



Introduction
In this post, I'm taking a look at an actual VI that has been created in the Framework and covering the LabVIEW "syntax" by explaining the constructs used, and the data flows that occur. Typically, VIs are kept as simple as possible: in the same vein as OO programming, a method (VI) should do just the one thing. I don't always follow that mantra of course, the creating of VIs to undertake one-off simple tasks can be quite tedious and there's little benefit if it isn't (a) reusable in some way; and (b) obscuring the main purpose of the functionality.
Table of Contents
The VI: Update Command Settings
| {gallery}Update Command Settings VI |
|---|
|
Front Panel: Shows the Controls (inputs) and Indicators (outputs) for the VI |
|
Block Diagram: The LabVIEW code that executes when the VI is run |
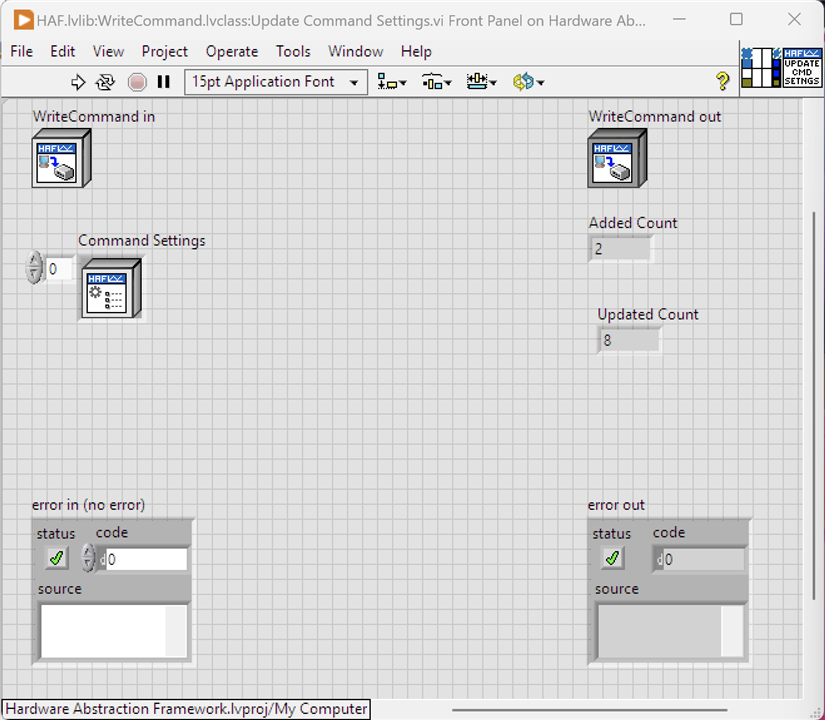

Within the Framework, a Command, in this case a WriteCommand instance, has a Property CommandSettings. This is an array of CommandSetting objects that define a setting (name) and a setting value (value), so essentially a name-value pairing. Settings are used to configure an instrument (as distinct to telling it to do something specific such as output a voltage level) that needs to be applied before a test is run; a CommandSetting is a non-instrument specific name for these, e.g. "Settle Time" and a Driver knows how to convert that to the setting specific to its instrument, e.g. "Time to Settle". It's not really important for the purposes of this post, but suffice to say, this VI takes an array of CommandSettings to update the WriteCommand's existing collection: either updating an existing one or adding to the collection if its new.
In the video below, I walk through the VI and explain the various parts. I also show it running and a brief demo of debugging and observing data values on the wire. In particular I highlight the by-value nature of LabVIEW and the dataflow execution model: although laid out in a left-to-right fashion, parts of the code run when all its data is available irrespective of where on the block diagram it lies. The art of LabVIEW programming then is to control that dataflow so the sequence of events happens in the right order!
It's a rather long video, and if you prefer a more textual description, I've tried to do that afterwards.
In Words
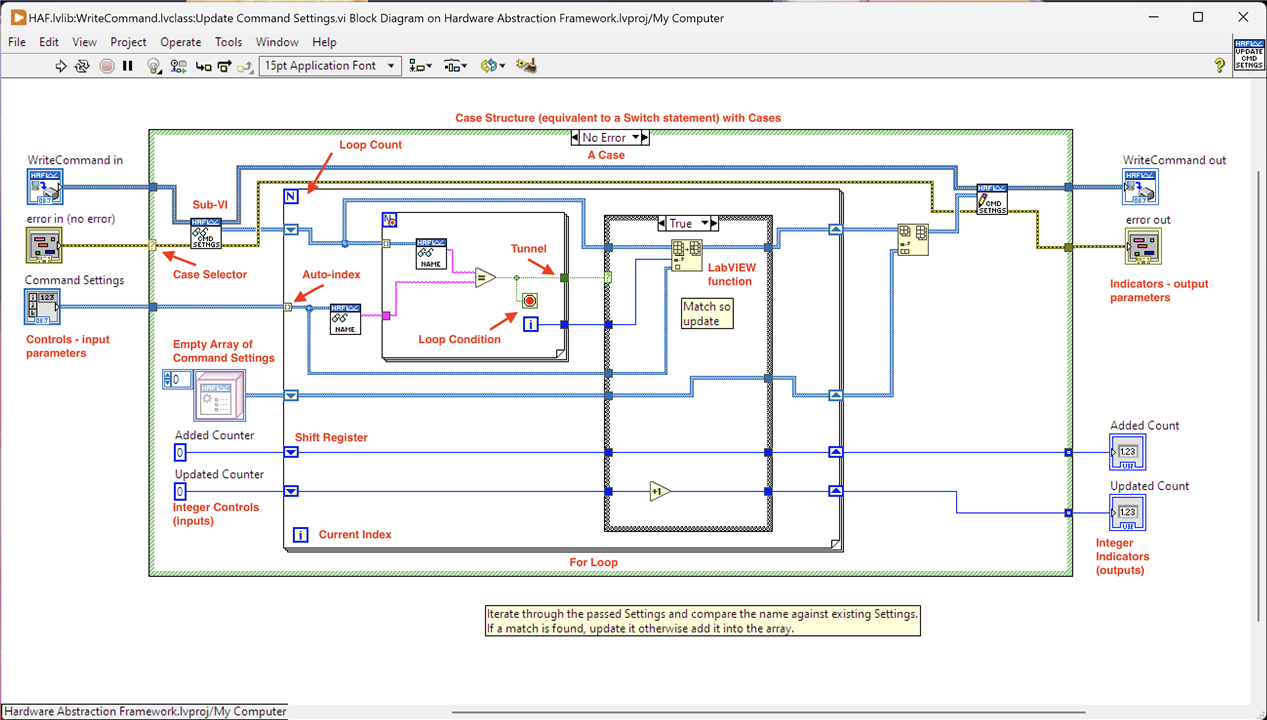
I've annotated the block diagram so it's a little more obvious what-is-what. Essentially, there are inputs on the left side that are processed through the code and loaded into the outputs on the right. Here's what it all means:
- Dataflow (not actually an annotation but covered in the video): Obviously it isn't possible to view the dataflow in a static picture so you'll have to imagine how data is moving on the wires in relation to other wires based on when the data is available. This is the basis for understanding how code execution works and it isn't necessarily sequentially. For example, the "Added Counter" inside the outer Case loop is a constant so it will flow straight to the inner Case structure whilst the inner For loop is running. It can't go any further because the inner Case doesn't have all its inputs ready yet as some come from the For loop. Notice also that the WriteCommand and Error in cluster are wired straight across the code to the write Command Settings sub-vi (the one with the pencil glyph) and the data flows there immediately. That sub-vi can't actually execute because it doesn't have all its data: it's waiting on the output of the For Loop.
- Controls: These are the inputs to the VI and can be populated via data passed to the VI parameter terminals or entered on the Front Panel UI elements. In simple VIs they would be part of the UI that the user interacts with. They carry the data to be processed.
- Case Structure: Equivalent to another language's SWITCH statement, the green box contains a set of cases that execute based on what is connected to the Case Selector. The cases are shown at the top centre - in this image "No Error". There can be as many cases as needed, including a default one when there is no match at the Case Selector.
- Case Selector: The "?" mark on the left edge of the Case Structure is a terminal that determines which Case will execute. In this image, the Error In control is wired to it and that gives a choice of "Error" and "No Error" (the latter is shown). Clicking on the drop down on the Case label will reveal the other cases which can be brought to the front and coded up. LabVIEW creates a base set of cases automatically when a data type is connected to the Selector. In the example of the Error connection, the choice is easy; ditto if a boolean is connected ("True" or "False" cases.) If an Integer, for example, were to be wired to the Selector, LabVIEW would create cases "0, default" and "1". It's simple to add additional cases in, and change around those already in place. Obviously the case that is executed at run-time, is based on the actual data value connected to the Selector.
- Cases: These are the individual cases that operate within the Case Structure (SWITCH statement.) Some are defined automatically when it's possible to do so based on the data type connected, others have to be added in manually. Code is entered into each Case.
- Sub-VI: This is an embedded piece of code, equivalent to a Function or another method. Using Sub-VIs (the one annotated is actually another method on the object WriteCommand) helps keep VIs less cluttered and provides a point of reusable code.
- LabVIEW Function: Just another name for a sub-vi although it may not be possible to actually view the code within it. These functions come with LabVIEW and are equivalent to another language's command set, albeit much richer in functionality. The one annotated is "Insert into Array" and adds a passed element into the connected array. It's not immediately obvious what these functions are, compared to, say, a command in another language or function call. It's possible to display a label stating what the function is although it seems that tradition dictates that isn't the done thing!
- For Loop: There are two in this VI: an outer one and an inner one but there's no distinction in that. It is equivalent to the For loop in any other language. It iterates around, executing the code inside the structure until the iterations are finished or it terminates early. There are two ways of indicating how many times a For loop should iterate, both covered below: Loop Count and Auto-Index.
- Loop Count: The "N" in the top left corner can be wired with an Integer that then dictates the number of iterations. Neither of the loops in this VI are wired in such a way so the loop needs an alternate way of determining the iteration count: Auto-Index. Note that in the inner For loop, the "N" has a red dot: this just signifies that the loop has a Loop Condition set so may terminate early before all iterations are complete.
- Auto-Index: If a collection, e.g. Array, is connected to the border of the For loop, the tunnel (the little blocks of various designs on the edges of structures) that creates can be changed to auto-index. This tells the For loop to iterate over the collection, one element at a time, until it has iterated over every element (or terminated early). The tunnel passes in the currently indexed element from the collection. So in this VI, the Control CommandSettings is an array of CommandSetting, and the For loop will iterate over it passing in a CommandSetting to the loop for processing.
- Current Index: This holds the current loop iteration count, starting at zero. It can be used like any other constant and this can be see on the inner For loop where it passes out to be used when the loop terminates.
- Loop Condition: The For loop can be configured to have a Loop Condition. This is a boolean flag that can be used to terminate the loop early if set to True. In the inner For loop, where it is looking for a match on CommandSetting Name, if one is found then it has what is needed and it is pointless to continue iterating. Thus the result of the equals compare is connected to the Loop Condition: True when a match is found, false otherwise.
- Tunnel: This is the means to pass data into or out of a Structure (Case, For..., While... etc) There are various types and the annotated one is passing out of the inner For Loop. On an output this can be the "Last Value" or it can be auto-index where each piece of data when the loop iterates is added to an array and the whole array is passed out at the end. Input tunnels can be just that, a Tunnel with a piece of data, an auto-index covered above or a Shift Register. It's worth noting that data is copied at a Tunnel so although the values at the start of the tunnel and the end of the tunnel are the same, in memory they are completely different pieces of data. A clear example of this is reading the CommandSettings from the WriteCommand at the start: these are passed into the loop and thus a copy is taken and the original data is no longer operated on. It's why, at the end, I have to re-write a copy back into WriteCommand at the end.
- Shift Register: This is another form of Tunnel that passes data in but which takes a new value on each iteration of a loop. Take the Updated Counter as an example. At the start of the loop, zero is passed in and the tunnel is configured as a Shift Register with a down arrow. Following the wire, the tunnel at the other edge of the For loop is reached, again a Shift Register with an up arrow is reached. What happens here is that, conceptually, the value at the output Shift Register (up arrow) travels around the For Loop to the other side and is fed back in. So in essence it is a way of keeping track of changing values during the loop iterations. For this VI, a count of CommandSettings updated is required and the value increments whenever an update occurs: if a Shift Register wasn't used, as the loop iterated back around to the start the zero (initial value) would be passed in again and would obviously result in an incorrect output.
- Constants: These are inputs that are Controls in the LabVIEW vernacular but that don't appear on the Front panel. The Empty Array of Command Settings and two counters underneath it are constants. It might feel like a bit of a misnomer: take the "Updated Counter" constant as an example it is passed into the loop and at various times incremented and updated by the Shift Register so is clearly not constant at all. And this is where I re-iterate that data is actually copied at tunnels (and wire forks) so by the time it's entered the loop, it's no longer the "Updated Counter" but "a copy of Updated Counter". So a constant is a means of injecting data without creating a Control which would then appear on the Front Panel.
- Indicators: These are outputs of the VI, either as return values (parameters) or displayed on the Front Panel as part of the UI.
Hopefully that makes some sense of what is going on. Everything happens visually, there is no drill-down to some textual code somewhere. That's why some of these constructs are so feature rich, it represents everything that one might code up in a textual language. NI market LabVIEW as a tool for non-programmers because of this, but I'll leave that to you to mull over the veracity of that statement!
One More Thing
I've mentioned quite a bit in the video or wordy description but haven't mentioned anything about variables, local or global. These are so ubiquitous in other programming languages that it's hard to image they aren't extensively used in LabVIEW. In some respects they are: Controls, Indicators and perhaps Constants in the loosest sense can all be considered variables and are the standard way of conveying data. LabVIEW does have local and global variables but their use is discouraged because they are a route for race conditions given the parallelised nature of execution. Unless extreme care is taken in when they are written and when read, strange bugs can occur. It's why structures like loops have things like Shift Registers: in any other language, a track of changing value would be done with a local variable but LabVIEW provides the means to avoid that whilst still accomplishing the same goal. It's rare to use local and global variables then. The Framework as it currently stands consists of tens of classes with greater than a hundred VIs and it uses no local variables and only two global variables written at framework startup and only read thereafter. The examples I've written make more use of a small number of local variables to keep the block diagram easier to follow but again, the writing to them is tightly controlled in one place and only read otherwise.
Being aware of dataflow is paramount to creating an application in LabVIEW that doesn't exhibit strange behaviour and it is easy to get caught out. Fortunately I have learnt to recognise the symptoms of bad behaviour.
Summary
- All coding in LabVIEW is visual: there is no means of entering textually written code. The visual features and configurability of structures and provided functions is very flexible to give a developer the control needed which would be available through the command set of any other programming language.
- It's imperative to remember the dataflow nature of execution and that a copy of data is taken at structure boundaries or wire forks. Data only becomes re-synchronised if it is coded to do so. Dataflow execution leads to a parallel, non-sequential flow of control; managing the flow of data is what brings order to the program so that code elements execute at the right time.
- Frankly, it's hard to read other's LabVIEW programs without access to the code: pasting an image of a VI without functional labels showing requires a feat of memory to interpret the icons that I can only believe comes with time and patience. What useful stuff is being ejected from my brain to make room for it??