


I've been playing around with the eIQ tools on the Yocto image for MaaXBoard recently. Until now, I've mostly focused on Debian, but the eIQ layer for MaaXBoard Yocto was released earlier this year and it makes a number of machine learning tools available on the Yocto image.
What is eIQ? It's NXP's custom collection of Neural Network compilers, libraries, and hardware abstraction layers. The following five inference engines are supported by eIQ:
- ArmNN
- TensorFlow Lite
- ONNX Runtime
- PyTorch
- OpenCV
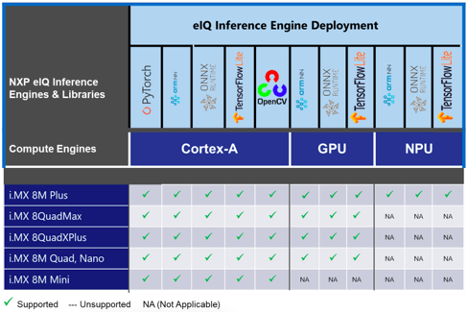
eIQ supports all of the i.MX processors based on Arm Cortex-A and Arm Cortex-M cores, as well as GPUs, DSPs, and NPUs when available. It's easy to build into your Yocto image for MaaXBoard, and I recently wrote the following tutorials so you can get started:
| Getting Started with Yocto on MaaXBoard | Building Your own Yocto for MaaXBoard | Running Machine Learning on MaaXBoard's Yocto Image |
|---|---|---|
|  |  |
NXP just released their most recent version of the eIQ tools, as well as a new imx machine learning User’s Guide in April 2011 (the old guide from May 2020 is here).
To get a sense of the eIQ machine learning tools, I decided to compare the speed of Tensorflow Lite on MaaXBoard running Yocto vs MaaXBoard running Debian.
The first thing I did was to run the original Python benchmark that I ran last year on Yocto. I was pleased to see that it was noticeably faster on Yocto than on Debian.
| Debian | Yocto | Raspberry Pi 3 | Raspberry Pi 4 (8GB) |
|---|---|---|---|
| 364.3 | 262.8 | 1108.5 | 178.9 |
Why is it faster? The answer is delegates.
Delegates.
What are delegates? Delegates do exactly what they say they do: they delegate different ops to different parts of the hardware. When you build Yocto with eIQ, you specify which NXP architecture you're building for, be it i.MX8M+ with an NPU, i.MX8M Mini with quad CPUs, or even i.MX RT, with Cortex-M7 and Cortex-M4 microcontrollers. Since it knows which hardware you're building for, it's able to automatically apply delegates when machine learning inference is run. For instance, if you have a lot of matrix multiplies and your hardware has a GPU, it will automatically know to send these ops to the GPU.
One of the great features of delegates in eIQ is that even if you don't have specialized hardware like a GPU or DPU, the delegate acts basically as an optimizing compiler. Also, it will still be applied on a per-op basis, even if not all of the operations are able to be delegated. The delegate gets a list of nodes that are going to be executed in sequence. It looks at input tensor shapes, as well as ops for each node.
The delegate then chooses which ops to delegate. For instance, maybe the delegate only supports add operations and not multiplies.
The runtime will partition the nodes into delegated vs. non-delegated ops. The delegate can fuse as many ops as possible to optimize inference speed. The one downside of fusing ops is that accuracy of the model may slightly suffer.
In the example below, I'm running the same label_image.py file on both Debian and Yocto, as well as Raspberry Pi running 64 bit raspbian OS. Yocto has a far longer warm-up time as it sets up the NNAPI delegate, but once it's set up it's 25% faster:
| Debian | Yocto | Raspberry Pi 4 (8GB) |
|---|---|---|
(tf) ebv@maaxboard:~$ python label_image.py Warm-up time: 210.4 ms
Inference time: 208.8 ms
0.874510: military uniform 0.031373: Windsor tie 0.015686: mortarboard 0.011765: bulletproof vest 0.007843: bow tie | root@maaxboard:/usr/bin/tensorflow-lite-2.1.0/examples# python3 label_image.py INFO: Created TensorFlow Lite delegate for NNAPI. Applied NNAPI delegate. Warm-up time: 6157.1 ms
Inference time: 127.1 ms
0.670588: military uniform 0.125490: Windsor tie 0.039216: bow tie 0.027451: mortarboard 0.019608: bulletproof vest |
pi@raspberrypi:~ $ python3 label_image.py Warm-up time: 101.4 ms
Inference time: 96.0 ms
0.658824: military uniform 0.149020: Windsor tie 0.039216: bow tie 0.027451: mortarboard 0.019608: bulletproof vest |
(Raspberry Pi 4 outperforms both of them in spite of not making use of delegates, because it has quad Cortex-A72s, which have faster performance due to 3-way superscalar out-of-order execution vs. 2-way superscalar OoO on the Cortex-A53s).
Since most image recognition use cases in the real world run on streaming images or video, the warmup time quickly amortizes, and the NNAPI delegate provides significant improvements.
But why does it delegate only on Yocto and not on MaaXBoard Debian or Raspberry Pi? The Tensorflow Lite Python API that is built into eIQ is set up to automatically delegate to NNAPI. Without eIQ, you would have to manually build the Arm NN Delegate as a library (or other delegate library) and then explicitly call the delegate from within your Python application by providing code like the following:
# Load TFLite model and allocate tensors
armnn_delegate = tflite.load_delegate(library="/usr/lib/libarmnnDelegate.so", options={"backends": "VsiNpu, CpuAcc, CpuRef", "logging-severity": "info"})
# Delegates/Executes all operations supported by ArmNN to/with ArmNN
interpreter = tflite.Interpreter(model_path="mobilenet_v1_1.0_224_quant.tflite", experimental_delegates=[armnn_delegate])
This presentation has more information about what's involved with using delegates in the Python Tensorflow API if you don't have eIQ. If you do have eIQ though, good news! eIQ actually includes several delegates, so it's possible to compare them. Below is a block diagram of the delegates that are available to Tensorflow Lite and how they fit together:
In my next blog, I'll cover the XNNPack delegate and how it compares to NNAPI, as well as benchmarking the C++ Tensorflow Lite API on MaaXBoard Yocto vs Debian.