



Update:
Want to see how well benchmarking performs on the MaaXBoard Mini? Updated results including the MaaXBoard Mini are HERE.
Introduction
In the past two years, Machine Learning at the edge has proliferated. With more machine learning models capable of running on small, low power devices, and more devices capable of running them, it can be hard to know which device best suits your needs.As the ecosystem grows, benchmarking becomes more important. In order to choose a hardware platform, it’s important to know how it performs with various models. In this article, I benchmark Tensorflow Lite on MaaXBoard with a classification model (EfficientNet-Lite) and a detection model (MobileNet SSH v.1 and v.2).
Goal
I wanted to compare the MaaXBoard to two of the boards I thought were its closest competitors:
1. The beloved Raspberry Pi model 3 B+, which is cheap, has great versatility and wonderful documentation and a thriving community
2. The Google Coral, which is more expensive but is currently state of the art for machine learning on the edge
Methodology
I had originally intended to use MLPerf as the benchmark for all three devices. MLPerf is equipped with backends for Tensorflow, Tensorflow Lite, Pytorch and ONNX. Unfortunately, it doesn't include backends for the special version of Tensorflow Lite required by Google Coral's EdgeTPU, so I wouldn’t be able to compare my MaaXBoard benchmarking results to the Google Coral. While it’s possible to write your own backend for MLPerf, in the interest of time I decided to go for another benchmarking tool. However, I do still have an MLPerf article in the works.
The Coral Devboard is picky about the models it can run. It can only run quantized Tensorflow Lite models that have been pre-compiled for the edge TPU. To run on the Coral Dev Board, a model must meet the following requirements:
- Tensor parameters are quantized (8-bit fixed-point numbers; int8 or uint8).
- Tensor sizes are constant at compile-time (no dynamic sizes).
- Model parameters (such as bias tensors) are constant at compile-time.
- Tensors are either 1-, 2-, or 3-dimensional.
- The model uses only the operations supported by the Edge TPU.
Because of this pickiness, my options for finding a good benchmark were limited, so I decided to go a different route and use a "homemade" benchmark based on the one Alasdair Allan designed last year for his "big benchmarking roundup" on Hackster. I knew that he had already benchmarked the Coral Devboard (as well as several other IoT devices) in the roundup, so I decided to try his benchmark on MaaXBoard to see how it stacked up. The bonus is that I can now easily compare my hardware's benchmarks to all of the hardware that Alasdair has already benchmarked. Just like Alasdair, I ran my model 1,000 times and averaged the inference times. I also discarded the first run, so startup times aren't included in the average.

The models
Choosing a model for benchmarking is possibly the most difficult part of benchmarking. Even with a thorough understanding of your hardware's architecture, it is still difficult to judge which models will perform well. Small differences in models, like what size input image it takes, whether it was trained with "quantization-aware-training", or whether it is quantized to be purely 8-bit integers, can greatly affect the resulting speed and accuracy of the model on any given hardware.
The fact that I was planning to use Tensorflow Lite on Coral's Edge TPU narrowed down my choice of model quite a bit, since not all models can be compressed to run on edge TPU. I also knew that I wanted to benchmark image classification and detection, since those are some common uses of "hobbyist" boards.
Alasdair used MobileNet SSH v1 and v2 for his benchmarks. MobileNet is a popular image detection model for edge devices, since it's small compared to other image detection models like ResNet and Inception. One good thing about image detection is that accuracy is fairly easy to benchmark - the model either recognizes the objects correctly or it doesn't. The versions I downloaded from Alasdair's benchmarking folder were 4.2 for version 1 and 6.2 MB for version 2. The model is able to detect a 300x300 pixel image.
EfficientNet-Lite is a new version of the EfficientNet model that was created by Google for use on edge / mobile. It was just released in March, so I wanted to try that as well, since it hasn't been benchmarked at all by MLPerf. I started out by running the large image version (L) of the quantized version of EfficientNet-Lite that's available at coral.ai/models. I was pretty shocked by the results.
The image
I decided to use the exact same image that Alasdair took of an apple and a banana so that I would be able to easily compare these benchmarks to last year's benchmarks.
The dataset
The version of the MobileNet being used is trained on the Common Objects in Context (COCO) dataset. This MobileNet model is trained on a version of COCO that contains 89 different objects.
The version of EfficientNet that I used was trained on ImageNet, and is capable of classifying 1000 different objects (that's about the same number of objects a three year old human can classify!).

Spoiler alert!
When benchmarking, it's good to start with a general idea of how your benchmarks should perform.
Coincidentally, there are some basic benchmarks available for the exact same models I'm using benchmarked on the Coral Dev Board, an embedded CPU, and a desktop CPU. I actually didn't find these until after I had already performed the benchmark, which is why I was so surprised by EfficentNet-Lites's performance on the MaaXBoard and Raspberry Pi.
One really interesting thing to note is how much changing the image size slows down inference for EffiientNet-Lite. EfficientNet-EdgeTPU-S runs on 224px square images, EfficientNet-EdgeTPU-M runs on 240px square images, and EfficientNet-EdgeTPU-L runs on 300px square images. Based on these results, it looks like for every ~20 pixels you add to your input image size, you almost double the inference time. The reason to use larger images is for greater accuracy, so this is another tradeoff.
How to benchmark
See these guides for "how to" for each of the hardware. One of the "intangibles" that I didn't benchmark is the amount of time it took me to get set up.
The Google Coral was by far the most difficult to get set up in. Their mdt tool doesn't work for OSX Catalina, which caused me many hours of frustration before I finally discovered a workaround. I also ran into a small bug while installing OpenCV via pip on Raspberry Pi, but other than that it was about as easy as the setup on MaaXBoard.
- Benchmarking Tensorflow Lite on Rasbperry Pi
- Benchmarking Tensorflow Lite on Google Coral
- Benchmarking Tensorflow Lite on MaaXBoard
MY RESULTS
Performance is measured in milliseconds.
| Model | Google Coral | MaaXBoard | Raspberry Pi |
|---|---|---|---|
| MobileNet SSD V.2 | 25.82 ms | 364.28 ms | 1108.5 ms |
| MobileNet SSD V.1 | 18.87 ms | 282.31 ms | 815.38 ms |
| EfficientNet edgetpu L | 35.04 ms | 3342.87 ms | 8143.91 ms |
| EfficientNet lite0 | 180.29 ms | 365.29 ms | 637.52 ms |

As you can see, the Coral Devboard is also the fastest by a large margin, MaaXBoard is in the middle, while Raspberry Pi is quite a bit slower.
Not pictured: EfficientNet-Lite for edgetpu. EfficientNet-Lite was so slow on the Raspberry Pi that when I plotted it, it dwarfed the rest of the graph and made it impossible to see the Google Coral results. In the chart above you can see that when running EfficientNet-Lite, Coral outperforms MaaXBoard by a factor of almost 100x and Raspberry Pi by a factor of almost 300x! Why is it so much better? Google designed the model explicitly for the Coral DevBoard's TPU to be able to classify images quickly and with high performance. If you scroll up to look at the table of benchmarking results from Coral.ai, you'll see the footnote "Latency on CPU is high for these models because the TensorFlow Lite runtime is not fully optimized for quantized models on all platforms."
Thankfully, there is now a CPU optimized version of EfficientNet-Lite, so I was able to run that too. I chose the EfficientNet-Lite lite0 int-8 version available on tfhub.dev. I've included the results in the table above. As you can see, it's no longer embarrassingly slow on the MaaXBoard and Raspberry Pi's CPU. The MaaXBoard was also more accurate on this version than the Coral Dev Board was on either version - it recognized the banana every time, while the Coral Dev Board kept thinking it saw honeycomb?
I also ran the CPU optimized version of EfficientNet-Lite on the Coral DevBoard to see what would happen. It slowed down quite a bit, but the accuracy also improved! I'd like to do more tests on accuracy on MaaXBoard vs Coral Dev Board when running various versions of EfficientNet. To measure accuracy more reliably, I would need to test the benchmark on many images.
Speed vs Price
Not surprisingly, the speeds reflect the prices - I guess you get what you pay for. Here are the prices for each board overlaid on the speed of MobileNet inference:

How does the MaaXBoard stack up to other hardware? Well, the good thing is we have data from Alasdair's Tensorflow Lite benchmarks, so we can compare it to eight different platforms:
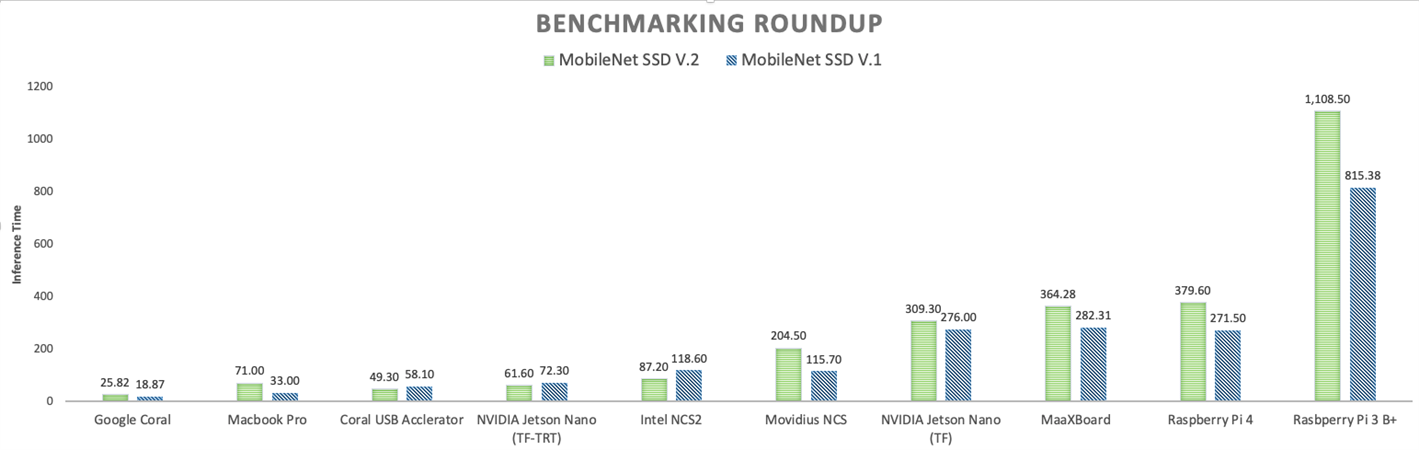
Here are the benchmarks again, this time with the hardware cost overlaid:

Accuracy for MobileNet Image Detection
MobileNet didn't predict correctly every time, especially for v.2. Sometimes it thought the banana was also an apple.
This chart maps accuracy vs speed. I measured the "accuracy" of image detection by summing the confidence of the prediction times the correctness of the prediction (1 for correct, -1 for incorrect). As you can see, there's not a lot of correlation between accuracy and speed. The main indicator of accuracy is the model itself, and the main indicator of speed is the hardware it is run on.


Getting a single measurement of accuracy for EfficientNet-Lite is more difficult, since it's a classification model that provides a list of possible labels and there's no binary "correct" or "incorrect." Using the same image of the apple and the banana, EfficientNet's guesses varied wildly, from "screwdriver" to "hook, claw." And yes, banana is in the data set. Apparently "apple" is not however - instead they have a "custard apple" and I'm not even sure what that is.
Running the inference on an image of Admiral Grace Hopper produced much more consistent results. EfficientNet recognized her military uniform every time.
Conclusion
No matter what your price range or requirements for speed and accuracy are, there is now hardware that fits your Machine Learning needs. Hopefully this benchmarking article was helpful.
Further Reading:
To learn more about benchmarking edge devices, check out Alasdair's wonderful benchmarking articles on Hackster:
Research Papers about benchmarking TinyML:
Top Comments