


With this part of my roadtest of the PolarFire FPGA I implement an example accelerator design for sorting on it, and I compare it with results from a Xilinx board (Avnet's Ultra96). I always considered such a comparison very interesting and useful, and this is the perfect time to be done.
For this comparison, I will mostly focus on resource utilisation for the logic in terms of look-up tables (LUTs) and flip-flops (FFs), as well as the operating frequency (fmax). The resource utilisation relates to complexity of the designs that can be placed on the FPGA, and the operating frequency can directly translate to performance.
The reason that this comparison is really interesting is that these metrics are a result of numerous factors, from the internal architecture of the FPGA (e.g. Zynq UltraScale+ for the ZU3EG on Ultra96) to the quality of the toolchain (e.g. the effectiveness of logic optimisation, place-and-route heuristics etc.).
Thus, this comparison will be able to roughly answer simple questions like what chip do I select for a better chance to fit my complex design. The comparison is based on the sorting example, and it does not elaborate on designs with memories (e.g. BRAM) etc. that would further complicate the discussion.
Comparison of the two FPGAs on paper
Based on official information from the corresponding vendor's websites I have created the following table summarising the selected specification details for each of the boards.
| Board | Microchip PolarFire Eval Kit (MPF300-EVAL-KIT) | Avnet Ultra96 |
| FPGA part | MPF300TS-1FCG1152I | XCZU3EG-1SBVA484E |
| LUTs | 299,544 (LUT4) | 70,560 (LUT6) |
| FFs | 299,544 | 141,120 |
| Logic elements | 299,544 (LUT4+DFF) | 154,350 |
| Total on-chip memory | 20.6 Mbits | 7.6 Mbits |
| Total DRAM | 6 GB | 2 GB |
| Hardened cores | None | 4x ARM A53 @ 1.3 GHz |
| FPGA manufacturing node | 28nm Silicon-Oxide-Nitride-Oxide-Silicon (SONOS) | TSMC's 16 nm FinFET |
| Included software license | 1-year "silver" Libero SoC | Vivado free version (perpetual) |
| Other features | 2x RJ45, SFP+, SERDES, 160-pin (HPC) FMC, PCIe x4, SATA | Runs Linux, 2x ARM R5 for real-time use, Wi-Fi and Bluetooth, USB ports, 100-pin GPIO, SD card slot |
| Current price | £1,353.00 | £267.68 |
The MPF300T is a more expensive board, as it is certainly more high-end feature packed. However, with respect to the FPGA itself a comparison is less straightforward as they are fundamentally different, from the architecture of the logic slices to the fabrication technology (MPF300 is non-volatile).
For example, the number of lookup tables (LUTs) in each case counts different LUT implementations (4-input LUTs on Microchip and 6-input LUTs on Xilinx). In principle, 4-input LUTs are older and inferior to 6-input LUTs, as they contain less information (16 and 64 rows respectively). However, an FPGA consisting of different LUT implementation is not necessarily inferior or superior, as each approach has different advantages, such as with respect to the routing complexity. Nevertheless, we would like to see if the higher number of LUTs in MPF300T is still better, i.e. it fits more logic.
Here is a picture of both boards side by side:

I would say the selection of Avnet's Ultra96 for this comparison is appropriate because it is commonly referred to as one of the most cost effective solutions with respect to the capabilities of the FPGA. This was the case at least when it was introduced. Maybe Kria KV260 is a also a good candidate now, but Xilinx likes to obfuscate the FPGA chip information lately (more Googling time required..). With respect to cost effectiveness though, since the relationship between the specification and price is generally non-linear (i.e. slightly larger FPGAs tend to cost way more), at a first glance given its capabilities, the price of the PolarFire FPGA seems competitive.
I am personally more experienced with such Xilinx FPGA boards, so Ultra96 made a "safe" baseline for my observations on MPF300T. Other features like the interfacing technologies is outside of the scope of this comparison.
Introduction on the example application (bitonic sorter)
Sorting is a common big data operator, and is a good candidate for acceleration. The bitonic sorter is a popular parallel algorithm for sorting P numbers in O(log^2(P)) parallel steps. The bitonic sorter was invented in the 60s, but became very common on FPGAs (usually as a building block to more complex designs) due to the high amount of parallelism.
As shown in the figure below, a bitonic sorter of 8 inputs is a pipeline that has 6 stages. This means that as soon as 8 numbers are let in its input, in 6 FPGA cycles we get a full sorted list. On every pipeline stage there are 4 compare-and-swap (CAS) units, which are essentially sorters of 2 elements, such as by applying a min and max operation on two input numbers. Here we assume that there are registers after pipeline stage, though more optimisations for FPGA exists, like with retiming.
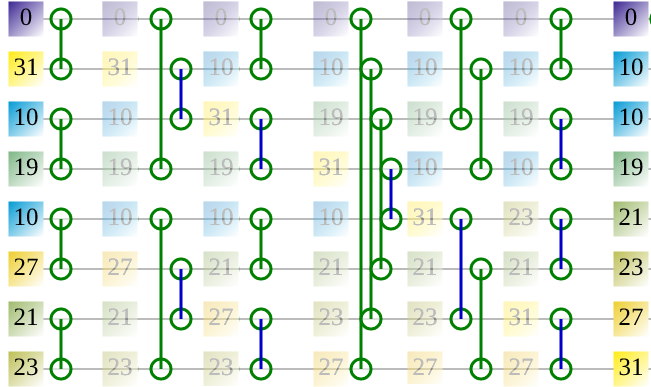
Click here to see the complete animation on my website, which I used in one of my past presentations.
Here, the implemented sorter is used out-of-context, as it is not connected to any large memory pool, but I consider it a good candidate for investigating the logic aspects of the two FPGAs. The pipelined approach is fairly representative, especially for large designs and maybe processor and dataflow accelerators. The connections between each pipeline stage is also representative for the effectiveness of routing, as it is similar to the more popular butterfly networks etc. The amount of logic between the pipeline stages is kept constant (up to one CAS unit), but the "wire" length and their placement varies, which stresses place and route, especially for bigger sorters.
Interfacing with the design
The way I decided to interface with the two designs is fundamentally different, as the two boards are very different in this aspect. With more effort, it could be possible to have a more similar interfacing method, but it is not necessary. However, this should not impact the comparison, as the communication logic is minimal and almost constant between different designs. We will vary the sorter size to see how the resources scale on the two FPGAs.
For the purposes of this comparison, interfacing is important because it is used to validate that the designs actually work on the FPGA. The nature and quality of the communication is not optimised here, but for production systems it would be important too. For example, the sorter would need to interface with the DRAM directly rather than the on-chip memory for assisting the sorting of bigger data. (Here, the data are loaded and read back serially, which defyies the purpose of the parallel sorter, but the parallel logic exists and works as expected for comparison).
On Ultra96, the sorter is implemented as an AXI peripheral. AXI (Advanced eXtensible Interface) is an ARM-specific protocol, and here is used to communicate with the sorter through memory. The programmable logic includes an AXI interconnect, which memory-maps the sorter into a specific memory location. Then, when the bitstream is generated, it is loaded dynamically through the FPGA Manager facility in Linux that runs on the hardened cores of Ultra96. The way I access Linux on Ultra96 is through its WiFi, as it is programmed to work as a WiFi hotspot by default. Finally, a simple Linux tool called "devmem" is used to provide read and write instructions to the memory-mapped locations corresponding to the sorter.
Below you can see the "block diagram" that is used in Vivado for this Ultra96 design. The rightmost component contains the Verilog code for the sorter. I prepare multiple variations of this project to test different sizes of sorters, and this is the exact file where all these Vivado projects differ.

On MPF300-EVAL-KIT, the sorter is also encapsulated in a block like Vivado and interfaces with vendor-provided IPs. In this case, I communicate with the sorter through the USB interface of the board. The USB interface includes UART alongside the Flashpro5 programmer. My Libero project is based on the "PolarFire FPGA DSP FIR Filter" demo. The reason I used it as a base project is that it contained a working instance of the PF_COREUART IP block, which eases communication through the USB port. (I deleted all FIR-related code and reused the Verilog placeholder for only doing sorting)
As you can see from the Libero's block diagram below, the Verilog code for the sorter is encapsulated in the grey block in the middle, but has a slightly more complex clock arrangement (at least with respect to the visual representation, as it uses a separate PLL IP (PF_ccc)). This time, the sorter is not memory-mapped, but it accepts similar instructions to devmem for writing and reading numbers in different locations.

In both boards, the commands to verify the sorter (either through "devmem" on Linux (Ultra96), or UART through "screen" on host's Linux (PolarFire)) can be summarised by the following pseudocode example (4-input sorter):
> Write 2376 at location 0
> Write 7843 at location 1
> Write 2230 at location 2
> Write 129 at location 3
> Write "start" at location 4
> (wait a few cycles)
> Read location 0
129
> Read location 1
2230
> Read location 2
2376
> Read location 3
7843
Some more thoughts on Libero vs Vivado
At least with this license configuration, a disadvantage of Microsemi/Microchip is that it only allows 1 or 2 instances of Libero (and Simplify for synthesis) working at a time. Otherwise, Libero doesn't start by showing a generic "license not available" complaint. This can be inconvenient when doing some form of a design exploration that requires multiple runs of the toolchain (like here). At the same time, another disadvantage is that the execution of most Libero tasks seemed to be mostly single-threaded, which adds to the inconvenience of not allowing multiple projects running simultaneously.
In contrast, Vivado seems to allow multiple runs, and the multi-threaded aspect, although not perfect, it has certainly improved during the last few years. Where Vivado seemed to fall short in comparison to Libero is the memory usage, as it easily scales to multiples of tens of Gigabytes for small designs. This disadvantage of Vivado partly relates to the "better" support for multi-threading, which comes at a cost.
I still think the same for all vendors, that paid software licenses are a bit anachronistic. From a personal experience through my university, although the university had license servers for enabling development on our advanced Xilinx boards, I always went for the boards that were supported by the free Vivado version (Alveo, some Zynq, ZynqMP (like Ultra96)). In this way, I was able to continue research on my personal computer in the weekends etc., without relying on slow VPN connections etc., and ran on VMs etc. for flexibility and using the latest and same Vivado version.
One peculiarity of Libero is that it does not warn you immediately when the design cannot run using the specified operating frequency. You have to find this out by using a separate tool called SmartTime after the bitstream is generated. This observation may very well be my misunderstanding on specifying and using Libero's timing constraint capabilities, but it would still be a valid point to prefer a more all-in-one tool for the different phases of the design flow.
See below how the user (me) is "greeted" with the results for this comparison using Libero and Vivado. Of course this relates to my usage and there are other ways of reading this sort of information.

Note that the frequency is also not apples to apples comparison, as it is a bit more theoretical. By requesting 500 MHz on both it does not mean that UART for example can run at this frequency, but it can enforce better optimisation for comparing maximal frequency. For the validation on the actual PolarFire, a clone project with 200 MHz is used. For Ultra96, the bitstreams are the same, as the clock frequency is reduced on demand using "devmem" at the appropriate memory-mapped registers via Linux. This approach may not be considered completely mainstream.
Results
First, we will see the lookup-table utilisation for sorters of different sizes (from 4 32-bit integers to 128 32-bit integers). As expected, there are differences because the 6-input LUTs of Ultra96 can contain more information than the 4-input LUTs of MPF300. The same logic requires more LUTs on PolarFire, but it is still bigger overall.

On the rightmost y-axis per plot there is also the percentage of the available LUTs for the corresponding die. Out of all shown points, only the 128-input sorter for ZU3EG has not passed beyond the synthesis stage, and this is because it did not fit on the chip (>100% utilisation). At the same time the 128-input sorter fitted just fine on PolarFire, at a utilisation around 60%.
Using the same approach we plot the flip-flop registers (FFs) utilisation, in thousands as well. Notice how the FF utilisation is much more similar than before, and this is because registers are just registers, and have less differences in their notion. This time, the PolarFire is more notably larger in this aspect.

Finally, we compare their achieved maximal operating frequency. The newer architecture/node of ZU3EG on Ultra96 seems to have some advantage, though the PolarFire also includes the larger 128-input sorter that managed to fit in the larger die overall.

Conclusion
As a conclusion, the PolarFire evaluation kit is still a superior board with respect to pure logic capabilities and some features than the cheaper Ultra96. Though, when considering the price and other features it is more useful to look at the problem specification first. For example, the Xilinx one seems to have some advantage on the operating frequency. The logic elements are different, so such comparisons are very useful to understand how different FPGAs compete with each other. PolarFire does surprisingly well with the simpler LUT4 lookup tables. A ratio of about 1.8x (based on the 64-input design) could be a rough metric to compare the LUT number of FPGAs between the two vendors, at least for these specific FPGA families and similarly pipelined logic etc.
A concern is that I find the license restrictions in all FPGA vendors to hinder productivity. Since the code is already closed-source, maybe vendors would benefit easier from profiting from the hardware alone, which is in both cases rather impressive.
Any comment is welcomed.



