


We know SPI as a 4*-wire protocol. But it doesn't have to be. I'm checking high speed SPI data transfer with buffers, DMA and parallel data lines.
In this blog, I finally got everything working. I'll show a single buffered SPI Master with DMA and 4 data lines. The next one will be the Slave side, with multi-buffering and trigger based action.. |

Attention: there's pre-knowledge required.
For this blog it's expected that you have decent Hercules skills and that you can successfully replicate the mibSPI DMA example from HALCoGen TMS570LC43x Help.
Don't start with this project if that example isn't fully familiar to you. It would be a sure path to frustration.
On the other hand, if you're adventurous, go ahead and jump right in. Here is a not often blogged about subject.
It took me two and a half years to get here. I did the first investigation in May 2016.
The main slow-downs were that I don't know the subject well, the Hercules family is a complex device.
And the example I had was for a different microcontroller of the family than the one I have.
I needed help to get subtile device differences ironed out of my port exercise.
It's thanks to DAB 's follow ups and challenges that I maintained the drive to close this off.
Highlight for SPI performance boosting
- SPI communication handled by two autonomous controllers without using microcontroller resources.
DMA controller and SPI peripheral do the work on their own.
- Efficient memory access model: DMA reads 64 bits per time to minimise the number of times it accesses RAM.
- The DMA and SPI controllers handle the transfer of 64 of those 16-bit data points completely without any CPU involvement.
- Parallel SPI: 4 MOSI and 4 MISO lines take care that 4 bits are sent in a single SPI clock. 4 clocks send a 16 bit value over.
- ENA support: the SPI peripheral only sends data if the Slave signals that it's ready to receive them (hardware handshake).
TL;DR: Performance data at the end of this blog post.
Inspiration:
The design, code and theory behind this two year exercise come from Texas Instruments' application note "High Speed Serial Bus Using the MibSPIP Module on Hercules If you are an application note fanboy, like me, you won't be disappointed. It's a gem. And it contains the source code for the example project that I'm using here (at least: a link to the archive that has the sources).
All not-source-mentioned images and quotes that seem to come from an application note or datasheet in this blog come from that note. If not, I mention the source. Just assume that every image, quote and table that doesn't have a reference comes from that application note. |

Parallel Mode SPI: 2 X 4 data lines
Classic SPI uses 2 data lines. 1 from master to slave, MISO (in Hercules lingo SIMO), and one in the other direction.
That means that you can beam one bit per clock pulse. SPI is duplex.
Data can run from master to slave and slave to master at the same time.
Parallel Mode SPI is the same concept, but (in this example) 4 data lines each way. 8 in total.

image from the application note: parallel mode SPI
In one clock tick, you can exchange 4 bits to and from the master and slave. 4 times as fast, at the cost for PCB space.
And both sides have to support it.
It does mean however that, if you do 8 bit SPI, your data is exchanged in 2 clock ticks instead of 8.
In the example that I show here, we're sending 16 bit numbers. A number takes four clock ticks instead of 16.
You'll see that there's always a fifth clock tick in my example. That's because I've enabled parity. A 16 bit value actually take 5 clock ticks in that case, with tick 5 sending the parity check. An integrity check at the cost of a clock tick per four data points exchanged.
If speed is more important than integrity ( or integrity is of low importance, e.g.: video or audio over SPI), you can turn off the parity check and have 4 clock cycles for 16 bits. There are other optimisations that can be made o the code.
The SPI has some wait times configured:
On a well designed PCB with a responsive Slave, you can up the speed and cut the waits. I'm using a breadboard here. In the real world, the slave data sheet will indicate maxima and minima. |

Handshaking in SPI - Slave Can Hold Off
SPI allows to use an enable signal. This is part of an optional two-way handshake.
The Master uses the CS to tell the slave it's ready to send.
Then it waits until the Slave pulls the ~ENA line low before starting the data streaming.

image from the application note: chip select rom Master and enable from SLave working hand in hand
In particular when exchanging loads of data, it's possible that the receiving side needs some time to process the buffer.
That's often needed before being able to accept a next burst.
Because the master knows when it is ready, it can use the CS to signal the slave.
To also allow the slave to report readiness, the ~ENA is introduced.
The ENA time-outs in the HALCoGen setup image are used by the master to keep on generating ~CS signals.
It sends a ~CS. When the ~ENA is not coming, it gives up after the timeout and starts with a fresh ~CS.
Hardware needed:
For ease of mind, I suggest a LAUNCHXL2-570LC43LAUNCHXL2-570LC43 LaunchPad. The attached example is for that board.
This blog is written specific for the Hercules microcontroller family. To play along you'll need one of those You'll need one that at least supports one MibSPI (multi bufferd SPI) and DMA.
image from the application node: physical connections betwen Master and Slave - in this case two Hercules controllers
The example here uses a TMS570LC43. The original TI example is designed for an RM48. Many more of that family support MibSPI and DMA, and are available as LaunchPads (cheap!) or development kits (expensive!). In the LaunchPad gamma, the RM42 and TMS570LS are not ok. They don't have DMA. The other Hercules Launchpads, at the time of writing, have a microcontroller with the necessary hardware. If you use something else than the TMS570LC43 or RM48, you'd better have the skill to understand the DMA part of the technical reference manual of your controller, understand endianness and memory mapping + linker command file syntax. You'll need it.
If you have an 8 line logic analyser or a SPI Client IC that can take SPI data as documented here, you're ok. Else, get a second Hercules LaunchPad to act as the SPI Client. The next blog post will review the Slave firmware. |

Hercules SPI Driver Configuration
Here's an overview of the driver setup.
The HALCoGen tool that I use turns these settings into register configuration for the Hercules, and into APIs for all drivers used.
This is a full-lifecycle tool.
You can - if you follow some non-intrusive rules - keep on using this configurator together with your firmware C code and go back and forth.
I would not call it round-trip, because changes in your firmware aren't reflected in the tool.
But you can make changes to the config in HALCoGen and let it generate new sources, without loosing any of your work.
In this example we're using Hercules' bufferd SPI mode, MiBSPI.
This is fully compatible with the SPI standard and allows for advanced buffering with DMA management.
In this 4a blog, I'll use a single SPI data buffer. In the next blog, 4b, there 'll be multiple buffers (hence MibSPI).
The microcontroller can process the data of one buffer while the SPI slave module can rerieve traffic and fill a next buffer with DMA.
That 'll be the real fun. The microcontroller performs activities while in the background, SPI and DMA provide data.
The image below highlights the settings for this project (click for full scale).
No need to manually replicate them. I've attached the full project to this blog.

image: the HALCoGen SPI settings.
The Delays are shown at the start of the blog post. If you use a logic analyser, set Enable pin HighZ and connect ~ENA to ground.
The Data Format and Transfer Groups configuration (lower left) are of particular interest.
The transfer group will be selected in our code.
The group determines the format.
In our code, we'll select Transfer Group 0. That group selects Data Format 4.
So all settings of the image above are used in our firmware.
You can set up multiple combinations, but in this example it's only these two.
Two check boxes of interest are the Parity enable and Wait for enable options. By setting these, you opt in to two optional functions. When you enable parity, extra info will be sent after the core data flow. An extra clock tick is used to send offer a parity check number. This will then be used in the client to validate integrity of the traffic. The second option is the one that lets the master deal with - and expect ! - the ~ENA signal from the client. Both are a trade of between reliability and speed. They have impact on the performance.
The parity option will add an extra clock tick after the data is sent. So your communication will last one clock tick longer. The ~ENA option adds delays because the Slave has to react on the ~CS and pull the~ENA low. It takes time. This is not uncommon. Reliability measures often have impact on the raw speed. |
Further firmware details are discussed in the second part of this blog post.
I'll add logic analyzer captures to get some life in that section  .
.
Share RAM with DMA Controller
By default, RAM is cashed for the CPU (read and write) on a Hercules controller.
If we leave that caching scheme as default, the DMA would not see the values that the microcontroller writes to the buffer.
I've written a separate blog that explains step by step how to change the cache settings of a limited area of memory for DMA access:
https://www.hackster.io/jancumps/hercules-configure-memory-cache-for-dma-0945cd .
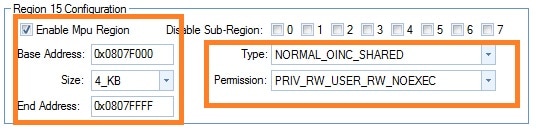
RAM (RW) : origin=0x08001500 length=0x0007DB00
SHAREDRAM (RW) : origin=0x0807F000 length=0x00001000
// ...
.sharedRAM : {} > SHAREDRAM
image and example: make 4 KB of RAM shareable between CPU and DMA
These settings have to be done for this project too. The attached archive has the implemented.
Firmware
First the bookkeeping. The buffer for the data we're sending needs to be in the shared RAM.
// all data before the first SET_DATA_SECTION pragma will reside in the default location for that type of data
#pragma SET_DATA_SECTION(".sharedRAM")
// everything declared from here on will reside in memory region SHAREDRAM
#pragma DATA_ALIGN(source, 8); /* Note: It is very important to keep the data alignment on 64-bit for the DMA */
static uint16_t source[64];
#pragma SET_DATA_SECTION()
// all data after a SET_DATA_SECTION pragma without parameters will reside in the default location for that type of data
The SPI and DMA part are configured next.
mibspiInit();
mibspiREG5->DMACNTLEN = 0ul; /* Disable Large Count */
mibspiREG5->DMACTRL[0] = ( 1ul << 31) /* Auto-disable of DMA channel (in MibSPIP) after ICOUNT+1 transfers. */
| (63ul << 24) /* Buffer utilized to trigger DMA transfer. */
| ( 0ul << 20) /* RXDMA_MAPx */
| ( 2ul << 16) /* TXDMA_MAPx */
| ( 0ul << 15) /* Receive data DMA channel enable. */
| ( 0ul << 14) /* Transmit data DMA channel enable. */
| ( 0ul << 13) /* Non-interleaved DMA block transfer. This bit is available in master mode only. */
| ( 0ul << 8); /* ICOUNTx */
/* Enable DMA module : this brings DMA out of reset */
dmaEnable();
/* Configure DMA Control Packed (structure is part of dma.c) */
g_dmaCTRLPKT.SADD = (uint32_t)(&source[0]); /* initial source address */
g_dmaCTRLPKT.DADD = (uint32_t)(&(pMibSpiP5Ram->tx[0].data)); /* initial destination address */
g_dmaCTRLPKT.CHCTRL = 0ul; /* channel control */
g_dmaCTRLPKT.RDSIZE = ACCESS_64_BIT; /* read size */
g_dmaCTRLPKT.WRSIZE = ACCESS_16_BIT; /* write size */
g_dmaCTRLPKT.FRCNT = 1; /* frame count */
g_dmaCTRLPKT.ELCNT = (sizeof(source) / sizeof(source[0])) / 4; /* element count */
g_dmaCTRLPKT.ELSOFFSET = 1ul << g_dmaCTRLPKT.RDSIZE; /* element source offset */
g_dmaCTRLPKT.FRSOFFSET = 0ul << g_dmaCTRLPKT.RDSIZE; /* frame source offset */
g_dmaCTRLPKT.ELDOFFSET = 2ul << g_dmaCTRLPKT.WRSIZE; /* element destination offset */
g_dmaCTRLPKT.FRDOFFSET = 0ul << g_dmaCTRLPKT.WRSIZE; /* frame destination offset */
// g_dmaCTRLPKT.PORTASGN = 4ul; // port b Note: this is for the RM48.
// A TI expert has helped to point out that for TMS570LC43, DMA port A reads memory, port B writes to peripherals:
g_dmaCTRLPKT.PORTASGN = PORTA_READ_PORTB_WRITE;
g_dmaCTRLPKT.TTYPE = FRAME_TRANSFER ; /* transfer type */
g_dmaCTRLPKT.ADDMODERD = ADDR_OFFSET; /* address mode read */
g_dmaCTRLPKT.ADDMODEWR = ADDR_OFFSET; /* address mode write */
g_dmaCTRLPKT.AUTOINIT = AUTOINIT_ON; /* autoinit, on, MIBSPI controls DMA transfers (ICOUNT) */
/* Assign DMA Control Packet to Channel 0 */
dmaSetCtrlPacket(DMA_CH0, g_dmaCTRLPKT);
/* Assign DMA request: channel-0 with request line - 8 */
dmaReqAssign(DMA_CH0, 6ul); /* Request Line 6 is MIBSPI5[2], this is MIBSPI5 in buffered mode */
/* Set the DMA Channel 0 to trigger on h/w request */
dmaSetChEnable(DMA_CH0, DMA_HW);
/* Enable Parallel Mode for high data throughput */
mibspiPmodeSet(mibspiREG5, PMODE_4_DATALINE, DATA_FORMAT0);
The Technical Reference Manual of the TMS570LC43 can help to understand what's happening above.
In essence, the SPI settings done in HALCoGen are made active, and prepared for DMA operation.
DMA is enabled. The addresses for RAM and SPI buffer are registered, The read and write sizes are set, and other bookkeeping.
At the end of this configuration block, the parallel mode is configured.
The execution loop only once calls the transfer function
do
{
static _Bool qFirstLoop = true;
static uint32_t u32Count = 0ul;
ui16Check = 0u;
while(dmaREG->PEND & (1ul << 0) != 0ul)
{
/* Wait till DMA TX transfer has been finished */
}
while(mibspiREG5->DMACTRL[0] & (1ul << 14) != 0ul)
{
/* Wait till DMA TX transfer has been finished */
}
/* Generate some dummy data to send */
for (i32Index = 0l ; i32Index < ((sizeof(source) / sizeof(source[0])) - 1); i32Index++)
{
/* Calculate a checksum for the dummy data packet */
ui16Check += ui16Index2;
source[i32Index] = ui16Index2++;
}
/* Add checksum to the end of the data packet */
source[(sizeof(source) / sizeof(source[0])) - 1] = ui16Check;
/* Enable DMA control in the MIBSPI, this will be auto cleared (Auto-disable of DMA channel Feature) */
/* The first DMA request pulse is generated right after setting TXDMAENAx to load the first transmit data. */
mibspiREG5->DMACTRL[0] |= (1ul << 14); /* Transmit data DMA channel enable. */
if (true == qFirstLoop)
{
while(dmaREG->PEND & (1ul << 0) != 0ul)
{
/* Wait till DMA TX transfer has been finished */
}
/* Trigger MIBSPI transfers */
mibspiTransfer(mibspiREG5, 0ul);
qFirstLoop = false;
}
else
{
/* Do Nothing */
}
if (u32Count % 10000ul == 0ul)
{
gioSetBit(LEDPORT, LEDPIN, !gioGetBit(LEDPORT, LEDPIN));
}
u32Count++;
}
while(1);
A Look at the Data
The captures below zoom into the data. The first one shows a full burst.
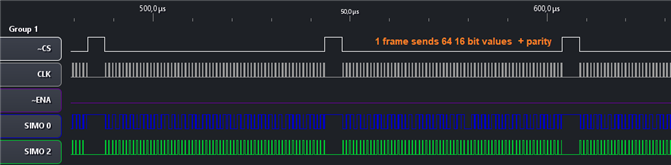
If we drill in a little, you can see the clock pulses, each time grouped by 5.
The first one is the parity, the others are are the data ticks (4 bits in parallel per tick).

The LaunchPad that I have does not break out SIMO 1 and 3 to an easily reachable pin. That's why I only have 0 and 2 on the display.

The SPI analyser shows that one frame has 80 4 bit chucks.
64 values, and 16 parity values.
The SPI analyser does not understand parity. It thinks it's just data.
For comparison, I've also taken the capture of a transfer without parity:
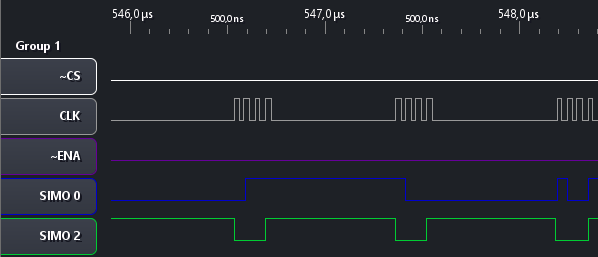

You can see that now the number of values exchanged is exactly the 64 that we expect. Just the data. No parity.
That's it. I recognise that this blog post is only applicable to a niche. I hope that this is ok on e14.
Maybe some of it (at least some of the practice) is translatable to other devices.
Top Comments
-

Robert Peter Oakes
-
Cancel
-
Vote Up
+2
Vote Down
-
-
Sign in to reply
-
More
-
Cancel
Comment-

Robert Peter Oakes
-
Cancel
-
Vote Up
+2
Vote Down
-
-
Sign in to reply
-
More
-
Cancel
Children