


Intro
Running machine vision on microcontrollers requires a tradeoff between accuracy, which typically means larger, more complex models, and speed. Convolutional Neural Networks have a number of factors that affect their on-device performance. These include model optimizations like int-8 quantization, the size of the input image, the size and depth of the filters used, and chip-specific libraries such as CMSIS-NN from Arm that take advantage of hardware characteristics.
It's possible to estimate a model's performance by looking at the model complexity, which refers to the number of multiply-accumulates (also called multiply-adds, abbreviated as MADDs or MACs) and parameters (the total number of weights/filters) in a given model. Below is a graph comparing model complexity of several types of networks (source). The size of each blob represents the number of parameters:
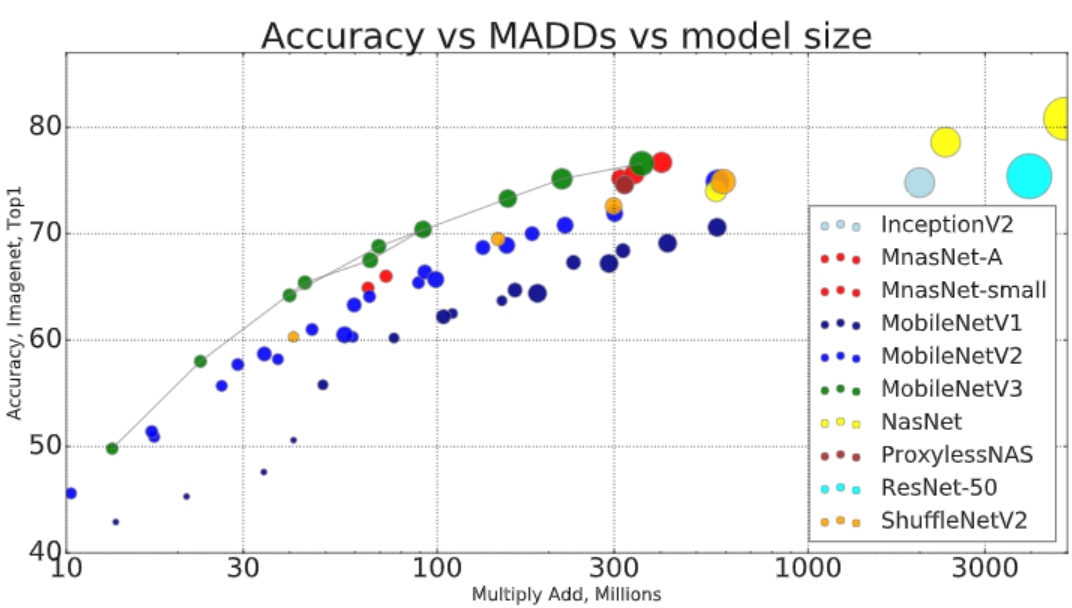
However, the actual performance will depend on each device’s implementation of these operations, so it's impossible to know how they will perform without a benchmark.
By providing benchmark data for several models of different complexities, I hope to be able to provide an indication of which models might work best for computer vision applications on the MaaXBoard RT.
Tensorflow Lite Micro
Although it is not as fast as more optimized frameworks like GLOW, Tensorflow Lite Micro is an extremely popular machine learning framework for microcontrollers because of its ease of use and portability. In order to evaluate how different computer vision models perform on the MaaXBoard RT, I chose to take advantage of Tensorflow Lite Micro (TFLM)’s built-in profiling tools. These tools allow you to profile each operation, or kernel, of a model with supposedly negligible overhead.
TFLM also provides tools to granularly measure the size of the memory buffers that are allocated at runtime to hold model data. This enabled me to look at how much of the model’s performance comes from memory accesses versus how much comes from computational cost.
Hardware Specifications
Most microcontrollers are designed for embedded applications with low cost and high energy-efficiency as the primary targets, and do not have high throughput for compute-intensive workloads such as neural networks. However, the i.MXRT 1170 on the MaaXBoard RT includes both Cortex-M7 and Cortex-M4 processors, which have integrated SIMD and MAC instructions that can be used to accelerate computation in neural networks. It also has larger than typical on-chip memory, with 640kb on the Cortex-M7 processor alone, as well as a 32kB L1 cache (see the i.MXRT1170 MCU family fact sheet and the MaaXBoard RT page for more information).
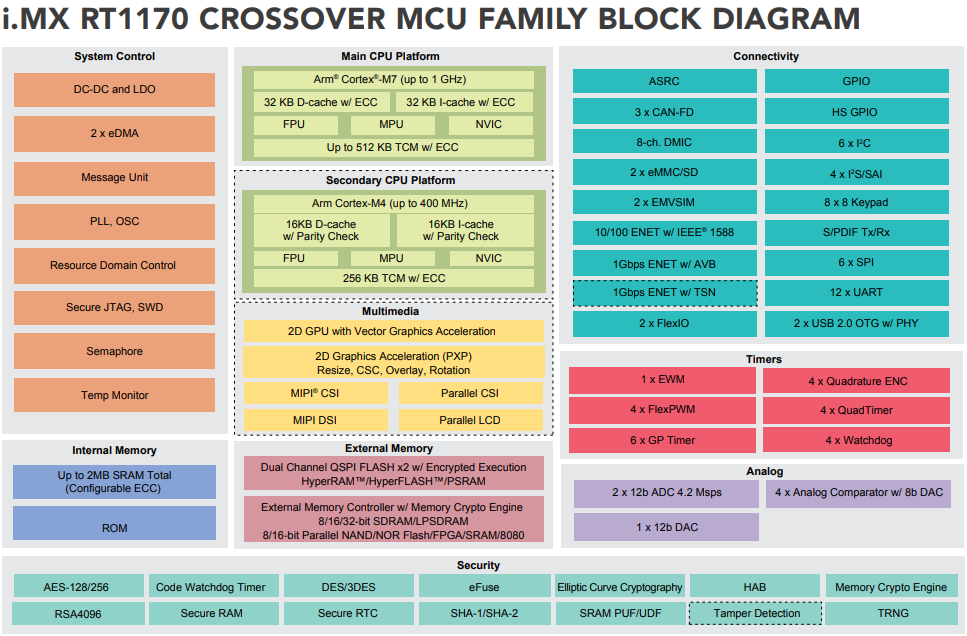
On MaaXBoard RT, Tensorflow Lite Micro integrates with Arm’s CMSIS-NN library for optimized neural network performance. This optimized library is divided into several functions, each covering a category: convolution, activation, fully connected layer, pooling, softmax, and optimized basic math. TFLM does not currently support threading or multitasking, so inference must be run on a single core, in this case, the Cortex-M7.
Benchmark Setup
Models chosen
I chose to benchmark MobileNetV1 and V2 models, which are popular models for edge image classification due to their small size.
MobileNet V1 uses depthwise separable convolutions interspersed with standard convolutions to decrease the convolution cost while maintaining accuracy. Because of these depthwise separable convolutions, MobileNet v1 does about 9 times less work than a standard convolutional model with the same accuracy (This blog explains in more detail).
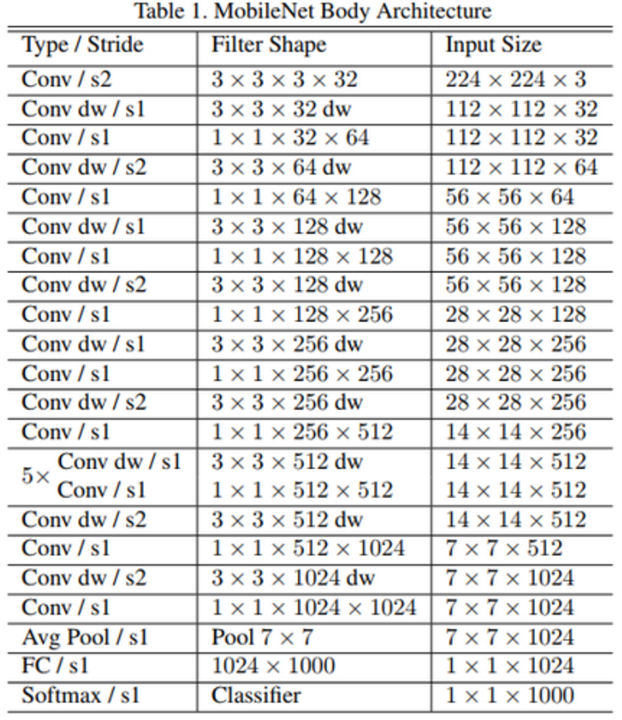
MobileNet V2 builds on the performance gains of MobileNet V1 by adding “bottleneck” layers, which are able to shrink the number of parameters passing through the model while maintaining accuracy. These allow particularly efficient memory implementations (This blog does a great job of explaining how this works with pictures).

The models have been trained and evaluated on ImageNet, which is a dataset of 1,000 objects. A typical edge computer vision task would retrain these models to recognize fewer objects, but because my goal for using these models was to stress and measure the performance of convolutional operations, I did not retrain them. All int8 TensorFlow Lite models were modified to take signed int8 inputs and outputs, which is a requirement of TFLM. From there, they were converted to C source files containing static data arrays, which TFLM converts to a serialized FlatBuffer format.
Benchmark parameters
I used an image of a stopwatch found in the RT1170 SDK as the reference image for all of the benchmarks. For each model, I ran inference 11 times. I averaged runs two through eleven, saving the first run as an initial “setup” run. The benchmark does not measure the time necessary to bring up the model and configure the run time, since the recurring inference cost dominates total CPU cycles on most systems. The benchmark uses the standard benchmarking and profiling tools provided by TFLM.
Summary of Findings
MobileNet V1
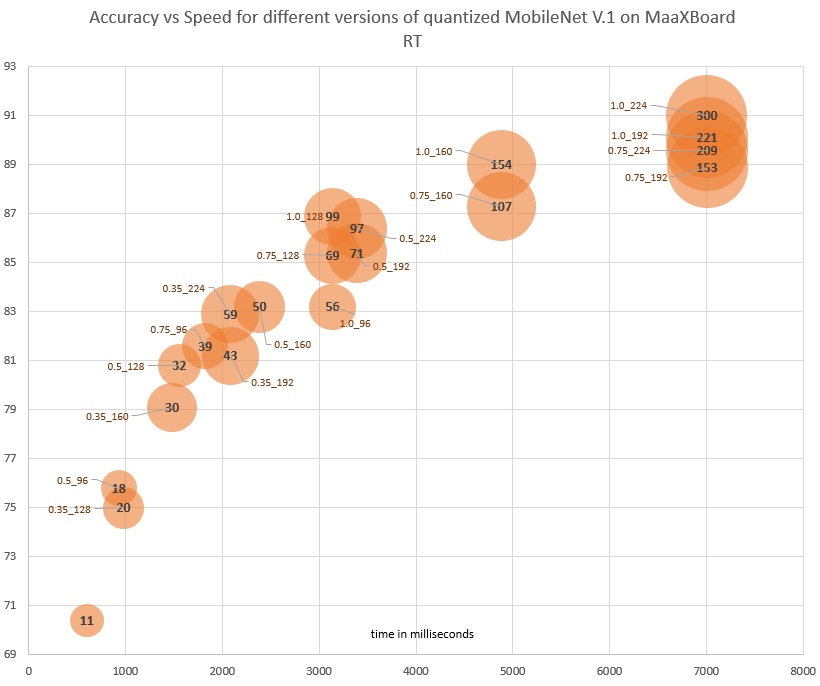
The following chart shows the performance of 16 pre-trained MobileNet V1 models with kernel-width multipliers of 0.25, 0.5, 0.75, and 1.0, and input image sizes of 128, 160, 192, and 224. The bubble size represents the required memory size, or Tensor Arena Size, for each model. I’ve overlaid this with the estimated computation time based only on the quantity of multiply-accumulate operations in each model.
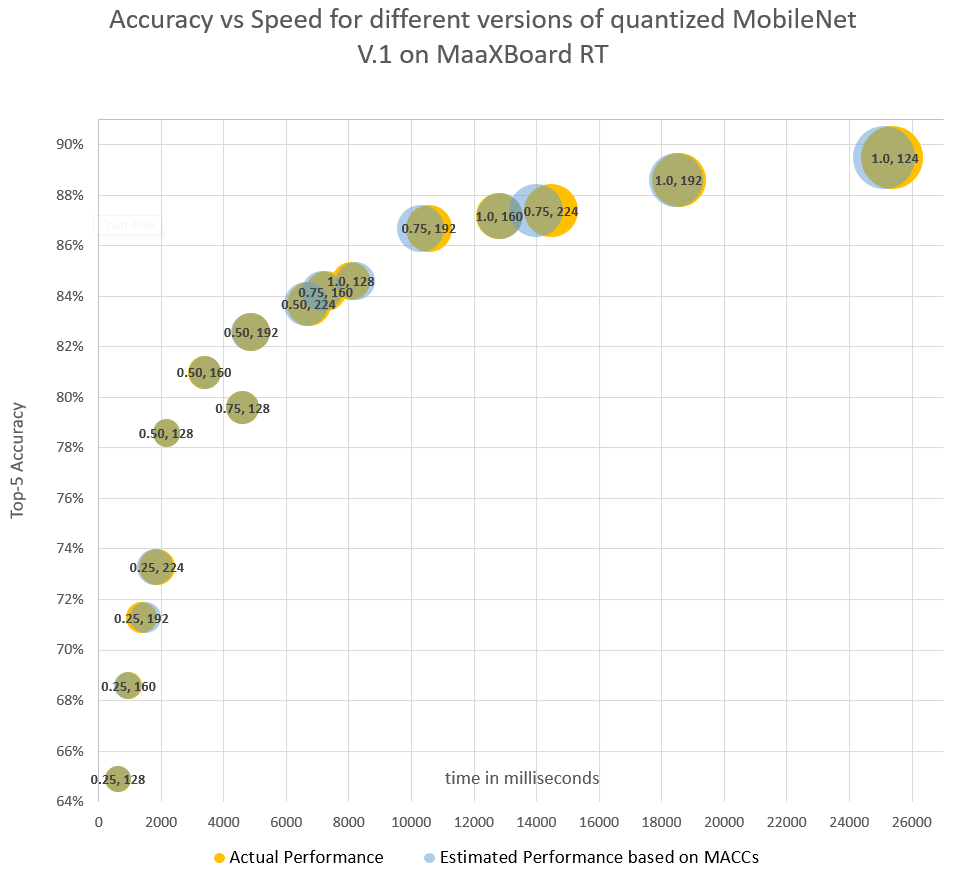
As expected, there is a strong correlation with the number of MAC operations and the speed of the model. While the memory buffer size is clearly a factor here, all of these models are larger than the 32kB cache but smaller than the on-chip RAM, so it’s not surprising to see that the main constraint is the multiply-accumulate operations.
By using the profiling tools to look at per-operation cost, I was able to dig deeper into which operations were most affected by changing the parameters of input and kernel size.
For all models, the input image size had the greatest effect on performance, and it specifically impacted standard convolution time, as shown in the chart below:
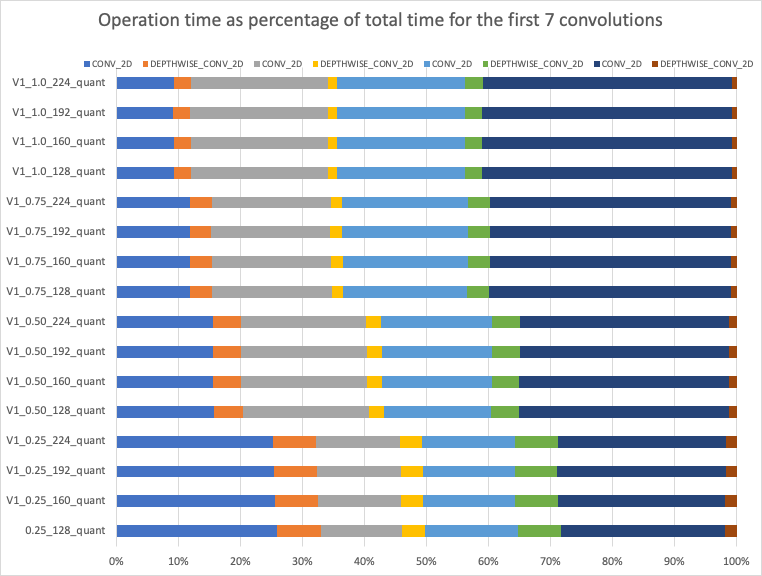
This is explained simply by the increase in MAC operations required by each convolution as the input size increases.
MobileNet V2
MobileNet V2 models are larger but have fewer MAC operations than their equivalent MobileNet V1 counterparts. The quantity of MAC operations did not even roughly correspond to the performance time, making it difficult to graph. Instead of overlaying them, each model’s MAC quantity is shown as the bold label on the bubble.
I found that for the six largest MobileNet V2 models, the model’s performance corresponded to their required buffer allocation, which is shown below as the bubble size.
MobileNet V2 has 65 separate convolutional layers, as opposed to MobileNet V1’s 31 layers. Adding more layers to a model results in increased cache misses as each operation requires new tensors and filters to be brought into the cache. Because of this, performance corresponds less to computational time and more to memory buffer sizes. In spite of their depth, because MobileNet V2 models are relatively small, they still have better performance to accuracy ratios than the equivalent MobileNet V1 models.
To achieve better accuracy, MobileNet V2 applies width-multipliers to all layers except the last convolutional layer for resolution-multipliers less than one. Because of that, and because the total amount of memory needed for MobileNet V2 inference depends mainly on the size of the bottleneck tensors, models with a width-multiplier of 0.75 require the exact same size memory buffer as the same model with a width-multiplier of 1, which is why you see both versions clustered together in the graph.
Conclusion
Because of its shallow depth and small size, the performance of MobileNet V1 on the i.MXRT1170 is governed mainly by multiply-accumulate operations. MobileNet V2, and presumably other neural networks with many hidden layers, is dependent on the allocated memory buffer size for performance. Although model selection depends largely on use-case, I hope that my findings will help those who are trying to choose which model to use for image classification on i.MXRT1170 devices.
References