


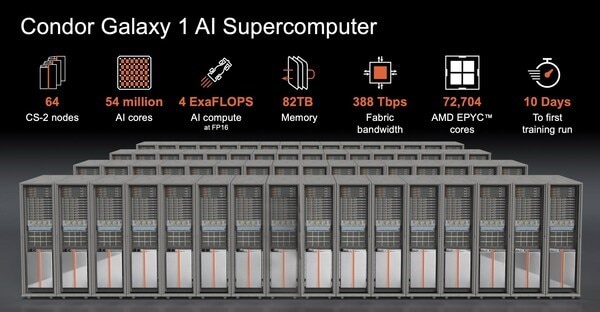
The CG-1 supercomputer has a computational power of 4 exaFLOPS at FP-16. It also features 54 million cores across 64 CS-2 nodes, supported by over 72 thousand AMD EPYC cores. (Image Credit: Rebecca Lewington/ Cerebras Systems)
G42 and Cerebras introduced the Condor Galaxy-1 (CG-1), the fastest supercomputer. It features nine interconnected supercomputers that could drastically decrease AI model training time, 54 million AI cores, and achieves four exaFLOPS of AI computing at FP-16. Next year, Cerebras and G42 are expected to deploy another two supercomputers, CG-2 and CG-3, in the States. This supercomputing network will have a processing capacity of 36 exaFLOPS, revolutionizing AI advancements on a worldwide scale.
Tech companies also revealed plans to use huge amounts of GPU clusters as the brainpower behind their AI models. “Distributing a single model over thousands of tiny GPUs takes months of time from dozens of people with rare expertise,” said Andrew Feldman, CEO of Cerebras Systems. Rather than relying on a central supercomputer, the team is developing interconnected AI supercomputers that cut down on AI model training time. This method also means it only takes a few minutes to set up generative AI models, all of which can be completed by one person.
The Condor Galaxy System consists of a supercomputer, and the first one was recently introduced. Cerebras built 65 of its CS-2 AI processors for the CG-1 supercomputer. AMD’s EPYC processor cores power the system, containing 54 million AI cores, 82 TB storage, and 388 TBPS fabric bandwidth. This system also outperforms the fastest supercomputer by 4x, thanks to its 16-bit computation delivering 4 exaFLOPS of computational power.
In comparison, the Folding@Home network, a project that uses computational power from worldwide volunteers to run simulations, exceeded 1.5 exaFLOPS on March 25th, 2020. This was 10x more powerful than IBM’s Summit supercomputer with a 148.6 PetaFLOPS benchmark. The Folding@Home network project achieved such a feat by employing 4.63 million CPU cores and close to 430 thousand GPUs. It’s also important to remember that the CPU cores and GPUs aren’t always online, so that may affect performance based on hardware availability.
As of today, the Folding@Home network has a computational power of 29 TFLOPS (58 x86 TFLOPS). It’s also using the power of over 15,000 GPUs and 28,000 CPUs.
CG-1 trains 600 billion parameter models, and that can extend to 100 trillion parameter models. That’s pretty mind-boggling, especially because ChatGPT is trained with 1.7 trillion parameters. While G42 and Cerebras will deploy CG-2 and CG-3 in early 2024, they plan to offer the CG-1 supercomputer as a cloud service.
Additionally, CG-1 can work with 500,000 tokens and doesn’t require special software libraries. Anyone can program on that supercomputer without complex programming languages. That cuts down on the amount of time it takes to distribute workflow across GPUs. The system will be operated under US laws by Cerebras to keep adversary countries from accessing the computational power.
Have a story tip? Message me at: http://twitter.com/Cabe_Atwell