


This is the 4th of a series exploring TensorFlow. The primary source of material used is the Udacity course "Intro to TensorFlow for Deep Learning" by TensorFlow. My objective is to document some of the things I learn along the way and perhaps interest you in a similar journey.
Recap
In the 2nd post and 3rd post simple image recognition was explored using a training dataset of 60,000 images and a test dataset of 10,000 images. The dataset contained 10 classes of clothing and had a single dense layer. An activation function called ReLU was used to introduce nonlinearity.

An accuracy of 87% was obtained on the test dataset using a single dense layer. In this post the concept of convolutional neural networks is introduced with the objective of improving accuracy.
Convolutional Neural Networks
Like the other neural networks explored so far, convolutional neural networks, or CNN, are composed of an input layer, an output layer, and hidden layers between them. The layers alter the data to facilitate learning specific features. ReLU which was discussed in the 2nd and 3rd posts is one of the layers commonly used. The other two which will be discussed in this post are convolutions and pooling.
Convolution puts the input through a set of filters which "activate" certain features of the image. Pooling simplifies the output by performing downsampling which speeds up the processing. These operations are repeated over many layers with each layer learning to identify different features.
Convolutions
The primary purpose of the convolution layers is to extract features from the image and they act as filters (also called kernels). If you have used Photoshop or GIMP you will have seen filters that sharpen, blur, accentuate edges, add contrast, etc. The convolution layers behave somewhat similarly but there are important differences:
- They work on small portions of the image
- They are not specified by the user - they are learned
The last point is the source of power - the filters are learned during the training process. Typically filters are specified to be 1x1, 3x3, 5x5, and up to 7x7 pixels with larger filters used on larger images. Remember that grey scale images are represented as two dimensional arrays in a computer. In the following simplified example from the Udacity TensorFlow training a 3x3 filter is applied to a 6x6 pixel image.

The convolution is working on the pixel highlighted in green at left and the 3x3 filter occupies the space inside the orange square. The filter or kernel is shown in the middle diagram. Mathematically it multiplies the value in the kernel times the value in the corresponding pixel in the image. So, for example the upper left pixel in the area being convolved (2) is multiplied by the value in the filter (1). This is repeated for all pixels as shown beneath the kernel and all the values added up. The resulting value is 198 and this replaces the original value of 4.
The filter continues sliding across the image until all pixels are convolved. The pixels on the edge are a special case and usually "padded" with zeros so that the data is not lost.
There is a good discussion of convolutional layers in Keras here.
Max Pooling
Max Pooling is one of several methods of reducing the size without losing important information. A window of user specified size, e.g. 2x2 is applied to the convolution output and the max value in the window selected. It is then slid by the stride length to the next area to be pooled. Using the convoluted example from above:
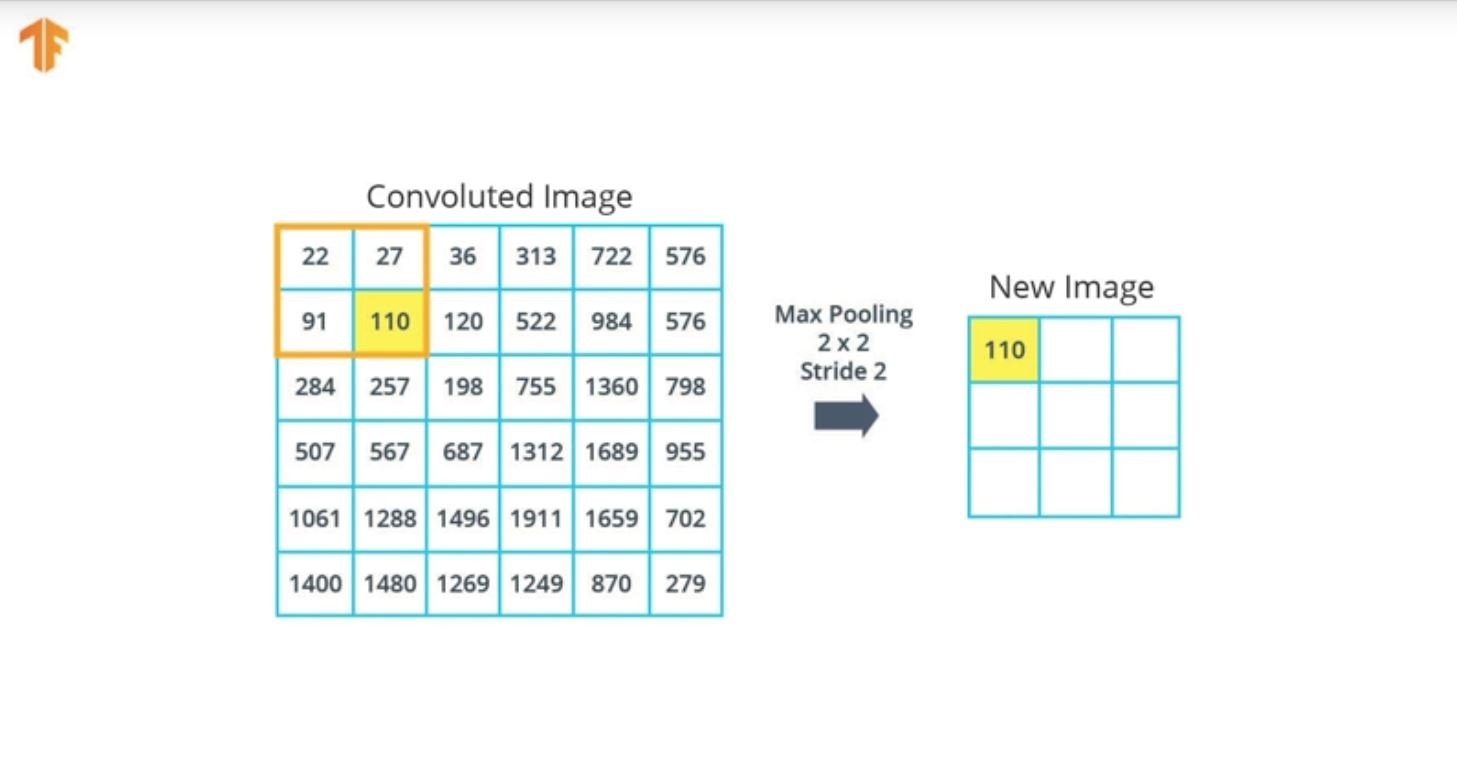
The convoluted image is reduced from 6x6 to 3x3. Only the max value in the window is used for the new image as shown below.

I find it amazing that these relatively simple steps from a conceptual standpoint are the basis for state of the art image recognition.
Developing a Model
To demonstrate CNN the same NMIST dataset used in the 2nd post will be used in a new Colab model. The dataset contains 60,000 images in the training set and 10,000 images of clothing in the test dataset. Much of the model remains the same with the addition of the following to define the convolutional model:
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), padding='same', activation=tf.nn.relu,
input_shape=28, 28, 1)),
tf.keras.layers.MaxPooling2D((2, 2), strides=2),
tf.keras.layers.Conv2D(64, (3, 3), padding='same', activation=tf.nn.relu,
tf.keras.layers.MaxPooling2D((2, 2), strides=2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=ft.nn.softmax)
])The first layer is a convolutional layer with a 3x3 kernel or fliter with padding. There will be 32 convoluted outputs created from each image. The output then goes through a max pool layer with a 2x2 window and a stride of 2 which reduces the size of all 32 output images. Following, a similar round with 64 convoluted images is created and a max pool layer applied. A flatten layer is then applied to create a 1 dimensional array prior to feeding a dense layer with 128 neurons. Notice the use of ReLU throughout. Finally, a dense layer with the 10 layers corresponding to the 10 classes of clothing is output using SoftMax activation.
The model is compiled and trained as before but using 10 epochs which results in (60,000 x 10) 600,000 examples as shown below.

This results in 97.5% accuracy. compared to 89% previously. Each epoch takes 26 to 27 seconds after the initial 44 seconds.
When the test dataset is run as shown below the test accuracy drops to 92%.

The drop in accuracy is due to the overtraining resulting from the use of 10 epochs - the training dataset was almost memorized. Nonetheless the achieved accuracy of 92% is considerably better than the 87% achieved previously. Rerunning with 1 epoch I get the following with the training set.

The training dataset accuracy was much reduced to 86%, but the test dataset remained fairly high at 89%. The dataset was undertrained.

In an attempt to further improve I added an additional convolutional layer with 128 images and an additional layer with 128 neurons to the model and trained for 5 epochs as shown below.

Accuracy from the training set is 95.5%. Below is the test results.

Surprisingly, the results are not as good as the initial model (91.3% Vs. 92%).
Conclusions and Looking Ahead
As demonstrated in the results above there is art to setting up the architecture of a model and lots of knobs that can be tweaked for a CNN. These include:
- Convolutions
- Number of layers
- Number of filters
- Size of filters
- Pooling
- Window size
- Window stride
- Fully connected layers
- Number of layers
- Number of neurons
- Number of epochs
In addition, the quality of the datasets for training and testing are paramount.
Coming up will be posts on color images, how to avoid over and undertraining, and improving dataset quality. As always, comments and correction are welcome. See the links below for additional information from the experts and past posts.
Useful Links
A Beginning Journey in TensorFlow #1: Regression
A Beginning Journey in TensorFlow #2: Simple Image Recognition
A Beginning Journey in TensorFlow #3: ReLU Activation
A Beginning Journey in TensorFlow #5: Color Images
A Beginning Journey in TensorFlow #6: Image Augmentation and Dropout
RoadTest of Raspberry Pi 4 doing Facial Recognition with OpenCV
Picasso Art Deluxe OpenCV Face Detection
Top Comments