RoadTest: Intel Neural Compute Stick 2
Author: vishwanathan
Creation date:
Evaluation Type: Development Boards & Tools
Did you receive all parts the manufacturer stated would be included in the package?: True
What other parts do you consider comparable to this product?: 1. Google Coral Link: https://coral.ai/products/accelerator 2. NVIDIA Jetson Nano Link: https://developer.nvidia.com/embedded/jetson-nano-developer-kit
What were the biggest problems encountered?: As the product requries pre-trained models IR format, converting a custom pre-trained model not currently supported by openVINO was the biggest challenge. It requires indepth knowledge of the pre-trained model which often is not the case unless once has trained the model from scratch by themself.
Detailed Review:
The basics of working with Intel ® Neural compute Stick 2 (NCS2), getting started and a sample demo is very well explained in the AI at the Edge: AI Prototyping on the Edge with the Intel ® Neural Compute Stick 2 document. The Benchmarking Edge Computing article is yet another excellent article for detailed comparison for other products comparable to NCS2.
Let's dive in to build the first chess engine accelerated by NCS2.
For this review we will use the open-source project called CrazyAra. It is a chess engine that is trained to play a Lichess variant of chess called Crazyhouse. There are various inference engines supported by the project. The project wiki is very well documented for all the details for developers and users. The openVINO inference engine has been integrated to it to test NCS2. This is done in three steps as explained below:
Model Optimizer is a cross-platform command-line tool that facilitates the transition between the training and deployment environment, performs static model analysis, and adjusts deep learning models for optimal execution on end-point target devices. Thus is used to convert the custom model to Intermediate Representation (IR) format via the DL workbench.
The details of the model architecture used from the CrazyAra project is as follows:

DL Workbench is a web-based graphical environment that enables you to visualize, fine-tune, and compare performance of deep learning models on various Intel® architecture configurations, such as CPU, Intel® Processor Graphics (GPU), Intel® Movidius™ Neural Compute Stick 2 (NCS 2), and Intel® Vision Accelerator Design with Intel® Movidius™ VPUs''. I used docker method to setup up DL workbench.
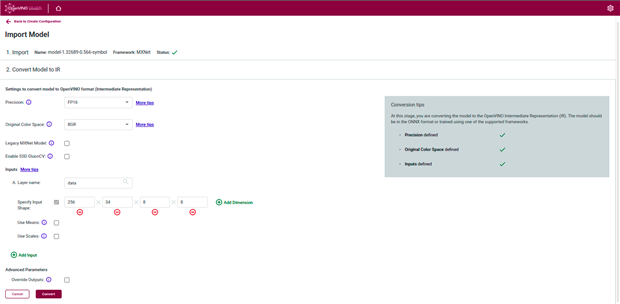
The following picture gallery will walk us through the steps to convert a custom model to IR format. Refer the image text along with the image for more details.
{gallery} OpenVINO DL workbench |
|---|
$ sudo ./start_workbench.sh -ENABLE_MYRIAD |
OpenVINO DL Workbench landing page |
Importing the model |
Add the input layer name, shape and color space details |
Creating configuration to convert model to IR format. |
Converted Model Summary |
IR model and Runtime Graph Visualization |
Execution time by layer Summary |
Model performance summary |
Packing model for deployment |
Converted models are available in the forked github repository.
Testing the engine from command line:


Running a Chess engine inference on NCS2
Cutechess is the UI which can run standard UCI chess engines and is used to debug the engines. Here is the demo video of replay of a game played against the engine.












Top Comments
I am curious, what types of applications would you use the device for?
How much time is needed to build up a custom model and use it?
How does the speed of this device compare to a similar implementation…