


Note: This is part 1 of a 2-part series on an experimental user interface
Part 1: - You are here! <---
Part 2: - Not yet written! Bookmark to be notified here when it is available
Note: The technique described here is experimental and should be restricted to the sole purpose of UI implementation, and the browser files should be local. Security considerations beyond the scope of this blog post would need to be taken into account if the pages accessed by this technique were remote and accessed via a network.
Introduction
This blog post is about a user interface based on web technologies including HTML.
It enables the use of typical hardware (such as buttons, LED displays, TFT LCD displays and so on) for the user interface, but with all software control (including display information, text, graphics, styles and user interface response behaviour) implemented in HTML and any other desired web technologies such as JavaScript.
The aim is that the same code can be used to build very different looking user interfaces. Furthermore the same code could also be used to provide remote management from a browser. The views can be displayed differently to suit the hardware. With a large screen TFT LCD the user’s experience will be different to a (say) 16-character single-line display, but both should be possible with the same code.
An Example – Home Lighting Controller
Just as an example, a low-cost home lighting controller with constrained user interface hardware may have just push-buttons to switch on/off lights in different rooms of the house, and LEDs (one LED per room) to indicate which rooms are switched on.
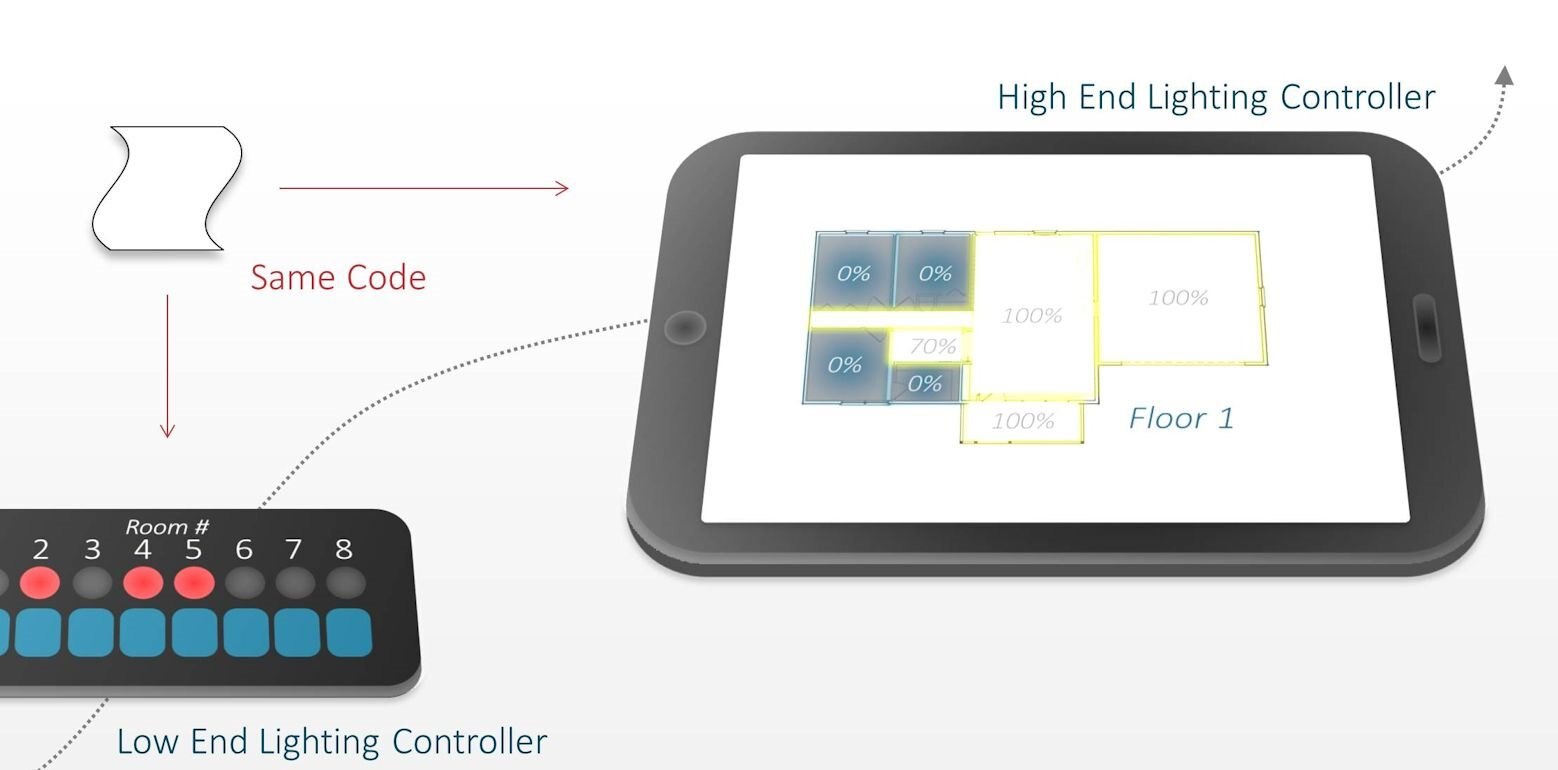
A more advanced (and expensive) home lighting controller with a TFT LCD and touch-screen may display a plan view of the home with rich graphics, a slider to select the floor of the home, and allow users to touch the desired room and show in a colored graphical image if lights are switched on or off.
If network connectivity exists then a web browser-based interface for the lighting controller may implement security including a password, and have a mode with simpler graphics and text so that it can be used from a smart phone.
The desire is to allow all of these methods of control to be possible (in a single way) for a scalable experience to suit the hardware that exists. It basically extends the usual web browser techniques to work with diverse input/output devices.
Why do this with HTML?
HTML is great for providing information; scripts or programs (along with HTTP) provide the interactivity. In the times when graphics were not always possible simple text-only browsers like Lynx existed to provide access to HTML content. The HTML file was rendered in text-only, and any graphics were ignored. The precedent therefore already exists for HTML on constrained displays (there are also plenty of Internet of Things projects today that extract HTML content and send it to an LCD character display on wireless nodes but they often use functions such as string extraction for extremely basic HTML parsing with no scalable experience and the interaction is basic).
HTML and associated technologies such as CSS and JavaScript are attractive because they are fundamental to all web pages and therefore there is a possibility that programmers will have encountered them to some degree. No need to learn Python and other languages or technologies if you don’t want to. It also means that debugging can be simple; just run the code in a browser! There is no need to have access to the physical hardware until you are ready for it. In a team, it simplifies allowing some people to work on physical hardware while others work on low-level interfacing in software and others can work on the user interface logic and application logic.
And to be honest another reason to do this was partly curiosity: how feasible is it to build an interface using HTML and associated web technologies for a device with constrained input/output for the user interface, and could it be responsive?
Design Overview
The heart of the design involves the need to be able to interpret HTML and JavaScript and any additional libraries. A web browser engine is used to perform these tasks. This allows the user interface programmer to create HTML based content just like any other web project. The difference is that input and output from the web browser engine is not necessarily targeted for a graphical desktop and keyboard/mouse. Instead, for display output, HTML elements and JavaScript variables can read from the page at any time to directly control any desired output device. For user input, push-buttons or any other sensor data can be pushed into the browser engine at any time. To create such a design involves constructing a usable workflow for these output and input tasks respectively. The workflows that have been prototyped are not necessarily the best ways but they function; there is plenty of scope for improvement. I only had limited time to think up a prototype.
The diagram below shows how the prototype works. All user interface related content is contained on the right side of the diagram in HTML files. This includes all text strings, images, color schemes, layout, button press rules and desired output events.
All hardware interfacing and all other functions that the system needs to support is contained on the left side of the diagram. Any programming language(s) could be used, and in this example JavaScript was chosen, executing on a software platform called Node.js.
The remainder of this blog post will refer to the right side and the left side of this diagram frequently.
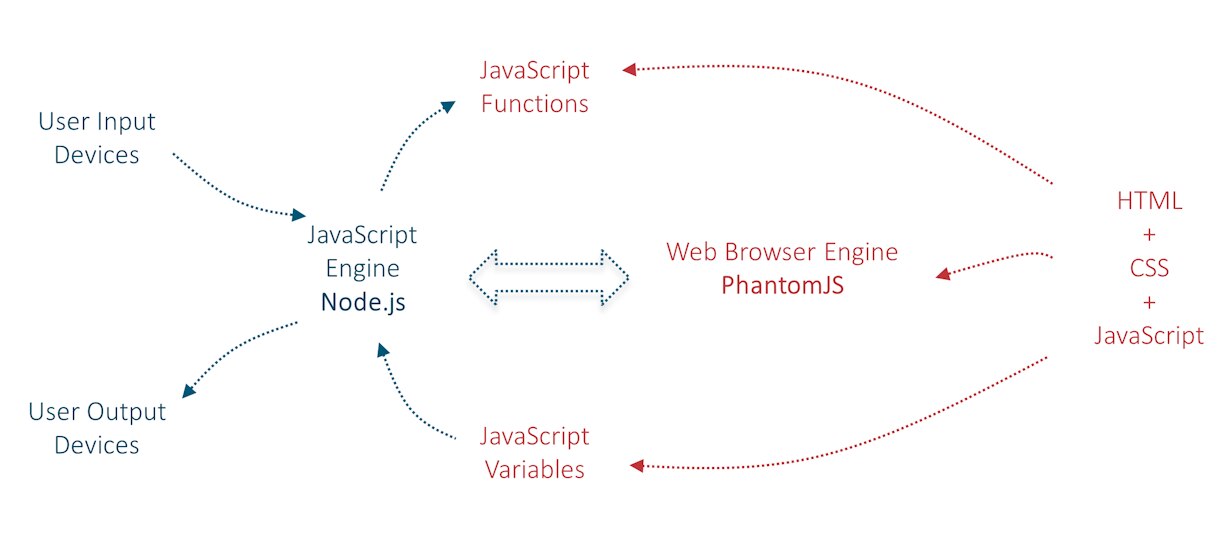
Note that although the right side of the diagram shows JavaScript, this is unrelated to the main program running on the left side which also happens to use JavaScript in this prototype. The JavaScript on the right side is exclusively intended for user interface related activities and it runs on the separate web browser engine called PhantomJS. The left and right sides will operate like ‘ships that pass in the night’ with the bare minimal interaction.
The two sides of the diagram interact with each other through the ability to remotely influence and read activity that occurs on the right side, through an application programming interface (API) available to Node.js that allows events or variables or other content to be pushed to PhantomJS by instructing it to execute any function written in JavaScript on the right side. In a similar vein it is possible for the left side to peek inside PhantomJS and read any JavaScript variables at any time.
For an example application, a simple procedure was devised for the left and right sides to communicate through this remote function execution and variable peeking method, and it is discussed next. But first, a brief note about the software libraries and platforms used in this project: Node.JS is fast becoming a reasonably mature platform for projects, however the module that connects it to PhantomJS and PhantomJS itself are not designed for implementing user interfaces; they are designed for testing web pages so they are being used beyond their original scope. It is hoped that over time improvements can occur as these platforms continue to be developed.
A Worked Example: LED Toggling
It is easier to see how all this works by examining what needs to be done for a simple project consisting of two LEDs and a single button. The project was tested with a Raspberry Pi. The idea was that the button would be used to alternately turn on the LEDs.

The HTML File
The complete HTML file for the right side of the diagram is shown below (also available on GitHub). This single 45-line file contains the entire logic for the application!
The blue and red circled items are the API which we will define between the left side and the right side.
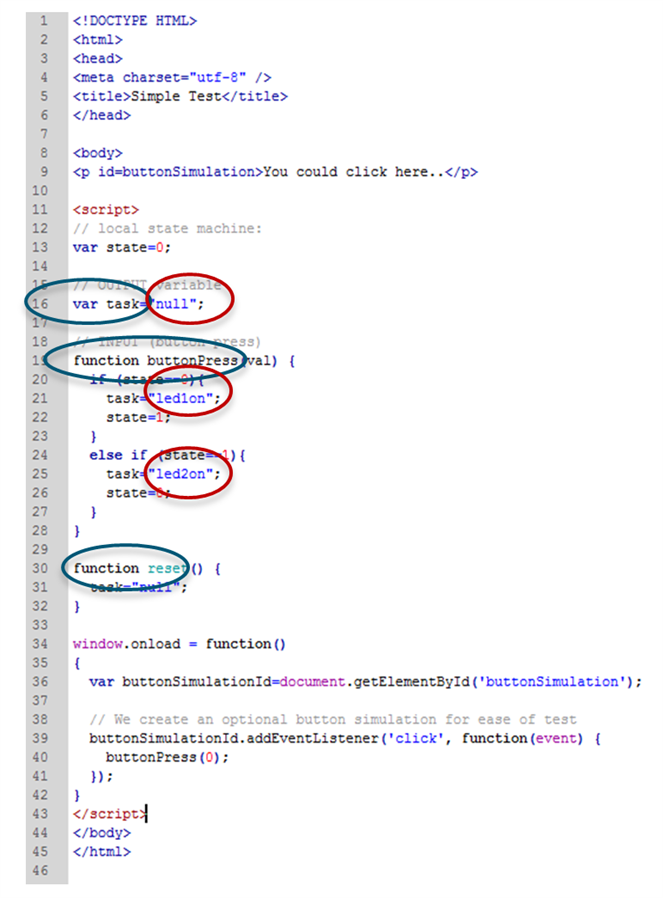
We can define the API as follows:
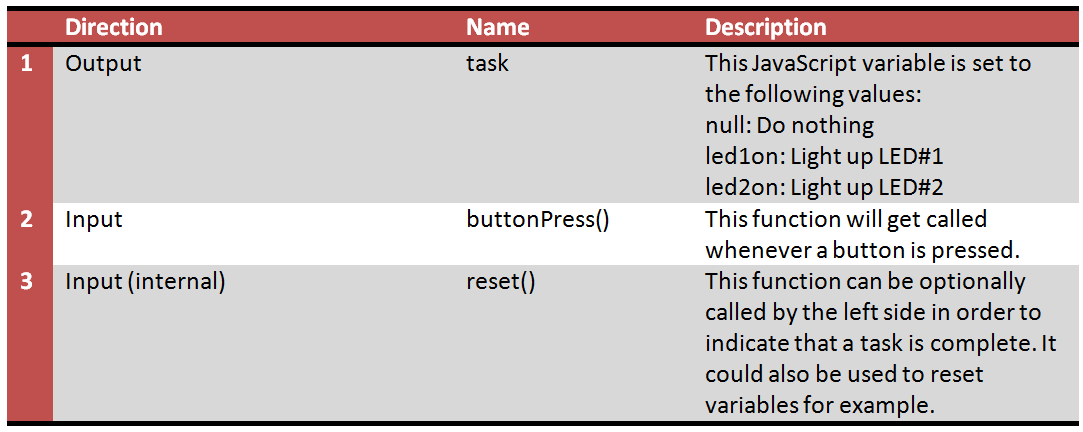
That’s it; the remainder of the HTML file contains a bit of test code that could be used to test the logic in a web browser using a debugger. No Raspberry Pi or any other hardware is required to test it.
The Node.js Side
The left side handles the invocation and interactivity with the right side and all interaction with hardware.
The code is attached to this post (it is very short, less than 100 lines), but the key snippets of it are described here.
The hardware interface is defined here, in terms of general purpose input/outputs (GPIO):
// Inputs var button1=17; // GPIO17 is pin 11 var button1timer=0; // Outputs var led1=27; // GPIO27 is pin 13 var led2=22; // GPIO22 is pin 15
For more information on Raspberry Pi GPIO, see the Raspberry Pi GPIO Explained guide
The variable button1timer is used for implementing a software debounce.
The next step is to enable the inputs and outputs:
pi.setup('gpio');
pi.pinMode(button1, pi.INPUT);
pi.pinMode(led1, pi.OUTPUT);
pi.pinMode(led2, pi.OUTPUT);
The right side is instantiated using the following code:
phantom.create(function(ph) {
console.log("bridge initiated");
ph.createPage(function(page){
page.open("file:///home/pi/development/uitest/index-simple.html", function (status) {
console.log("page opened");
});
});
});
The code above launches the HTML file described earlier into the web browser engine instance. The HTML file is now running in the browser engine.
The debounce is handled as follows: First, a function is registered to be called automatically whenever there is a falling edge on the button input (logic level 0 means the button is pressed, logic level 1 means the button is unpressed).
pi.wiringPiISR(button1, pi.INT_EDGE_FALLING, button1int);
Whenever a falling edge is seen, the button1int function is called:
function button1int(param)
{
if (button1timer==0){
button1timer=setTimeout(button1debounce, 20, param);
}
}
The code above registers a function called button1debounce to be executed in 20 milliseconds. This is a switch debounce period (see the Raspberry Pi GPIO Explained guide for an explanation on debouncing).
Here is the button1debounce function:
function button1debounce(_param)
{
if (pi.digitalRead(button1)!=0) {
// button press was too short so we abort
button1timer=0;
return;
}
_page.evaluate(function(param) {
buttonPress(param);
}, function(result) {console.log("buttonPress done"); }, param);
do_task();
button1timer=0;
}
Three key things can be observed to occur in the code above. Firstly as expected, the button gets debounced. Secondly examine the _page.evaluate section. This section is responsible for calling buttonPress() which is the function in the right side HTML file! This is an example of interaction between the left side and the right side. Finally a do_task() local function gets executed which will be responsible for finding out from the right side if there is any task to perform.
The major take-away from this section is that there is no application logic at all. All of that was contained in the HTML file!
The do_task function just dumbly does whatever the right side wants it to do. The _page.evaluate function is now used to query the task variable from the right side, and uses it to light up the appropriate LED, and then the right side reset() function is used to let the right side know that the task is complete.
function do_task()
{
_page.evaluate(function () { return task; }, function (taskname) {
if (taskname=="null"){
// do nothing
}
else {
if (taskname=="led1on")
{
pi.digitalWrite(led1, 1);
pi.digitalWrite(led2, 0);
_page.evaluate(function() { reset(); }, function(evresult) {} );
}
else if (taskname=="led2on")
{
pi.digitalWrite(led1, 0);
pi.digitalWrite(led2, 1);
_page.evaluate(function() { reset(); }, function(evresult) {} );
}
}
});
}
Setting up the Raspberry Pi
A folder is needed for development. One way is to create a main folder for all development work, and create a sub-folder called uitest for this user interface test. From the home folder (/home/pi in my case) it is possible to type the following:
mkdir –p development/uitest
In order to run the code, install Node.js on the Raspberry Pi using the following commands:
wget http://node-arm.herokuapp.com/node_latest_armhf.deb sudo dpkg -i node_latest_armhf.deb
Next, in the development/uitest folder, obtain phantomjs:
git clone https://github.com/piksel/phantomjs-raspberrypi.git cd phantomjs-raspberrypi/bin sudo cp phantomjs /usr/bin sudo chmod -x /usr/bin/phantomjs sudo chmod 755 /usr/bin/phantomjs
Now some Node.js modules need installing:
npm install wiring-pi npm install phantom
Transfer the index-simple.js and index-simple.html files into the development/uitest folder and then mark the .js file as an executable:
chmod 755 index-simple.js
Now the code can be run as follows:
sudo ./index-simple.js
Here is a short (1 minute) video of the functioning project. It can be seen that, with the limited functionality of this project, the interface is very responsive. The responsiveness with more advanced projects is for further study.
Summary and Next Steps
It is possible to code the entire user interface logic (and application logic if desired) in a HTML file (known as the ‘right side’ with reference to the earlier diagram) using everyday HTML and JavaScript. This is powerful because it means that tasks can be nicely decoupled during project development. A simple API can be devised that will allow the HTML file to work with the hardware interfacing code and a simple example was shown that allowed LEDs to be alternately controlled using a push-button.
The left side was responsible for low-level functions such as hardware control and button debouncing and for establishing communication with the right side which did everything else.
As next steps, it would be interesting to exercise the right side web browser engine more deeply in order to create a richer user interface that would be driven by more advanced hardware such as a graphic display, by the left side.
The full source code is available on GitHub.
Stay tuned for Part 2.
Top Comments