


Machine learning does not have to be complicated models that cannot be deployed to MCUs, it could be a model-free learning algorithm. Here is a video of the final project in action.
The motorcycle balances for about 10 -15 seconds, but further training and changing the incentives of the reward function can train it to balance longer
How It All Started
Balancing an inverted pendulum is a ubiquitous example used in controls curricula, with lots of available solutions, using concepts from PID control or reinforcement learning. Even though this was my first experience with reinforcement learning, I attempted a slightly different take on the classic inverted pendulum problem.
I decided to use one of the robots from the Arduino Engineering Kit: a self-balancing motorcycle. In the motorcycle, an inertia wheel is used to balance the system instead of controlling the cart that pivots the pendulum. I wanted to apply the Q learning algorithm to the motorcycle instead of the classic cart pole problem. One major benefit to using the motorcycle was there is a high quality Simscape model available. I used this to train and test different versions of algorithm. Although the model is an approximation and did not perfectly describe the motorcycle in real life, it was a great starting point before deploying to the actual hardware.
Background
Reinforcement learning is the iterative process of an agent, learning to behave optimally in its environment by interacting with it. What this means is the way the agent learns to achieve a goal is by trying different actions in its environment and receiving positive or negative feedback, also called exploration.
In the context of the self-balancing motorcycle, the agent is the motor controlling the inertia wheel. The way it interacts with its environment is by spinning the wheel at different speeds, and the feedback it receives is the new angular position and velocity, measured by an on-board IMU. Positive and negative feedback is determined by a unique reward function; I have elaborated on the reward function below.
Here is a high-level diagram of the Q-learning iteration:

Q learning (a fundamental reinforcement learning algorithm) follows this basic set of steps:
- Initialize a Q-matrix used for selecting optimal actions
- Get the current state of the system.
- Given the current state, select the corresponding action that maximizes the reward, or if you want to explore, to gain more environment feedback, select a random action.
- Find the new state, given that action, and execute the action.
- Calculate the reward, both immediate and discounted long-term reward.
- Update the Q-matrix using the calculated reward.
- Repeat from step 2
Steps 4 – 6 occur in one timestep of execution of the algorithm.
The states that I used are the angular position (vector of length M) and angular velocity of the motorcycle (vector of length N). The actions are the torque commands (vector of length P). The Q matrix is an M x N x P vector that shows all possible states and every possible action at each state. The key is discretizing each space coarsely enough to capture the learning.
What worked and what did not
- I implemented the basic algorithm for Q-learning in Simulink and Stateflow. Stateflow was a particularly useful tool as it helped me model the discrete states of the Q-learning algorithm and incorporate both MATLAB and Simulink functions into the process.

- In my first version of the algorithm, I tried a finely discretized set of actions (the torque commands to the motor), but the matrix was too large to upload to the Arduino. I made the action space and Q-matrix more coarsely discretized and used smaller data types, such as uint16 and int8 (where appropriate) to make the code just the right size to upload to an Arduino. I learned that the smaller data types were too small a representation to train the model accurately, so I had to find some other way to reduce the matrix size without sacrificing the fine representation of its values.
- Another factor I experimented with was the exploration time, which dictates the time for which the agent chooses a random action over the optimal action to learn from its environment. I used a function that decreased the probability of exploration as time increased, and I could manually set how long I want to explore. This is represented by the variable “ep.”
- I used the provided Simscape model (from this post) so that there were no limitations on data type and size, and I could make the model smaller later. I used this model to determine the optimal learning parameters to begin training on the hardware.

- Before moving to the hardware, I had to reduce the size of the model further, so after considering other inverted pendulum controllers, I decided to go with a bang-bang (forward or reverse) controller for the smallest possible action space. This allowed me to use larger data types (floating point) to represent the Q-matrix.
- My first reward when training the hardware was the raw number of iterations through the algorithm, then I transitioned to the current reward function as the model improved.
- My current reward function prefers low angular velocities, small angles, and quicker oscillations around the balance point. A penalty is applied when the robot falls.
- I changed the spacing of the state space from evenly spaced to higher resolution around the balance point.
- I artificially increased the size action space by multiplying the bang-bang controller output by a factor that was dependent on how much the robot deviated from 0. Therefore, whatever the bang-bang controller output was then scaled up or down. These factors were found by trial and error and I found them to be 0.75 * angular position + 0.1 * angular velocity.
- My success criterion was when the robot balanced 10 seconds. However, after the goal was reached, I did not disable the training algorithm because continuing to train the model does not hurt its performance. Continuing to update the Q-matrix allows it to converge closer and closer to the optimal value.
Replication
The Arduino Engineering Kit comes with three projects, one of which is the self-balancing motorcycle. The assembly instructions are available online with the kit. Follow the instructions provided with the Arduino Engineering Kit to download the required software to program the projects.
Once the motorcycle is assembled, download the files available here and open the RL_balance.slx model.

Plug in the battery and power on the motor carrier. Run the model. It will take a while for it to upload the first time you run it.
When it is running, calibrate the IMU by picking up the motorcycle and rotating it around all 3 principal axes. The “Calibration Status” display block should display 1.

In the scope block you will see measurements for theta, theta dot and the Torque Command. Manually attempt to balance the motorcycle, while visualizing on the theta scope where the balance point is.
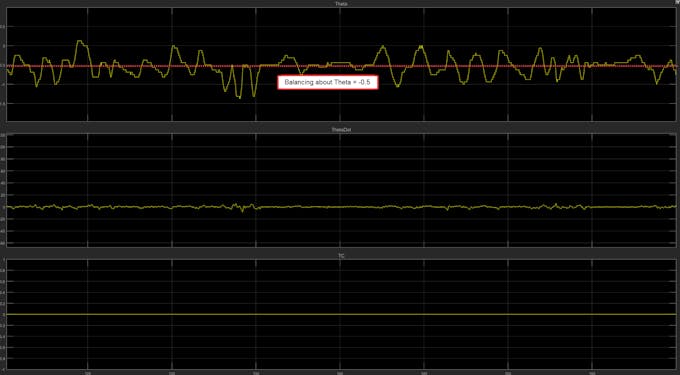
Then, use the Tilt Compensation slider to offset theta by that amount (this is inside the IMU Outputs block).

For example, if you see the physical balance point of the motorcycle is around theta = -0.5, you would move the tilt compensation slider to the right 0.5 to offset this error.
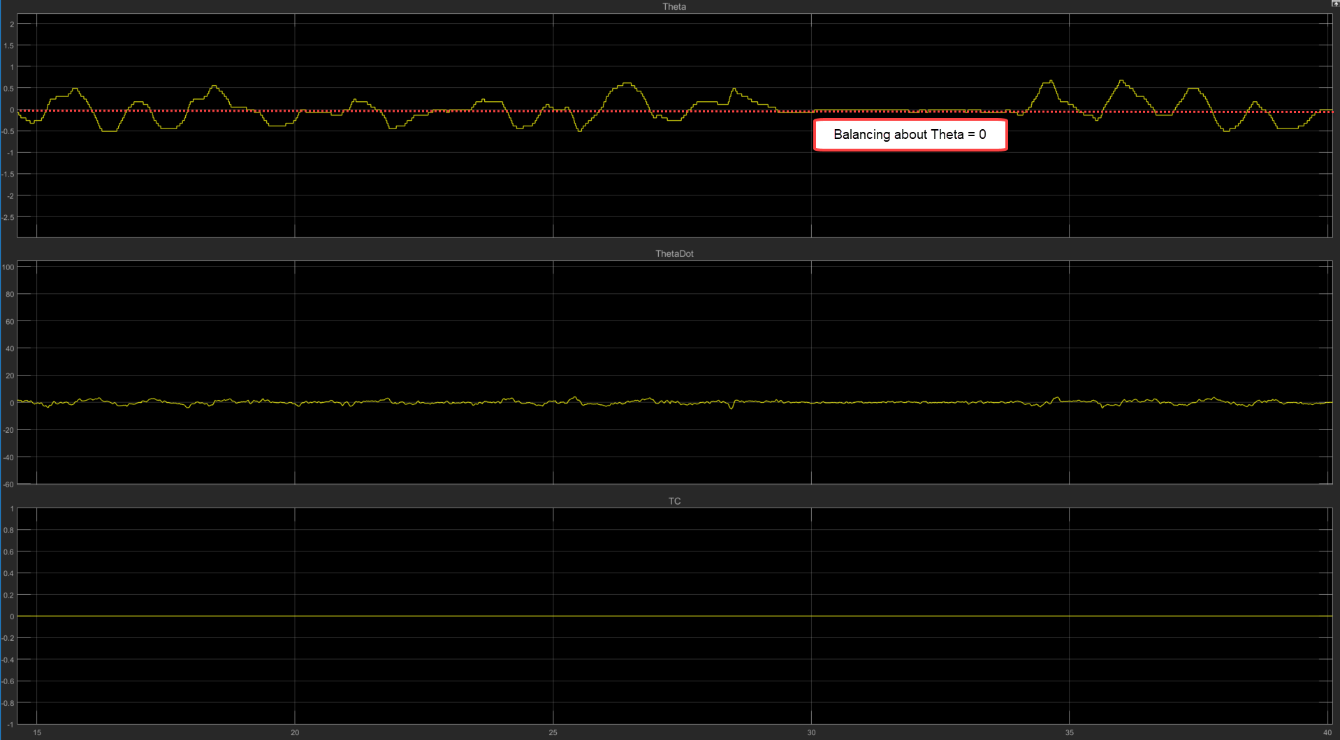
Once you have the physical balance point synced with theta = 0, then you can click the “isBal” rocker switch to indicate that the robot is balanced.

Click the “held” rocker switch once to disable the training loop. Hold the motorcycle in an upright position close to theta = 0.
 Click the held rocker switch to continue the loop, allow the motor to engage, and then release the motorcycle without pushing it in either direction.
Click the held rocker switch to continue the loop, allow the motor to engage, and then release the motorcycle without pushing it in either direction.
When the motorcycle falls, it is the end of that training. Repeat from previous step to continue training.
Have patience. To put it in perspective, 15 hours of training went in to balancing for 10 seconds.
Some things you can try to better train the model would be increasing the resolution of the state and action spaces, initializing the Q matrix to something other than all zeros, and trying different reward functions that prefer different outcomes.
The Q -learning algorithm “converges” when the goal (balancing 10 seconds) is reached. In other words, the Q -matrix does not appreciably change. Unlike neural networks where training is separate from deployment, Q-learning is model free, so deploying the algorithm is the same as training it. We can afford do this because there is low computational cost to training the Q-learning algorithm.
Useful Links:
Mnemstudio: http://mnemstudio.org/path-finding-q-learning-tutorial.htm
Why Q learning works: https://link.springer.com/content/pdf/10.1007%2FBF00992698.pdf
This is a little dense, but if you are interested, here is an introduction to reinforcement learning by the pioneers of the field: http://incompleteideas.net/book/bookdraft2017nov5.pdf
Top Comments