


This is the 6th post of a series exploring TensorFlow. The primary source of material used is the Udacity course "Intro to TensorFlow for Deep Learning" by TensorFlow. My objective is to document some of the things I learn along the way and perhaps interest you in a similar journey. In a follow-on series I intend to cover TensorFlow Lite using a Raspberry Pi.
Recap
In the last post complex color image categorization and the concept of validation was introduced. The issues associated with overfitting and underfitting the model were presented. In this post Dropout, a method for reducing overtraining will be covered as well as Augmentation, a method for increasing the training dataset size and quality.
Dropout
During training the neural network adjusts weights and biases to minimize the loss function. This can result in certain neurons obtaining large weights relative to other neurons which causes them to dominate the network. As a result the neurons with smaller weights don't get trained much. Dropout is a way to avoid this by randomly turning off some neurons in the network during training. This allows the other neurons to receive more training. For example, in the example below taken from the Udacity training two neurons (shown filled with black) are randomly turned off, one in each row during an epoch. In subsequent epochs this random selection is continued.
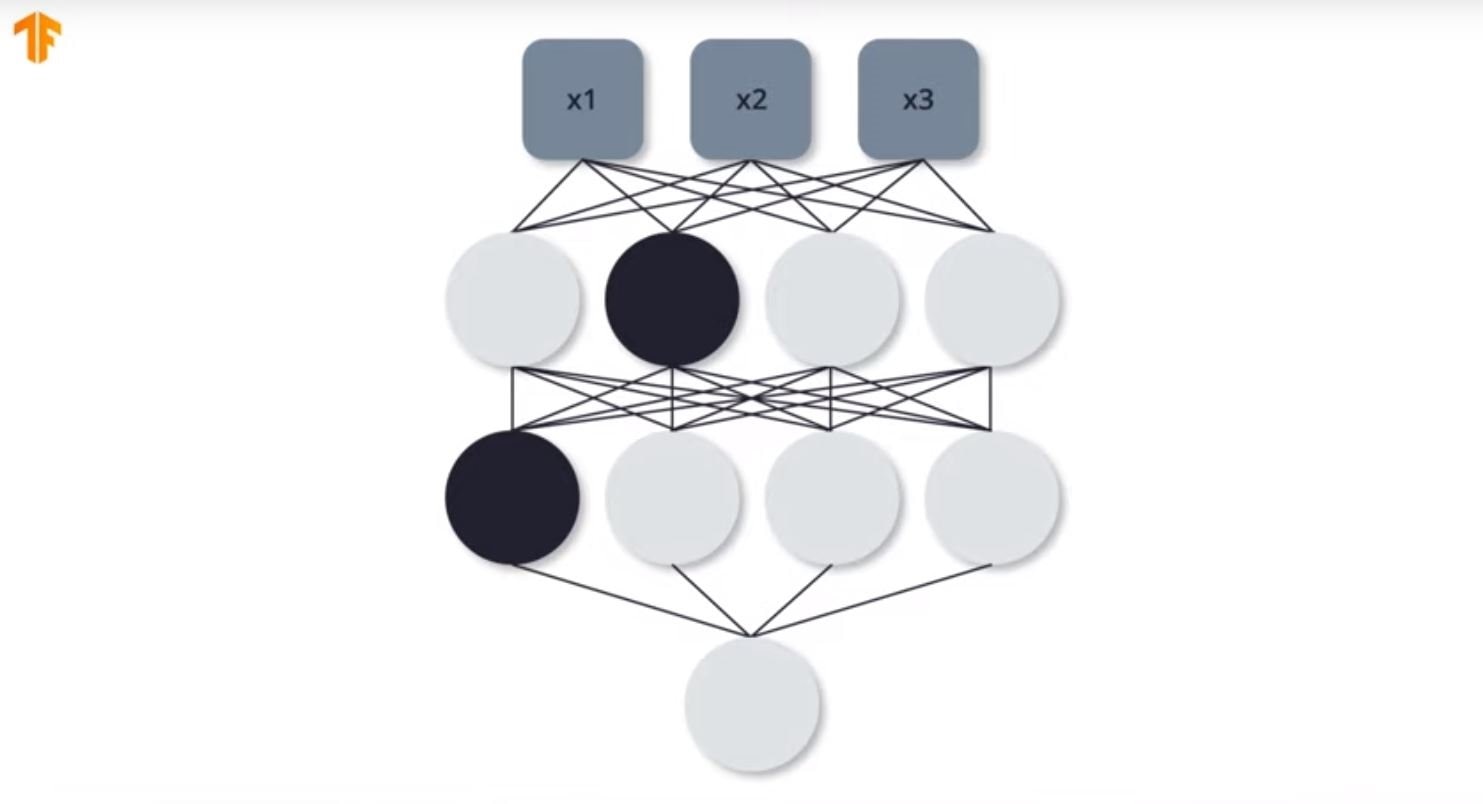
Feed forward and back propagation continues without using the neurons that have been turned off. This helps avoid overfitting and the network utilizes all the neurons more efficiently.
Augmentation
It is desirable for the model to recognize the subject no matter the size, position or where it is in the image. In a large enough dataset all of this information may be included in the training dataset and it will be less likely to overfit. If not, augmentation is a way to add examples with different angles, size, orientation, etc. which allows it to generalize better.
For example, TensorFlow can modify or transform an image as shown in the example below.

Example snippets of code and the results are shown below.
Flipping Images
image_gen = ImageDataGenerator(rescale=1./255, horizontal_flip=True)
train_data_gen = image_gen.flow_from_directory(batch_size=BATCH_SIZE,
directory=train_dir,
shuffle=True,
target_size=(IMG_SHAPE,IMG_SHAPE))
Rotating Images
image_gen = ImageDataGenerator(rescale=1./255, rotation_range=45)
train_data_gen = image_gen.flow_from_directory(batch_size=BATCH_SIZE,
directory=train_dir,
shuffle=True,
target_size=(IMG_SHAPE, IMG_SHAPE))
Zoomed images
image_gen = ImageDataGenerator(rescale=1./255, zoom_range=0.5)
train_data_gen = image_gen.flow_from_directory(batch_size=BATCH_SIZE,
directory=train_dir,
shuffle=True,
target_size=(IMG_SHAPE, IMG_SHAPE))
Building a Model
It is possible to apply all the augmentation transformations as shown in the code snippet that follows:
image_gen_train = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
train_data_gen = image_gen_train.flow_from_directory(batch_size=BATCH_SIZE,
directory=train_dir,
shuffle=True,
target_size=(IMG_SHAPE,IMG_SHAPE),
class_mode='binary')
Validation data is generally scaled but not augmented.
image_gen_val = ImageDataGenerator(rescale=1./255)
val_data_gen = image_gen_val.flow_from_directory(batch_size=BATCH_SIZE,
directory=validation_dir,
target_size=(IMG_SHAPE, IMG_SHAPE),
class_mode='binary')
The convolution and compiling of the model remains the same as the previous example. The model definition remains the same as the previous example except that a dropout of 0.5 (50% of the values coming into the dropout layer are zeroed) is specificied just before flattening and the dense layers.
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(2, activation='softmax')
])
Below is the model summary.

Remember that previously, without augmentation or dropout, the training accuracy was 100% (overfit) at 100 epochs and the validation accuracy of 75% was achieved in less than 20 epochs. Adding augmentation and dropout results in the following.
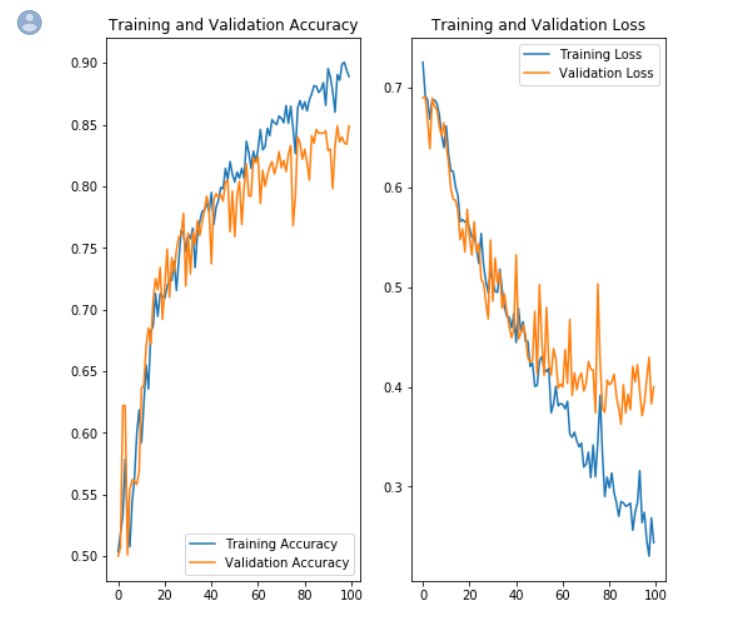
Training accuracy is now about 88% (Vs. 100% before) due to the use of image augmentation. But the image validation has improved to 84% (Vs. 75% before), a significant improvement. According to the course training video, training should probably cease around 60 epochs which is where the curves for the training and validation start to diverge.
More Useful Stuff
The following site gives more information on overfitting: Memorization is not learning!
There is some additional material in the course that I recommend but which will not be covered here::
- Transfer Leaning, a way to use existing networks created by experts for your own models.
- Housekeeping such as how to save and load models
- Time Series Forecasting
- Introduction to TensorFlow Lite
I plan to cover TensorFlow Lite in more detail in future posts.
Conclusions and Look Ahead
This brings us to the end of how image classification works in TensorFlow. At the start of the journey my knowledge was limited to following a recipe without much understanding of the underlying model. My objective was to gain understanding without going too deeply into the math. Conceptually, it is fairly easy but as they say the devil is in the details. As is often the case, XKCD is able to convey this in one frame:

My knowledge has now been extended to following recipes with a somewhat improved understanding of the underlying model.
In future posts I plan to develop my own model from scratch and move it to a Raspberry Pi running TensorFlow Lite. Hopefully I will be able to stir the pile until something useful comes out.
Useful Links
RoadTest of Raspberry Pi 4 doing Facial Recognition with OpenCV
Picasso Art Deluxe OpenCV Face Detection
Udacity Intro to TensorFlow for Deep Learning
A Beginning Journey in TensorFlow #1: Regression
A Beginning Journey in TensorFlow #2: Simple Image Recognition
A Beginning Journey in TensorFlow #3: ReLU Activation
A Beginning Journey in TensorFlow #4: Convolutional Neural Networks
Top Comments