


My interest in electronics started in my early teens (or even sooner). One of my first projects was a simple electronic organ kit, from the Radio Shack P-Box kit series.

This simple kit started a love of electronic music. Mind you, I have absolutely no music talent and I am basically tone-deaf, but I have always thought that a electronic music was an excellent playground for a budding engineer (or at that time geeky kid). In High School and College, whenever I needed to come up with a project, I always gravitated to a Synthesizer project. In High School that was a Popular Electronics kit project designed by Don Lancaster called the PSYCH-TONE (Popular Electronics - February 1971). I started this project, but never fully finished it as my budget and access to electronic components was pretty limited. In College that was a PAIA Electronics, 2700 series modular synthesizer with a full keyboard (A good friend of mine paid all the bills, but we worked the project together).
More recently I purchased a KORG volca modular synthesizer and later designed and built a MIDI file player to drive it. This MIDI file player was done as my entry in the project14 Op-Amp-a-Palooza, in which I was one the three first place winners.
When the project14 Music/Time theme was announced, there was little hesitation to take on yet another synthesizer project. This time my plan is to build a complete synthesizer from scratch. For this effort, I am building a hybrid, analog/digital, multi-voice synthesizer. The 'Music' aspect of the design is obvious and the 'Time' aspect part of the design is based on both the proper synthesis of the waveforms and the timing of the MIDI convertor (playing the notes at the right tempo).
Background
In the United States there are two basic schools of thought on the basis of music synthesis, known as West coast and East coast synthesizers. The coastal labels were defined based on the two primary forces between these two different methods. East coast camp was led by Moog, which was started in Trumansberg, New York, while the West coast camp was led by Buchla who was based in Berkeley, California.
East coast synthesis is characterized by the used of filters (VCF) to create its sound by selectively removing harmonic content from a harmonically rich oscillator output. In contrast the West coast synthesis is characterized by using wavefolder and modulators to create a harmonic rich sound, that is a bit more abrasive.
The plan that I have is to create something more in the middle of these two synthesis styles (which sort of makes sense as living in Texas is somewhere between these two coasts - sometime referred to as the 'third coast'). My plan is to design a Voice Module, that uses digital synthesis of a waveform, allowing multiple different waveshapes (sine, triangle ,ramp, square and even a folded sinewave). Along with the Oscillator, the Voice Module contains an ADSR (Attack, Decay, Sustain and Release) envelope generator and a tunable filtering system (Lowpass, Bandpass, Highpass or none). As a software only modification, the Voice Module can also be used as a Noise source by using a Linear Feedback Shift Register (LFSR), of 39 bit register length to develop a Pseudo Random bit sequence instead of the digital synthesis of a waveform.
The Voice Modules will plug into a back-plane connector, allowing up to 6 Voices to be simultaneously created. The Main board will have a processor to read the MIDI file, sending commands to the Voice Modules and then a mixer module to combine the Voices into a single output, which in then amplified to drive a speaker. An additional module will piggyback onto the back-plane to provide an echo/delay module to create another layer of texture to output.
Voice Module
The Voice Module is provides the basic functions of a VCO (Voltage Controlled Oscillator), ADSR/VCA (Attack/Decay/Sustain/Release and a Voltage Controlled Amplifier) and a VCF (Voltage Controller Filter). But, instead of the traditional designs, I am opting for a simpler, more compact and lower cost approach. The Oscillator activities are performed digitally inside of a ATtiny1614 microcontroller. This is a relatively new design form MircoChip, that includes an 8-bit DAC. Instead of a normal ADSR/VCA combination I will be using the ATtiny1614 to produce the ADSR function and controlling a variable attenuator circuit to provide the variable gain. And instead of a normal VCF I will be using a tunable State-variable active filter and a analog multiplexer to choose the filter type. All of this capability is being squeezed into a 1.5 sq Inch PCB.
Here is the current design of the Voice Module (the PCBs have been ordered and I am presently working on the ATtiny1614 software on a breadboard).

Voice Module - Oscillator
The Oscillator portion is based on a 100Khz interrupt function that accumulates a phase step on each interrupt and uses the upper 8 bits to lookup the waveform and sends to the data to the internal DAC. The DAC is referenced to an internal bandgap regulator and generates a 0 to 4.340V signal. Here are some images of the waveform output of the ATtiny1614:

Here is the sine wave output for 5th Octave E (659.25 Hz). The average measured frequency is 658.8Hz. In looking at this error it appears that the internal 20MHz clock is off by similar amount. I will need to either re-calibrate these processors, or update the design to use an external crystal oscillator to improve frequency generation accuracy.
Here is a folded sine wave output for the same 5th Octave E.

The waveform table information for the folded sine wave was calculated using a fundamental frequency with a 37.5% 3rd harmonic. I would like to experiment with a few other combinations of depth and different harmonics as I move forward. Currently my plan is to store waveform tables in the ATtiny1614 FLASH memory, but depending on available memory and the number of waveforms that I will want to use, I might need to move these tables into external memory (and load them into RAM as needed).
With the 100KHz interrupt rate on a 20Mhz processor, there are concerns for having enough time to complete all the various tasks. To get a better idea where I stand on available time, I did a simple measurement by raising an output pin upon entry into the timer interrupt and clearing it upon exiting (note, this is not completely accurate as there is some stack maintenance on both entry and exit that are not accounted for). Here is a quick look at the timing:

With the present code (not complete, but also not optimized), the phase accumulator interrupt processing is using about 33% of the ATtiny1614 processing bandwidth (based on 3.365uS of the 10.09uS interrupt interval). Currently the interrupt processing code is written in C, but I know that I can reduce the overhead by re-writing this code in assembly. Note the 10.09uS interrupt rate, this reflects the drift of the ATtiny1614 internal clock.
Voice Module - ADSR/VCA
Instead of a normal ADSR/VCA combination I will be using the ATtiny1614 to produce the ADSR function and controlling a variable attenuator circuit to provide the variable gain. Inside of the oscillator function, a flag will be raised at the start of each new waveform cycle which will be processed in the foreground loop. At each point the ADSR function will compute the amount of attenuation for the waveform envelope. The appropriate attenuation will be sent, via I²C to the attenuation control potentiometers.
The attenuator circuit is made up of two cascading attenuator stages, each providing 10:1 attenuation, or 100:1 overall.
ADSR/VCA modules are used to shape the envelope of the waveform in order to produce a desired sound. Let's look are the difference portions of the waveform elements:
- Attack - Attack is the initial rise in amplitude of the waveform. The faster the rise, the more percussive the sound, the slower the rise the more lush the sound. Attack time can be set to zero for an instantaneous sound.
- Decay - Once the waveform has reached its full volume, while the 'key' is still pressed, the volume will begin to decay. The decay time will determine how quickly this occurs.
- Sustain - This value determines to what level the volume is allowed to 'decay' to while the 'key' is still pressed.
- Release - This value determines the rate the volumes decreases once the 'key' is released. The slow release can allow the sound to taper off slowly much like a piano sound when the key is released and no other note is pressed.
In a typical synthesizer the ADSR module generates the control voltage (CV) that is applied to a VCA to actually control the volume. Here is a typical image of a ADSR/VCA envelope:

During the 'Attack' phase the volume rises at the Attack rate, triggered by the 'key' being pressed. Once the volume reaches the maximum level, the volume will begin to decrease determined the 'Decay' setting. Volume decreases at the 'Decay' rate until in reaches the 'Sustain' level. Volume then remains constant until the 'key is released, causing the volume to decrease according to 'Release' rate.
In this design, I am using attenuation, so the ADSR cycle will look more like this:

The Red line is the normal gain or amplification signal, while the Green line is the inverse or attenuation signal.
Voice Module - VCF
Instead of a normal VCF I will be using a tunable State-variable active filter and a analog multiplexer to choose the filter type. The chosen filter is a 2-pole filter. There are two timing element pairs made up of a resistor (U3 - dual 50K digital potentiometers) and a capacitor C6 and C5 (22nF). The Digital potentiometers will range from 50KΩ to ~200Ω, so the filter center point frequency should range from 144Hz to ~36KHz. The analog multiplexer (U7 - lower right hand corner) is a MC74LVX4052 and is used to route either the Highpass, Lowpass, Bandpass or the unfiltered signal to the Voice Module output port.
The Voice module all fits on a 1.0" x 1.5" PCB. The bottom connectors (J1 ans J2) will plug into a back-plane connector on the main board. Here are the layouts for the top/bottom of the 2-layer PCB.


The J1 connector supplies the supply voltages (5.0V and 2.5V) and grounds, along with a daisy-chained serial bus. Each Voice module board will receive a serial stream from the main board. Each processor will capture its data and forward any additional information to the next module in the daisy-chain. The J2 connector routes the output signal to the main board into a mixing circuit.
Main Board/Back-plane
The synthesizer main board contains a USB to serial converter (U1 - FT230X) which will communicate to a PC-based control panel. Data is passed to the processor (ATtiny 3226) which will process the MIDI date and generate control command to send to the string of voice modules. The board also contains a Voice Module back-plane and a mixer (summing circuit) and a 1 Watt amplifier. Between the summing and circuit and the amplifier is a header to mount an Echo processor module. If the Echo Module is not desired, a simple jumper will connect the summing circuit output to the amplifier.
The summing circuit has a digital potentiometer to control the overall volume.
Here is the schematic of the Main Board:
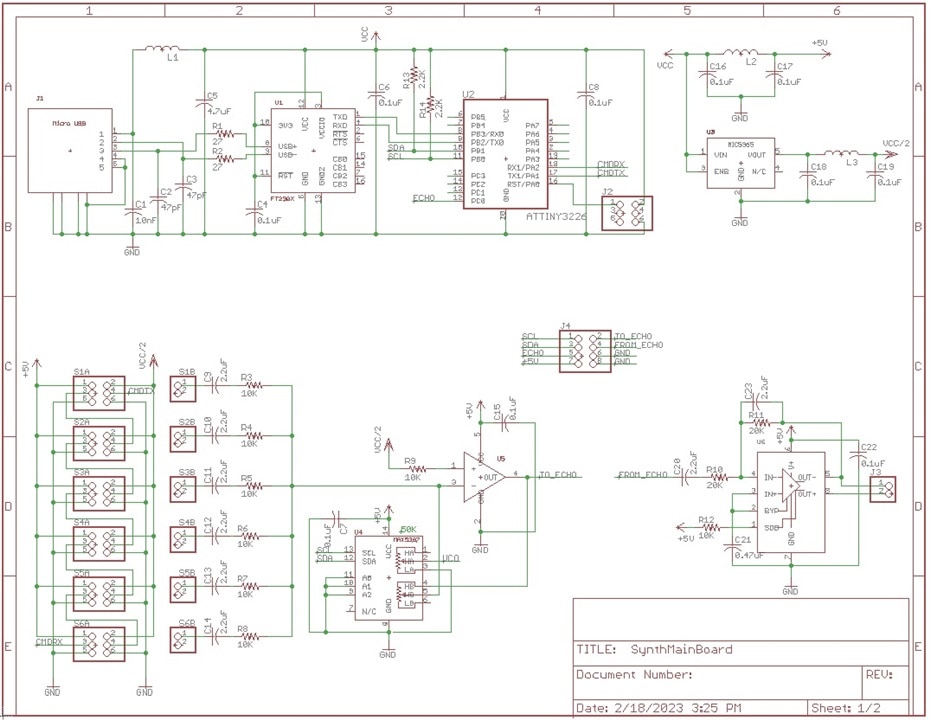
The PCB of the Main Board is 2.0" x 1.5" and can be used to add up to six Voice Modules. Here are the layouts for the Main Board:


Echo Module
The Echo Module uses a PT2399 which is a echo processing (delay) chip the uses a ADC/DAC pair that are coupled to a 44Kbit RAM. By varying the clock rate on the sampling circuits you can control the delay time through the RAM. I had run into this chip for a audio delay product that I built, so I have some experience with this chip (This chip is also the heart of KORG monotron DELAY module that produces some crazy effects).
The echo processing module is connected to a pair of digital potentiometers one to control the sampling clock and the other to control the amount of the delayed feedback signal that is applied to the input signal. There is also an analog switch is select either the input signal or the delay/modified signal to apply to the Main Board amplifier.
Here is the schematic for the Echo Module:

The PCB of the Echo Module is 1.0" x 1.5" and here are are the layouts:


Next Steps
All of the PCBs are on order and so are all of the necessary parts (PCBs should be in next week). I am currently working on write code for the Voice Modules.
I am already thinking that I might want to do a second revision to the Voice Modules to allow for an external oscillator and possibly an external EEPROM/FLASH for wave-table storage.
I am sure that I will be tuning and tweaking on the Voice Module filter and the Echo Module (slightly different implementation with this part as my prior design was delay only and this time I am mixing the delayed signal to develop an echo).
I will need to design code for the ATtiny3226 on the main board (MIDI decoder, Voice Module control, Mixer/Volume control and Echo Module control.
I will need to design code for the Voice Module to act as a noise source.
I want to look at adding tremolo and vibrato effects into the Voice Module (varying amplitude and varying pitch via software control of the attenuator and the oscillator).
As I get more of the code complete, I will start writing software descriptions. As I get the hardware more defined, I will generate and post updated documents and BOMs.
Design some 3D printed frames to hold all the modules and a speaker into a rigid form.
And finally, I will need to record a video to prove that it all works.
Thanks as always for reading along and keep an eye out for updates to the project!


