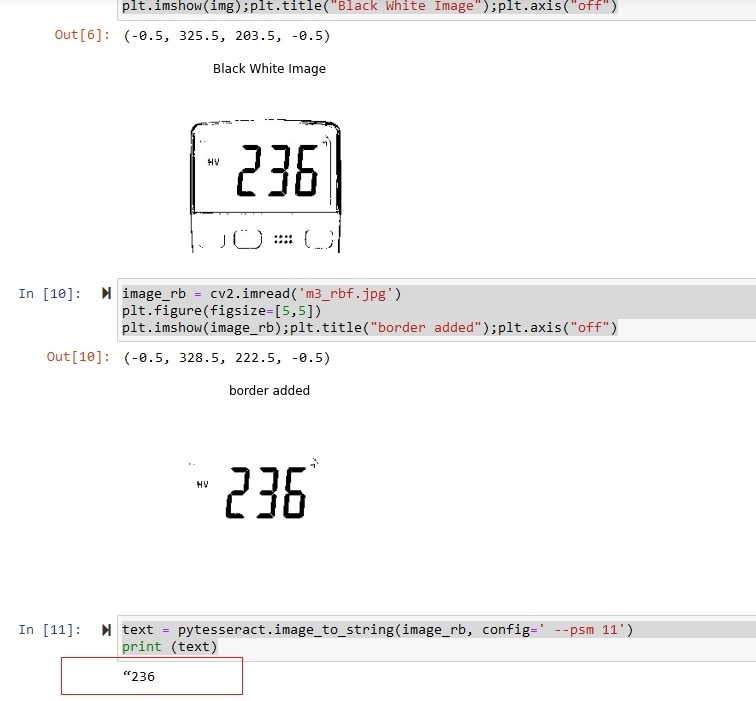
This is another image from another multimeter. This time value is correct but missing the decimal point.
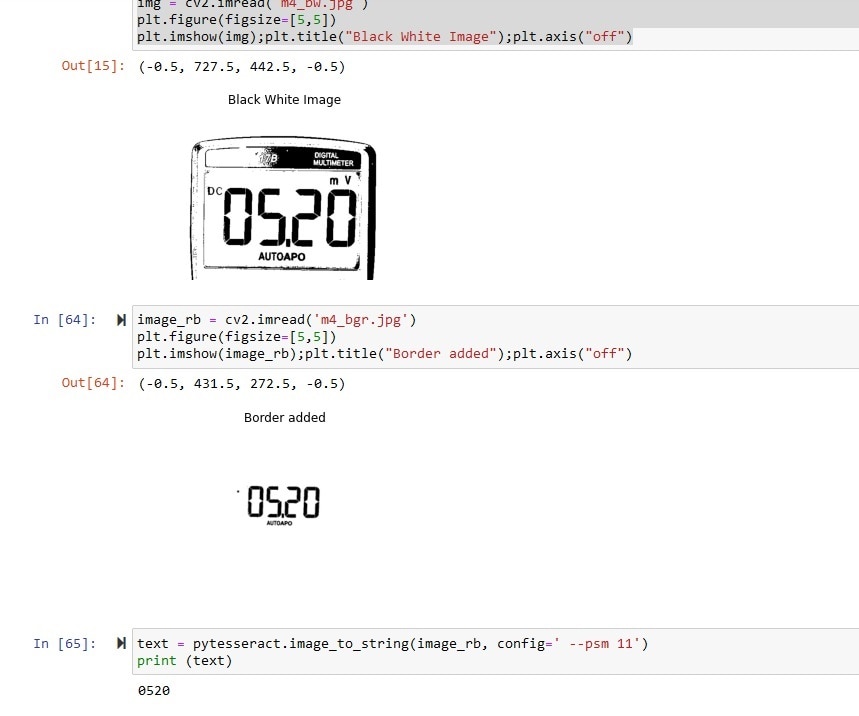
This image is from a digital weight scale. The value I got is not correct and not easily recoverable.
If I tabulate the experiment result that will be the the answer:
| Actual Image | Binarized Image | Modified Image | OCR Result | Comments |
 |
 |
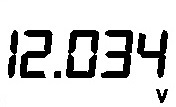 |
12.034 | Correct |
 |
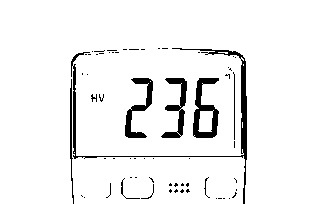 |
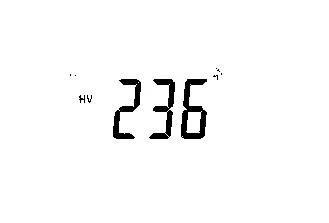 |
"236 | Vary Close |
 |
 |
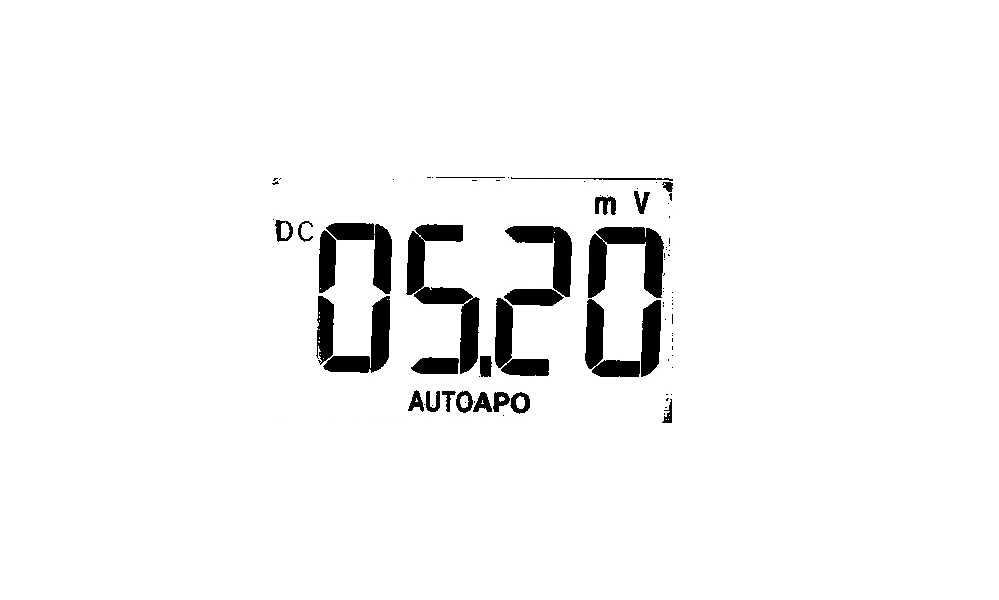 |
0520 | Close |
 |
 |
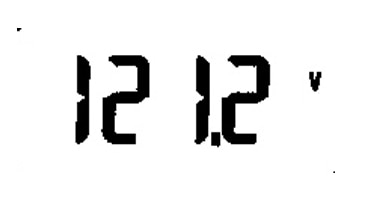 |
No result | |
 |
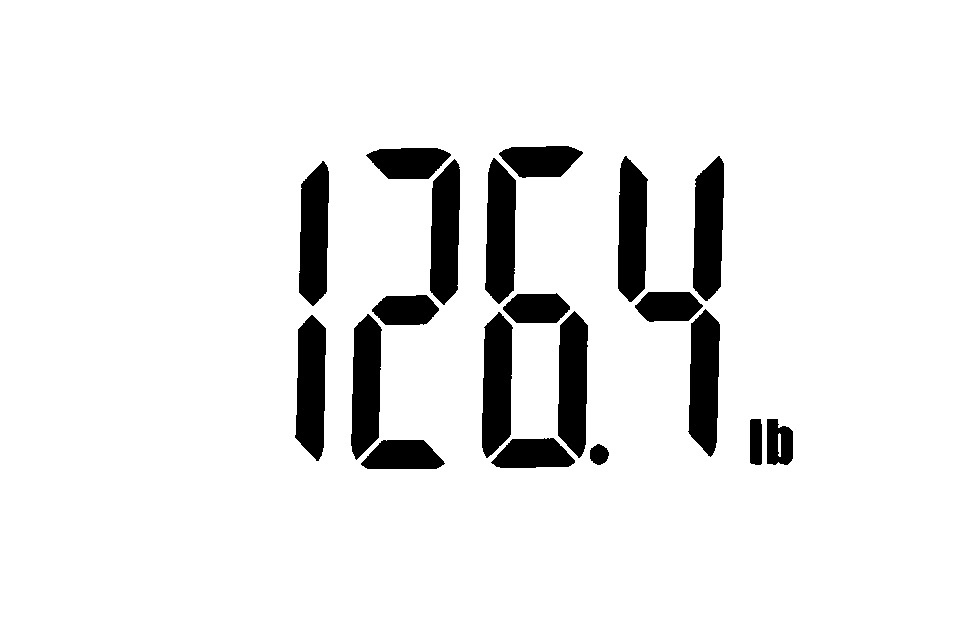 |
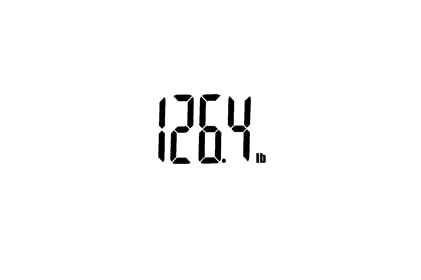 |
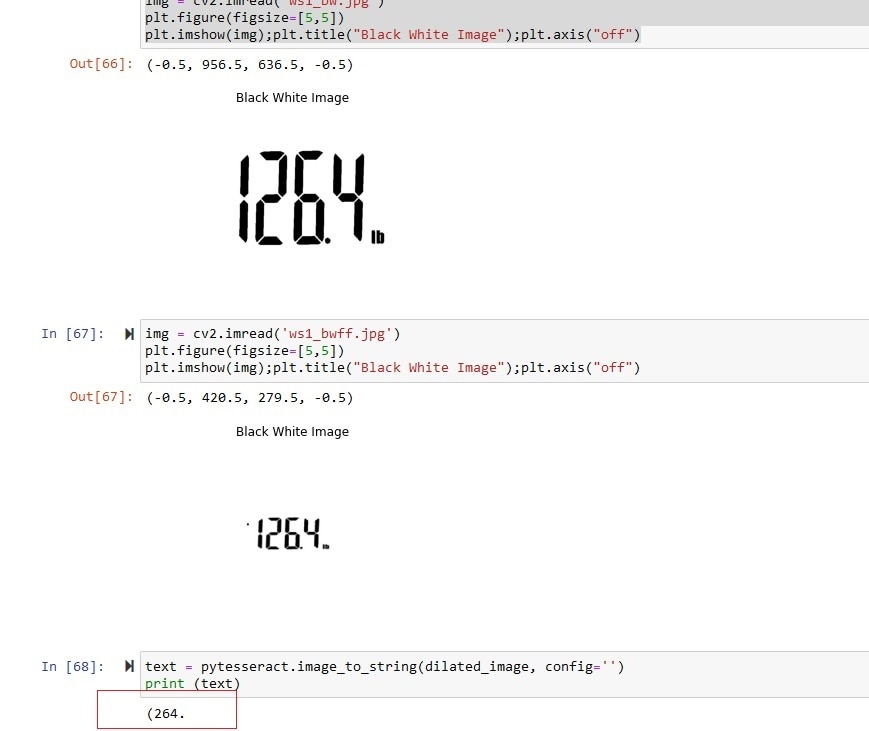
(264 | Close |
From the experiment I observed that tesseract OCR is not very accurate for seven segment display. It is good for the display that shows usual text and number. In my next blog I will try with other options for the seven segment display like ssocr.
References:
- https://github.com/wjbmattingly/ocr_python_textbook/blob/main/02_02_working%20with%20opencv.ipynb
- https://medium.com/cashify-engineering/improve-accuracy-of-ocr-using-image-preprocessing-8df29ec3a033
- https://medium.com/technovators/survey-on-image-preprocessing-techniques-to-improve-ocr-accuracy-616ddb931b76
- https://towardsdatascience.com/pre-processing-in-ocr-fc231c6035a7
- https://tesseract-ocr.github.io/tessdoc/ImproveQuality.html
-
soldering.on
-
Cancel
-
Vote Up
0
Vote Down
-
-
Sign in to reply
-
More
-
Cancel
Comment-
soldering.on
-
Cancel
-
Vote Up
0
Vote Down
-
-
Sign in to reply
-
More
-
Cancel
Children