


In this blog post I'm going to detail the process that I'll be using to test the performance of the HVC-P2. In following posts I'll document the test results.
As I discussed in my previous post, key parameters that I am trying to evaluate are the accuracy and repeatability versus the acquisition distance from the detected object. It would have been nice to have the ability to load images into the HVC-P2 so that the image processor/algorithm could be evaluated independently from the camera but that feature is not available. At the end of the day, it is the "live" performance that matters, but I wanted to see how well the unit would perform without motion artifacts from live images (e.g. blurring or object movement between captured frames). So, for my initial testing I decided to use static images (no movement between image captures). I'm hoping that this will give me a upper bound as to the performance that I can expect from the unit.
When I first started playing with the unit I would use live detection with myself as the target and then I started using various pictures that I had around and the unit seemed reasonably happy detecting the images from photographs, CD covers, etc. I thought that I could refine that technique for testing with static images.
Here is the setup that I am currently using:
I mounted the unit on a tripod and positioned it 18 inches in front of a computer monitor. I grabbed a bunch of people images from the pexels website https://www.pexels.com/ . Pexels offers free stock photos that can be used and modified without attribution required. I then scaled the pictures using Powerpoint and can sequence through them in a slide show. My idea is to use the scaled pictures as a proxy for distance. And hopefully since I am using the same image I can get an accurate determination of distance performance. I have some concern that the detection algorithms may be sensitive to scaling artifacts (background variation) but I should be able to get a sense of that from the data (consistency of the detection bounding box).


Here are two examples of the data from the setup:
These examples have all the detection modes and stabilization enabled. And the image is registered in the face recognition database as "HappyGuy".
Large image

Large image detection data

Smaller image
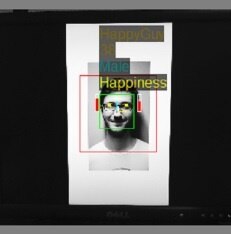
Smaller image detection data
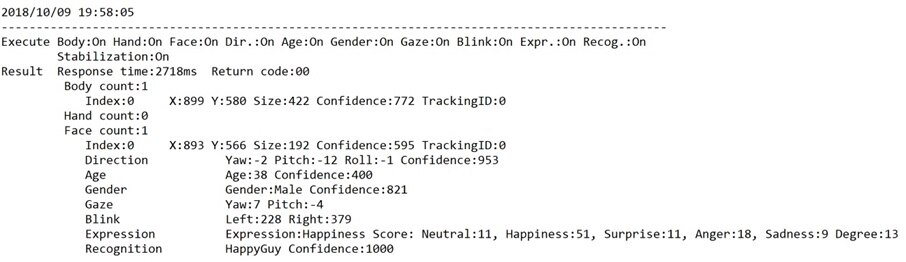
You can see from the data that a single body and face were detected in both cases and the detected body size went from 688 to 422 pixels and the face size went from 342 to 192 pixels.
The facial recognition correctly identified the image with 100% certainty.
Size to Distance "Calibration"
At this point I need to relate the detected image size to a corresponding distance. I'm going to apologize in advance because I am somewhat schizophrenic relative to measurement units and will flip-flop between English and metric units. I did this measurement in feet because that's what is on my measuring tape. I'll convert to metric for my test data.
I got my wife to pose for me at varying distances and recorded the sizes of detection bounding boxes. It is somewhat intuitive that size will scale as the inverse of distance but it is good to confirm that and also to get a nominal scaling factor for the lens magnification.
Distance feet | Body Size | Face Size |
| 3 | 870 | 348 |
| 5 | 384 | 152 |
| 10 | 192 | 84 |
| 15 | 120 | 48 |
| 20 | 104 | 42 |
| 25 | 86 | 34 |
| 30 | 69 | 28 |
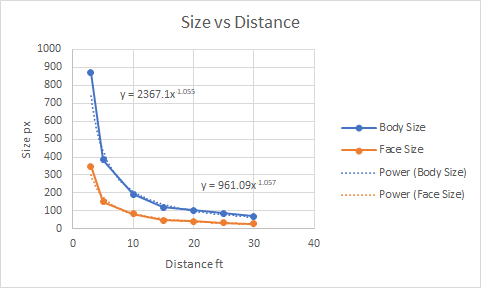
There is a reasonable curve fit of the inverse curve to the data. I should be able to extrapolate for other distances. I realize that the scaling factor will be different person to person as will the body/face size ratio, but I think that I can use the face size as a proxy for distance with reasonable accuracy.
Data collection
I am going to create a scaled set of images with different detection attributes (gender, age, expression). I doubt that I have enough time to run all of the possible combinations so I'll let what I see in the data be my guide. Initially I'll just use a couple of images and run through the whole matrix of data points (I'll document that in the test data). I'll start with doing 100 detections per data point and reduce that if there is good repeatability. I am not going to test hand, gaze, and blink detection since I'm not interested in those modes and finding appropriate test images would be difficult..