


Artificial Intelligence IV: AI Face Applications
Sponsored by &
& 
1. Introduction | 2. Objectives | 3. Face Algorithms | 4. Face Applications | 5. Accelerating with Vitis-AI | FPGA Group | Summer of FPGA | Xilinx Agenda | Related Components | Test Your Knowledge

Face applications are being used in devices and services all around us. From cameras that detect faces to focus on specific parts of the scene, to security systems that recognize faces to control access, there seems to be no end to the diversity of face applications being deployed. In this course, we will cover some of the most common algorithms used in face applications. We will then use these to construct two very simple face applications to illustrate how these algorithms can be used together. Finally, we will see how we can accelerate these face applications on Xilinx devices using Vitis-AI.
2. Objectives
Upon completion of this module, you will be able to:
 Describe the different types of algorithms for face detection, landmarks and features
Describe the different types of algorithms for face detection, landmarks and features
Explain the fundamentals of deep learning techniques
Define the simple face applications
Discuss how Xilinx Vitis-AI can be used to accelerate face applications
The most commonly used algorithms for face applications are detection, landmarks, and features. We will look at the following popular computer vision libraries for example implementations:
OpenCV: https://opencv.org/
DLIB: http://dlib.net/
Face Detection
The first step in a face application is usually the detection of the faces in the scene.

Figure 1: Detecting the face in a scene
Face detection consists of finding the regions of interest (ROI) in an image that contains faces. Each face is then cropped and resized for the next processing step. If we look at two popular computer vision libraries (OpenCV and DLIB), they each have different implementations for face detection, including both traditional and state-of-the-art methods. We will discuss both in more depth in the next section.
The traditional methods, which date from 20 years ago and are still in use today, are more compute-efficient. The state-of-the art methods, which offer much higher accuracy at the expense of high computational requirements, are almost all based on deep learning.
Traditional Methods
Traditional methods are implemented with what is today called "feature engineering." Feature engineering involves manually designing algorithms to find features in an image.
Haar Cascades

Figure 2: The Haar Cascades method (Source: United States Naval Academy)
In the Haar Cascades method, features are calculated using a generalized form of Haar wavelets, the simplest wavelet form.
These wavelets are applied at different scales and combinations to detect a face. The order in which these features are calculated (cascades) has also been manually optimized to reduce the overall computation requirements of the algorithm.

Figure 3: The Haar Cascades process flow
The main advantage of the Haar Cascades algorithm is its computational efficiency. It can run in real-time on most embedded platforms. The disadvantages are the notorious false positives, as well as the fact that it supports only frontal faces.
State-of-the-Art Methods – Deep Learning

Figure 4: Deep Learning general process
The state-of the-art methods for face detection are based on deep learning algorithms. Instead of being manually engineered, they are learned from extensive labelled data sets.
If we look at two popular libraries, we see that the newest face detection algorithms are based on Deep Learning:
OpenCV: Single-Shot Detector (SSD), with Resnet-10 backbone
DLIB: Max-margin object detector
In deep learning, there are two phases: training and inference. Although we will focus mainly on inference, or deployment of the model, we do need to consider training to understand which model architecture is being used and what data was used to train it.
Modern deep learning algorithms overcome the drawbacks of the traditional methods, as they feature:
Improved accuracy
Support for different face orientations (up, down, left, right, side-face, etc.)
Support for occlusion
Support for faces of various scales (very small to very large)
The main disadvantage of these algorithms is related to biases, mostly relating to the data set itself. As an example, data sets may not fully represent faces from around the world. Interestingly, however, face data sets created pre-pandemic perform surprisingly well with masks, since the data sets include many general examples of occlusion.
Training
Without going in depth into the details of training a deep neural network (DNN), let’s investigate the models and data sets used for two common libraries.
The OpenCV github repository provides details of the DNN model for face detection.
The documentation confirms the model architecture (SSD with Resnet-10 backbone), as well as the framework used to train the model (Caffe). However, the details of the data used for the training are not available. The instructions provided for obtaining a face detection dataset are as follows:
Find some datasets with face bounding boxes annotation.
For some reasons I can't provide links here, but you easily find them on your own.
The DLIB github repository provides details of the CNN model for face detection.
The creator of the DLIB toolkit, Davis King, documents the model used for the pre-trained face detection model in his paper, Max-Margin Object Detector (MMOD) CNN. He also documents the data used for the training and provides a link to the data:
I created the dataset by finding face images in many publicly available image datasets (excluding the FDDB dataset). In particular, there are images from ImageNet, AFLW, Pascal VOC, the VGG dataset, WIDER, and face scrub. See link here
For this reason alone, I would consider using the DLIB face detection, because it can be re-trained and even augmented with additional data specific to your application, if needed.
Inference
Once our DNN is trained, it is ready to be deployed to an embedded platform. This inference usually consists of three distinct tasks: pre-processing, DNN modeling, and post-processing.

Figure 5: Deep Learning inference tasks
The pre-processing task is very important, because an image presented to the DNN model at inference must match the same conditions as during training. Pre-processing typically comprises image resizing and pixel normalization.
A typical face detection network will create the following output:
bounding boxes: M x N x {xmin, ymin, xmax, ymax}
scores: M x N x {score0, score1}
The output consists of a 2D grid, usually 2-4 times smaller than the original image, containing coordinates for bounding boxes, accompanied with scores showing whether or not a face was detected. With the previous output example, the post-processing task would include the following operations:
Softmax
Thresholding
Non-Maximum Suppression (NMS)
The purpose of the Softmax operation is to convert the scores to a normalized probability distribution (where the sum of values equals 1.0). With the scores converted to a normalized confidence level, a threshold can then be applied to keep only the bounding boxes that have a certain confidence. This will produce a cluster of bounding boxes around each detected face.
The NMS operation looks at the intersect over union (IoU) metric, to determine which ROI is the most representative of the face.

Figure 6: NMS operation to determine bounding box for faces
The final result is a list of bounding boxes (with confidence level) for each face in the image. After the face detection algorithm, where we have defined a region of interest for each face, several other algorithms can be applied, such as face landmarks and face features.
Face Landmarks

Figure 7: Face landmarks (Source: Royal Institute of Technology, Stockholm)
The second algorithm that we will cover are face landmarks, which define geographical or physical points on a face. If we look at the DLIB library, we find an implementation based on the paper, DLIB: Face Landmarks by Vahid Kazemi & Josephine Sullivan, from the Royal Institute of Technology Computer Vision and Active Perception Lab in Sweden. In this paper, the authors defined a method to extract 192 landmark points for a face.
Using an ensemble of regression trees, the authors iteratively find landmark points for the jaw, mouth, nose, and eyes.

Figure 8: Iteratively determining face landmarks
The DLIB implementation provides a pre-trained implementation for the following 68 landmark points:

[48,68] mouth
[17,22] right eyebrow
[22,27] left eyebrow
[36,42] right eye
[42,48] left eye
[27,35] nose
[0,17] jaw
Figure 9: The 68 Face Landmark points (Image source: studytonight.com)
The algorithm is very compute efficient, with execution times of just a few milliseconds on embedded platforms.
Face Features
The third algorithm to explore is face features. Face features are a key component of face recognition, and provide dimensional reduction of the image, while preserving the distinguishing information. An image of a face with several thousands of pixels can be reduced to hundreds of features. As with face detection, there are traditional methods and state-of-the-art methods for face features.
Traditional Methods
The traditional methods that we find in the OpenCV library are:
Eigen Faces
Fisher Faces
Local Binary Pattern
Each method uses a unique technique to reduce an image of a face into specific face features. Eigen Faces uses Principal Component Analysis (PCA), while Fisher Faces makes use of Linear Discriminant Analysis (LDA). Local Binary Patterns (LBP) uses histograms.

Figure 10: Example Eigen Faces (Source: wikipedia)
The image of Eigen Faces helps to visualize the dimensional reduction that is occurring during face feature extraction.
State-of-the-Art Methods
The state-of-the-art methods for face features are based on Deep Learning techniques.
OpenCV: DNN (OpenFace)
DLIB: DNN
The following benchmark illustrates the performance of traditional methods versus state-of-the-art methods when applied to the Labeled Faces in the Wild dataset.
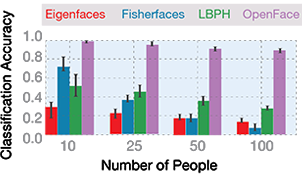
Figure 11: Classification accuracy of traditional vs state-of-the-art methods (Source: Univ. of Mass.)
For applications where only a few faces need to be distinguished from each other, the traditional methods perform almost as well as the deep learning based methods. As the number of faces to distinguish increases, however, the traditional methods start to break down and the deep learning techniques shine.
Training
The OpenCV implementation for face features is based on the 2015 paper, FaceNet: A Unified Embedding for Face Recognition and Clustering, by Florian Shroff, Dmitry Kalenichenko, and James Philbin of Google Inc.

Figure 12: Triplet Loss (Source: Google Inc.)
As with all deep learning techniques, there is a training phase and an inference phase. The training phase determines the features that are useful for the distinguishing of faces from different people. This is achieved with triplet loss, as illustrated in the image.
For each training iteration, three data items are used:
Anchor: a new face image for a certain identity (person)
Positive: a different face image of the same identity as the anchor
Negative: a face image for a different identity than the anchor
The triplet loss is a method that updates the face features to ensure that the Anchor is closer to all other Positives (same identity) than it is to any Negatives (different identities).
Inference
When deploying face features in a face application, the inference usually involves two additional steps:
Enrollment: creating a database of known faces
Inference: using the database of known faces for a specific task (i.e. face recognition)
This will be covered in more detail in the next section. There are many other algorithms that can be applied to faces, such as gender, age, or emotion detection; however, these are beyond the scope of this article.
Now that we have defined some of the basic algorithms used in face applications, we will define two very simple face applications.
Driver Monitoring
A driver monitoring application may be built with the face detection and face landmark algorithms as shown in the following diagram:

Figure 13: Driver Monitoring Process Flow
In this face application example, the face landmarks become the input for additional processing.
Head Pose Estimation

Figure 14: 2D Landmark points: nose, left/right eyes, left/right mouth, chin (Source: learnopencv.com)
The article, Head Pose Estimation using OpenCV and DLIB, by Satya Mallick of TAAZ Inc., describes how to determine head pose using the facial landmarks. The implementation requires the following landmark points for a given 2D image, taken from a real-time input: nose, left/right eyes, left/right mouth, and chin.

Figure 15: Default 3D model with Landmark Points (Source: learnopencv.com)
The algorithm requires the same points in 3-dimensional space. Since it is not feasible to provide a 3D model of every possible head, the points for a 3D head are provided.

Figure 16: Intrinsic parameters of camera
Finally, the intrinsic parameters of the camera are also required. Once again, the implementation provides a set of default intrinsic parameters.
The intrinsic parameters for a given camera allow us to mathematically calculate how points in the 3D space can be projected onto a 2D image. Similarly, we can use the same parameters to project the 2D facial landmarks into 3D space based on our generic 3D model. This allows us to determine in which direction the head is oriented.
Drowsiness Detection
In a similar fashion, facial landmarks can be used to determine more information from the eye regions in the face. In the 2016 paper, Real-Time Eye Blink Detection using Facial Landmarks, Tereza Soukupová and Jan Čech of the Center for Machine Perception at the Czech Technical University describe a method to detect blinking, using a metric called Eye Aspect Ratio (EAR), which is defined as follows:
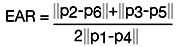

Figure 17: Drowsiness Detection using EAR (Source: Czech Technical University in Prague)
The EAR metric can detect when the eyes are closed, which is interpreted as a blink. If a blink occurs for a certain duration, this can be interpreted as drowsiness. Using thresholds, it is possible to create a drowsiness alarm:
Eyes closed: EAR < threshold
Sleeping: duration > threshold
Face Recognition
Face recognition can also be implemented with the algorithms we defined earlier:


Figure 18: Face Detection Process Flow

Figure 19: Aligning Face Landmarks
In this case, the face landmarks representing the eyes can be used to determine if the face is horizontally aligned. If the landmarks are not aligned horizontally, the image will be rotated. This is an important step to consider for this application, because past demonstrations have shown that facial recognition improves with aligned faces.
Once we have detected and aligned all of the faces in the image, we can calculate the face features for each. The basic face recognition pipeline is used twice in a typical face recognition application.
Enrollment: creating a database of known faces
Inference: using the database of known faces for a specific task, in this case, facial recognition
Enrollment
In the enrollment phase, we calculate the face features for our known faces and build a database containing these features, along with a meaningful label. In the following example, we have a simple database of four faces, corresponding to Kevin, Monica, Mario, and Frank.

Figure 20: Database of Known Faces
Inference
With our database of known faces defined, we are ready for inference or deployment.

Figure 21: Face Recognition Process Flow
During inference, we may be given images that contain any number of faces. The goal, for each face, is to search in our database for the closest match. A threshold is usually applied to differentiate between known and unknown faces.
In this last section, we provide an overview of the Xilinx Vitis-AI, and how it can be used to accelerate face applications.
Vitis-AI Overview
What is Vitis?
Vitis is a complete development environment that enables you to quickly create complex custom applications.

Figure 22: Vitis Development Environment (Source: Xilinx)
Vitis includes:
Vitis target platforms, which includes hardware platforms that span cloud and edge targets
Vitis core development kit, which includes drivers, compilers, and debugging tools
Vitis accelerated libraries covering a range of targeted applications
Support for domain-specific development environments, such as Caffe & TensorFlow for AI
Vitis includes open-source, performance optimized libraries that offer out-of-box acceleration. "A.I." is the library that makes use of the Deep-learning Processing Unit (DPU).

Figure 23: Vitis Libraries
What is Vitis-AI?
Vitis-AI encapsulates this AI portion of the Vitis offering. Vitis-AI supports several industry standard frameworks, including Caffe, TensorFlow, and PyTorch.
The Xilinx model zoo contains over 100 pre-optimized models targeting a variety of applications.


Figure 24: Breakdown of available Xilinx models
The Xilinx model zoo includes the following models specific to face applications:
| Face algorithm | Xilinx model zoo |
|---|---|
| face detection | retinaface densebox_640_360 densebox_320_320 |
| face landmarks | face_landmark |
| face features | facerec_resnet64 facerec_resnet20 |
| face quality | face-quality |
| face re-identification | facereid-large_pt facereid-small_pt |
Table 1: The Xilinx model zoo
Whole Application Acceleration
Xilinx’s Vitis framework enables the acceleration of the entire application, including pre-processing operations, which can be very compute intensive for higher image resolutions.

Figure 25: Native Processing vs Hardware Acceleration
As an example of Whole Application Acceleration, we will define a hardware design using the Zynq-UltraScale+ MPSoC device for edge applications. The Zynq-UltraScale+ MPSoC device contains two main components:
PS: processor system, including:
- APU: application processing unit (i.e. Quad ARM A53 processor)
- Memory: internal, DDR controller
- Peripherals, including DisplayPort, USB3, and others
PL: programmable logic, hardware available to implement interfaces/peripherals and accelerators
The PS includes standard processors on which we can run software, and the PL includes programmable logic on which we can implement custom interfaces and hardware accelerators.

Figure 26: Zynq-Ultrascale+ System Flowchart – PS
The PL allows us to create an application specific processor. As an example, we may want to implement a capture pipeline for a MIPI image sensor.

Figure 27: Zynq-Ultrascale+ System Flowchart – PL
At this point, we have defined the base hardware platform with our required interfaces. The next step is to create a Vitis platform, which will allow various hardware accelerators to be added to our platform. In order to accelerate deep neural networks, we use Xilinx’s AI engine, the Deep Processing Unit (DPU).

Figure 28: Zynq-Ultrascale+ System Flowchart – DPU
The DPU is a very scalable IP core that can be configured with various architectures, including B1152, B2304, B3136, B4096, and a maximum of four cores.
As described previously, deep neural networks also require pre-processing, which can be very compute intensive, especially for higher resolution images. OpenCV encapsulates these pre-processing functions in its “blobFromImage” API.
Figure 29: Zynq-Ultrascale+ System Flowchart – Pre-processing
Xilinx provides an accelerated version of “blobFromImage” in its Vitis vision library.
Vitis Video Analytics SDK (VVAS)
In order to leverage the hardware accelerators, Xilinx also provides a Vitis Video Analytics SDK, or VVAS. VVAS consists of GStreamer based plug-ins, allowing software developers to easily access the hardware accelerators in a familiar software framework.

Figure 30: Real-time 4K face detection in Kria SmartCam app
Figure 30 shows a simplified block diagram that illustrates how Xilinx achieves real-time 4K face detection in the Kria smartcam app.
The original 4K image is resized to the deep neural network’s input requirements using the PreProcess accelerator. The deep neural network is then executed on the DPU. The final results are drawn on the original 4K image and then sent to the output.
Accelerating Face Applications with Vitis-AI
The following sub-sections will provide links to projects that have implemented accelerated versions of the face applications that we have previously defined.
Accelerating the Driver Monitoring Application
Recall that our simple driver monitoring application included the following two features, head pose estimation and drowsiness detection. The following hackster.io project, Head-Pose Estimation on Ultra96-V2, provides the detailed description of how to accelerate the head-pose estimation with Vitis-AI. Figure 31 illustrates the accelerated implementation for the head-pose estimation.


Figure 31: Accelerated implementation for head-pose estimation
The face detection process is accelerated using densebox_640_360, while the face landmark process is accelerated with face_landmark, both models from the Xilinx model zoo.
The head pose detection process is not hardware accelerated, however, because 6 landmark points are required for this part of the calculation. The limitation of the face_landmark model for this application is that it only provides 5 landmark points: left/right eye, tip of nose, and left/right corners of the mouth. The required landmark for the chin is missing, and would need to be estimated.
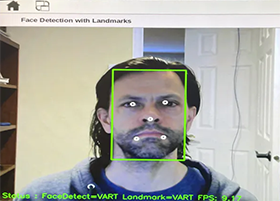

Figure 32: Face Landmarks comparison
The following two implementations were compared: using the accelerated landmark model and estimating the chin, and using the DLIB software library.
A naïve estimation of the chin landmark has been implemented as shown below.

Figure 33: Face Landmark with Chin Estimation
The offset of the nose from the center of the eyes is calculated, and the chin is estimated using this same offset from the center of the mouth. This chin estimation works fairly well when we have a front view of a face.


Figure 34: Face Landmarks comparison – Chin Estimation
The estimated chin landmark has limitations with certain head poses. When looking up, the head pose using the DLIB landmarks is more accurate than the estimated chin landmark.


Figure 35: Face Landmarks comparison – Head Raised
For side views of the head, the face_landmark model from the Xilinx model zoo performs better than the DLIB landmarks.


Figure 36: Face Landmarks comparison – Head Turned
The ideal solution would be to retrain the Xilinx model zoo’s face_landmark model with an additional landmark point representing the chin.
Accelerating Face Recognition Application
Real-Time Face Recognition on Ultra96-V2 provides a detailed description of how to accelerate face recognition with Vitis-AI.


Figure 37: Accelerated Face Recognition with Vitis-AI
Two applications are provided, which perform each of the deployment steps we described previously:
Enrollment: create database of known faces
Inference: recognizing real-time faces using database of known faces
The block diagram in Figure 37 illustrates the implementation of the accelerated face recognition application with Vitis-AI. The implementation is a multi-threaded application with 5 main threads:
Thread 1 implements accelerated face detection using densebox_640_360 from the Xilinx model zoo.
Thread 2 implements a software based tracking algorithm, allowing the system to be more robust to intermittent detections.
Thread 3 uses the face-quality model from the Xilinx model zoo to determine if the image has sufficient resolution to perform recognition.
Thread 4 accelerates the face features using the facerec_resnet20 model from the Xilinx model zoo.
Thread 5 compares the results of the face features with a database of known faces.
Conclusion
With the growth of connected smart devices and the Internet of Things, face applications are becoming increasingly essential parts of security and safety. Modern methods based on deep learning have advantages in accuracy over traditional methods, but are slower and require a great deal of processing power. Hardware accelerators, such as the Xilinx Zynq-UltraScale+, in conjunction with its Vitis-AI software, give these modern algorithms a boost in speed by shifting the calculations to hardware accelerators.
*Trademark. Xilinx is a trademark of Xilinx Inc. Other logos, product and/or company names may be trademarks of their respective owners.
Related ComponentsBack to Top

The element14 ESSENTIALS of AI Face Applications gives an overview of common algorithms for face detection/recognition, including examples of hardware acceleration with Xilinx devices using Vitis-AI. To extend the knowledge covered in the main module, this supplementary guide discusses the types of related components used for prototyping or product development.
Zynq 7000

The Zynq -7000 SoC ZC702 Evaluation Kit includes all the basic components of hardware, design tools, IP, and pre-verified reference designs including a targeted design, enabling a complete embedded processing platform. The included pre-verified reference designs and industry-standard FPGA Mezzanine Connectors (FMC) allow scaling and customization with daughter cards.
-7000 SoC ZC702 Evaluation Kit includes all the basic components of hardware, design tools, IP, and pre-verified reference designs including a targeted design, enabling a complete embedded processing platform. The included pre-verified reference designs and industry-standard FPGA Mezzanine Connectors (FMC) allow scaling and customization with daughter cards.
The Ultra96-V2 is an Arm-based, Xilinx Zynq UltraScale+ MPSoC development board based on the Linaro 96Boards Consumer Edition (CE) specification. Ultra96-V2 is available in more countries around the world as it has been designed with a certified radio module from Microchip. Additionally, Ultra96-V2 is available in both commercial and industrial temperature grade options. Additional power control and monitoring is possible with the included Infineon Pmics. Like Ultra96, the Ultra96-V2 boots from the provided Delkin 16 GB microSD card. Engineers have options of connecting to Ultra96-V2 through a Webserver using integrated wireless access point capability or to use the provided Linux Matchbox windows environment which can be viewed on the integrated Mini DisplayPort video output.
MPSoC development board based on the Linaro 96Boards Consumer Edition (CE) specification. Ultra96-V2 is available in more countries around the world as it has been designed with a certified radio module from Microchip. Additionally, Ultra96-V2 is available in both commercial and industrial temperature grade options. Additional power control and monitoring is possible with the included Infineon Pmics. Like Ultra96, the Ultra96-V2 boots from the provided Delkin 16 GB microSD card. Engineers have options of connecting to Ultra96-V2 through a Webserver using integrated wireless access point capability or to use the provided Linux Matchbox windows environment which can be viewed on the integrated Mini DisplayPort video output.




The UltraZed-EV Starter Kit consists of the UltraZed-EV System-on-Module (SOM) and Carrier Card bundled to provide a complete system for prototyping and evaluating systems based on the Xilinx powerful Zynq UltraScale+ MPSoC EV device family. The UltraZed-EV SOM PS MIO and GTR pins implement the microSD card, Pmod, USB 2.0/3.0, Gigabit Ethernet, SATA host, DisplayPort, PCIe root port, dual USB-UART, user LED, and switch and MAC address device interface. Third 120-pin Micro Header provides access to the UltraZed-EV SOM PS MIO and GTR transceiver pins, as well as USB and Tri-Ethernet interfaces. Mates with UltraZed-EV SOM via two 200-pin Micro Headers, connecting the UltraZed-EV PL I/O and transceivers to FMC HPC slot, LVDS touch panel interface, SFP+ interface, HDMI In/Out, 3G-SDI In/Out, pushbutton switches, DIP switches, LEDs, Xilinx System.
The Xilinx Kria KV260 Vision AI Starter Kit is comprised of a non-production version of the K26 system-on-module (SOM), carrier card, and thermal solution. The SOM is very compact and only includes key components such as a Zynq UltraScale+ MPSoC based silicon device, memory, boot, and security module. The carrier card allows various interfacing options and includes a power solution and network connectors for camera, display, and microSD card. The thermal solution has a heat sink, heat sink cover, and fan. The Kria KV260 Vision AI Starter Kit is designed to provide customers a platform to evaluate their target applications and ultimately design their own carrier card with Xilinx K26 SOMs. While the SOM itself has broad AI/ML applicability across markets and applications, target applications for the Kria KV260 Vision AI Starter Kit include smart city and machine vision, security cameras, retail analytics, and other industrial applications.

Kria KV260 Vision AI Starter Kit SK-KV260-G
Kria KV260 Vision AI Starter Kit SK-KV260-G-ED

Kria KV260 Basic Accessory Pack
Alveo Accelerator Cards

Xilinx U250 Alveo Data Center accelerator cards are designed to meet the constantly changing needs of the modern Data Center, providing an up to 90X performance increase over CPUs for most common workloads, including machine learning inference, video transcoding, and database search & analytics. Built on the Xilinx UltraScale architecture, Alveo accelerator cards are adaptable to changing acceleration requirements and algorithm standards. Enabling Alveo accelerator cards is an ecosystem of Xilinx and partner applications for common Data Center workloads. For custom solutions, Xilinx’s Application Developer Tool Suite (SDAccel) and Machine Learning Suite provide frameworks for developers to bring differentiated applications to market.
Versal ACAP

Versal Prime Series VMK180 Evaluation Kit
The Versal Prime series VMK180 evaluation kit is your fastest path to application bring-up using the world’s first adaptive compute acceleration platform (ACAP). The VMK180 evaluation board features the Versal Prime series VM1802 device, which combines a software programmable silicon infrastructure with world-class compute engines and a breadth of connectivity options to accelerate diverse workloads in a wide range of markets.
For more available products
Test Your KnowledgeBack to Top

Are you ready to demonstrate your knowledge of AI Face Applications? Then take a quick 10-question multiple choice quiz to see how much you've learned. To earn the Artificial Intelligence IV Badge, read through the learning module, attain 100% on the Quiz, leave us some feedback in the comments section, and give the learning module a star rating.
| AI4.pdf |








