



Introduction
This is hopefully going to be a series of posts describing how I've gone about learning LabVIEW as part of the LabVIEW Challenge by building a reasonably complex application and investigating best practice approaches with the tool. By "best practice" I mean in the context of what is useful and suitable in the scope of this application, for myself rather than additional practices necessary for a corporate environment or production suitable solution.
Hopefully I'll be able to get across how easy or difficult it is to pick up the tool for anyone new to it, although I definitely won't be doing this on a click-by-click basis! I will highlight critical LabVIEW features and techniques as I discover them and show key elements in some detail though. I'd be happy for anyone who is more experienced to jump in and tell me a better way of doing things.
My current experience with LabVIEW is none. I have, however, some experience with LabVIEW NXG, a now aborted product originally intended to replace LabVIEW, which I investigated a couple of years ago and used to build the same application. Clearly, then, there are similarities between the products - LabVIEW is significantly more developed and feature-rich than LabVIEW NXG - so it won't be like starting totally from scratch. It will also be interesting to see how LabVIEW will allow me to improve the framework where it was limited by LabVIEW NXG features.
The Hardware Abstraction Framework (HAF) is an extensible LabVIEW library designed to abstract the complexity of integrating with multiple test instruments and coordinating interactions across them during a testing session, e.g. stepping a PSU to inject voltages into a test circuit and measuring circuit behaviour by one or more DMMs at each step change. This is SCPI based but doesn't have to be: as long as a test instrument is capable of being connected to by LabVIEW, and has a means of automating, then it should be possible to interact with it through the framework. This is just a summary of intent, a further post will cover the design; obviously it will be very similar to the LabVIEW NXG version already described here. (Here's a spoiler: I've been able to make some improvements)
For future reference these posts are based on LabVIEW 2023 Community Edition. This first post describes how I have setup my development environment and why, with decisions made following research online and reading help and white papers.
Table of Contents
Background Information
This section is a bit wordy, sorry, but it's sort of necessary because it describes aspects of LabVIEW that impact design decisions and development approaches.
[TL/DR]
Basically, OO in LabVIEW is not exactly the same as might be experienced in Java or C# - the main thing being that where one might be used to using Object References, LabView is all by-value (copies of instances.) This supports LabVIEW's highly parallelised operation and guarantees data integrity, although not data consistency which is application managed. It is possible to take a by-reference approach but that has different implications in LabVIEW (data consistency but not guaranteed data integrity which is application managed.) There are other aspects of OO that are different but not necessary to know in a TL/DR.
Also, LabVIEW is not integrated directly with Git so all source control activity is handled externally.
If you read the TL/DR, you can skip to Getting Started.
Understanding How LabVIEW works
Watch the training videos posted on Element 14 here. It is a good introduction to the core concepts and a useful refresher for me, and should give some domain terminology for anyone reading. Also, I don't wish to describe this in a post as it's unlikely to be anywhere near as clear!
Object Oriented Programming in LabVIEW
Object Oriented Programming will be used to develop the framework. It is worth reading this white paper to understand how LabVIEW implements this paradigm as there are differences to OO languages such as Java and C#. Given I'm new to LabVIEW some of the concepts weren't immediately obvious or understandable and required a bit of research in order to properly contextualise the information but was worth doing.
The main difference to be aware of is that natively, LabVIEW supports a by-value approach to OO and not a by-reference one, simply:
- By-value: when an object is passed to a VI, forks on a wire or tunnels into a construct, then a copy is made and any changes to attributes are on that copy only and only for as long as that copy exists.
- By-reference: when an object is passed to a VI, or a wire for the object instance is branched, then a reference to the object is passed and changes to attributes affect the originating instance and thus visible wherever it is used.
Why does that matter?
- By-value: If a copy of an instance is changed, then it may be necessary to synchronise that instance with the originating one or perhaps replace it altogether. If parallel processes are executing, both using an instance of the class which should be the same, how is that achieved - message passing, data queues…? It requires an awareness when programming of the implications of working on copies (by-value instances) and forgetting can introduce subtle bugs as I found with LabVIEW NXG (why hasn’t that data changed?) However, this is the native architecture of LabVIEW so is in coherence with the way it works and its highly parallelised execution. By-value prevents issues such as race conditions and deadlocks and means that LabVIEW can guarantee data integrity (but not data consistency without developer involvement!)
- By-reference: shared instances is the normal execution pattern used by OO languages and the pattern of thinking of programmers coming from those languages. It requires an acceptance and understanding of an application’s architecture when updating attributes of an instance in respect to the overall “where and when” that can happen in a program’s execution. Inherently, with multi-threaded, parallelised applications, issues such as race conditions and deadlocks raise their head; single threaded applications won’t suffer these issues of course. LabVIEW is highly parallelised so an acute awareness of this is required. It will imply that certain code execution paths, e.g. reading - updating - writing an attribute, needs to be atomic with respect to the whole application and thus blocking to other threads. That’s not something we really want to do lots of in LabVIEW programs. In any case, I suspect this approach will also introduce subtle bugs as anyone who has been involved in multi-threaded development can attest to.
It is possible to take a by-reference approach with LabVIEW as it provides mechanisms to do so and additionally installable packages can simplify that. The choice therefore isn’t just “by-value” because that’s what is available and clearly there are trade-offs to be made with either approach. There are numerous discussions of the pros-and-cons (hints in this thread) but I suspect that anyone who is experienced in OO will be able to make their own decision; as usual with engineers, there are supporters and detractors of both approaches.
Given this is about learning LabVIEW I will be sticking with its native by-value architecture.
Other differences worth being aware of:
- LabVIEW is strongly typed and does not support the concept of NULL. It's not possible to tell if an instance has been initialised with, say, a zero value for an attribute or purposefully set at zero - at least, not without additional code. The usefulness of NULL in OO crops up more often than you may think.
- There is no overloading of methods, all methods must have a unique name and any inputs and/or outputs don't form part of the method's identity. There is a mechanism called "Dynamic Despatching" which allows methods to be overridden and the correct one to be executed at runtime.
- LabVIEW definitely has some functionality supporting reflection but I don't know yet how extensive it is. Reflection is useful where dynamic instantiation of test devices or commands is required at runtime from, say, a configuration file (think test scripting rather than UI initiation.) Also, think Factory Pattern. I don't believe there is an equivalent of something like "isTypeOf" for determining what is being used at runtime; yeh, I know, that would make you feel a little queasy, but sometimes it is necessary and part of a need for Reflection.
- There is no real concept of "Abstract" and any class can be instantiated. It would appear there is a view that creating a Class without any properties makes it abstract, but that seems wrong to me: an abstract class can, and often does, have properties that are inherited by subclasses. I think the argument goes that without properties, it's just a collection of VIs. It's not a massive issue of course because I just avoid instantiating anything that should be abstract.
- Interfaces are available to use. A class can "inherit" (because that's how it's articulated, rather than implement) multiple interfaces and then have to provide an implementation of the methods. The reason that interfaces are used with the term inherit is because they can actually carry implementation and not just define expected behaviour (they also can't carry state); this is promoted as a form of multiple inheritance which I suppose it is, but leads to some very complex inheritance graphs.
Source Control with LabVIEW
I’m going to configure LabVIEW to use Git as the Source Control system. No I’m not, LabVIEW doesn’t integrate directly with Git so all source control activity needs to be managed outside of LabVIEW. It does work with source control systems that conform to Microsoft Source Control Interface, e.g. Subversion and Perforce and these tools can be integrated directly into LabVIEW. I use GitKraken as a client but it’s not important; I'm also not going to follow any fancy Git process as it's just me, so Master and Development branches. Thus, I can use LabView and Git together, just not from within the LabVIEW tool so there are some things that need to be done to facilitate that:
- Separate compiled code from other file types: for an insight, read this white paper. Essentially, VIs are a mix of text and binaries and that makes it harder for source control to work with them because unchanged parts of the application are recompiled anyway looking like a change. It's possibly more of an issue for SVN which requires a file to be "checked out" before it can be modified whereas Git will just create a new changed version. I'll cover this setup later.
- create and populate a suitable .gitignore file
- create and populate a suitable .gitattributes file
Getting Started
Install LabView 2023 Community Edition. Nothing special here: download the installer, run it, follow the prompts. I'm installing into a Windows 11 VM on my iMac as my preference is to keep these tools in their own, managed environment especially as it's a big install. There are versions for MacOS and Linux. Check also that it installs the JKI VI Package Manager (VIPM) as well which is needed to find useful plug-ins; if not, run the NI Package Manager and search for it in the "Tools Network" category:
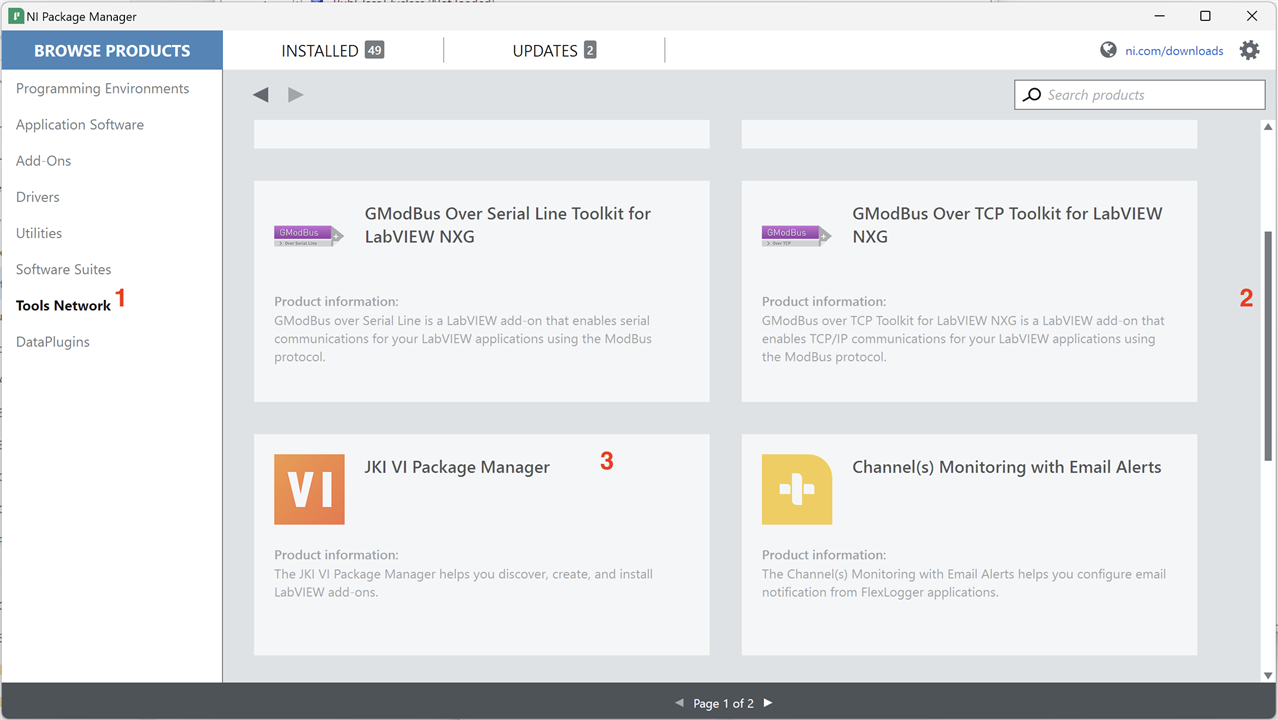
When I ran VIPM the first time it asked me what version I wanted to install. Given I didn't need a paid license, my choice was the "Free" version although the "Community" version would also work. The latter is best suited for packaging and sharing Open Source applications in the JKI community and not something I intend to do. The only thing not totally clear is the licensing: reading on their web page it would imply that "Free" is for Academic and Commercial purposes for finding and downloading (but not packaging) but is free for LabVIEW users. Sort of implies I both fit and don't fit the terms and I never received an answer to a query I raised about it. Given I only intend to download free to use packages I think I'm ok.
The reason for checking it is installed, or doing so, is that Packages seem to form a key means for adding additional functionality and tools into LabVIEW from other providers. I'll show how it works below and may find myself using it later in development if there are tools that will help me.
Environment Setup
Toolkit to Ease OO Development
First off, perform an initial setup of LabVIEW. Under Source Control above, I mentioned separating compiled types. This is a LabVIEW option set via the menu Tools>Options>Environments:
It would seem that the default setting at install is to set this option because it is a common requirement.
Next, I want to cover off installing a toolkit that supports a by-reference OO development approach. I will install this but I won't be using it as mentioned earlier, but it is a useful demonstration of the Package Manager and may be of use to someone. There are 3 options I have found:
- G#: an open source toolkit from AddQ Consulting that allows for native by-value or by-reference based OO programming. Seems well supported with a plug-in for WhiteStarUML for external design and also has a useful (by all accounts) debugger. Latest release in VIPM is 2.0.0.2 which works with LabVIEW 2020 onwards.
- NI GOOP (NI GDS): a free to use toolkit that can use native by-value or by-reference based OO programming. Last updated in 2017 according to VIPM so quite old. Has a UML plug-in within the IDE. I don’t know if it fully supports all the OO features of LabVIEW given its age, e.g. Interfaces was a feature that appeared in LabVIEW 2020.
- Open GOOP (OpenGDS): a continuation of NI GOOP under an Open Source license so a little more current. Better obtained from the project's homepage rather than VIPM which only references an older version not best suited for LabVIEW 2020 onwards. Has a UML plug-in within the IDE.
So what’s my thinking?
- Of the three, I have discounted NI GOOP simply because Open GOOP is more recent and seems to be maintained albeit not regularly.
- G# seems to be more frequently maintained and has a built-in debugger to aid with a by-reference programming approach - this is deep-in-the-weeds stuff but to simplify, it allows for object inspection during execution, something that standard LabVIEW can’t do, primarily because it’s not needed in a by-value approach. Open GOOP does not have a similar feature, as far as I can tell, so it may be a problem later (I just don’t know yet.)
- Why did I mentioned UML plug-in earlier? If I design the class model (inheritance, dependencies, interfaces etc..) in UML, it is possible to get the toolkit to automatically create the necessary classes and relationships saving some tedious setup. It also allows changes to the classes and relationships to be reversed into the model. However, I’ve always held very strong views about the problems of reverse-engineering models from code so I would only ever be interested in a one-way setup (model to code only) if at all. Open GOOP has this built in, G# has a plug-in for StarUML, now abandoned and supposedly replaced with WhiteStarUML which is also inactive. Previously, I’ve used a community version of Visual Paradigm (https://www.visual-paradigm.com) for UML modelling but there is no plug-in for this.
- My dislike of round-trip engineering plus the inclusion of a good debugger leads me to choose G# so that’s what I will install. I won't be using it but if I was, I wouldn’t bother with the plug-in for one-way engineering because it only links to unsupported and out of date software.
Run VIPM and wait for it to update the repositories which can take quite some time. Search for G#, select it and click on the Install button. This will go ahead and do that and when finished VIPM can be closed.
Restart LabVIEW and check G# is installed by opening or creating a new project and checking for new options:

(Another check: under the open tools menu, a button to start the G# debugger is on the toolbar.)
Setting up for Reuse
I need to consider how I will actually develop this framework. The actual intention is that this is reusable for future applications created in LabVIEW for testing my projects. I could just copy the code from a "library" directory on my hard drive/One Drive, or clone from GitHub. Whatever I do doesn't need to be too complex because there's just me doing this. There's a great solution baked into LabVIEW: Project Templates. This allows a user to create a new project, based on a previously created one and which then sets up the new project with all the necessary elements to get started. It's possible to see this in action by creating a new project from the LabVIEW startup screen, and selecting a Template on the subsequent dialog. I will create and maintain this framework in the Project Template folder so that it is always available and up to date for consuming projects.
LabVIEW users can create their own controls, reusable VIs, wizards and so on which extends LabVIEW functionality and these need storing carefully in order that LabVIEW upgrades don't remove them. This white paper gives an overview of what can be added and where those items should be stored. Project Templates are stored under folder "LabVIEW Data" and how these are organised is described in this white paper.
"LabVIEW Data" is created during the install and is normally under the user documents folder. It can be checked by looking at Tools>Options>Paths and selecting Default Data Directory:
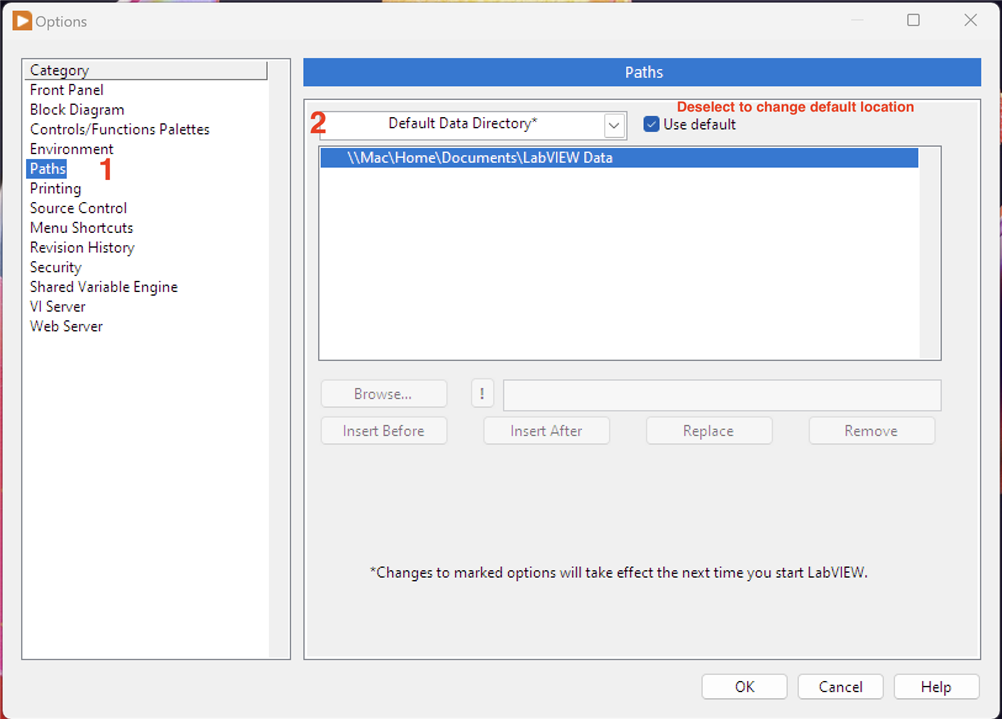
Note that I'm using Windows in a Parallels VM on my iMac so the user home folder is mapped to my MacOS user folder. I found this out later, but before publishing, that using a directory that maps to a network drive such as \\Mac\ causes a problem when creating a project from a template - LabVIEW can't handle it - so I had to change this to an alternative mapping Y:\Home\...
If this needs relocating, just deselect the "Use default" option to enable the "Browse" button/file path entry field and select a new location. LabVIEW will automatically re-populate the new directory as needed and will not remove anything from the old location. Note that any files added by the user are not copied over, only default directory structures/contents. Reselect that option to shift back again.
One potential issue is "What happens in the future if the framework is updated or a bug is fixed, how is this rolled out?" It's a good question, because creating a new project from a template copies the template structure into the new project's location thus creating a completely separate code instance. Fortunately, it is possible to update it in situ:
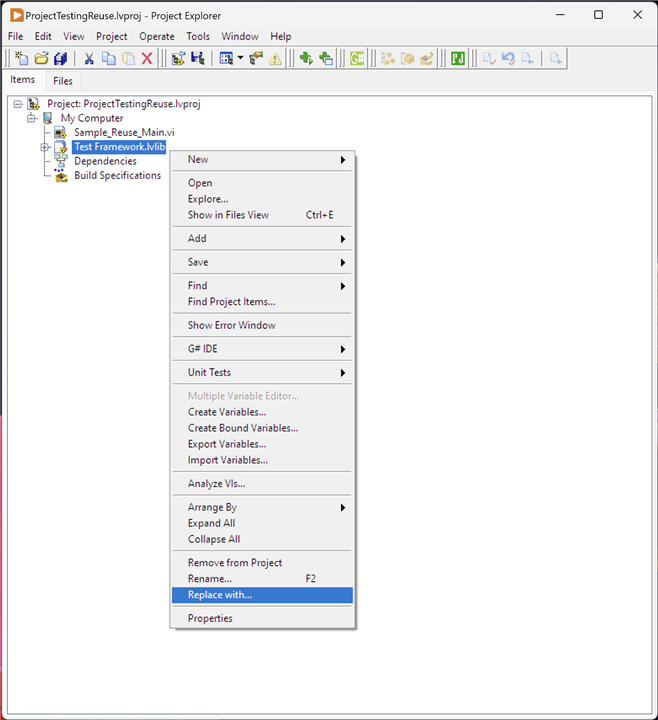
In the example above, I created a new project called "ProjectTestingReuse" from a Project Template which populated it with "Sample_Reuse_Main.vi" and "Test Framework.lvlib". Having made changes to "Test Framework.lvlib" I can select it in the consuming project, right-click and from the context menu select Replace With and select the updated library file. It's worth noting that when I tried this, LabVIEW through up a spurious error stating that the selected code wasn't created in the same version of LabVIEW and subsequently unloaded "Test Framework.lvlib" from the project. Bit weird, but right clicking the file and selecting "Load" brought the updated version back into the project.
So I now have a place to create and update the framework and a means to easily consume it with testing applications. I'll actually set up the folder structure for Project Templates under "LabVIEW Data", as described by the white paper linked above, when I create the repository in Git shortly.
Supporting UML Design Tool
I mentioned earlier that the OO toolkits had UML capability, whether directly in LabVIEW or via a plug-in. I don't want to do any reverse engineering between a UML model and code, but I do want to capture the design and use it as part of the Project Template in its "Documentation" folder. I'll probably stick with a class diagram rather than go all in with an extensive model, but it may prove useful to create some sequence diagrams for understanding tricky interactions and messaging. I'll install Visual Paradigm Community Edition, download here. It is sufficiently featured enough for my purposes. It's Windows only but any UML tool, even just something like Visio or platform equivalent would do.
The only setup after installation is to obtain a (free) license key during the first run; any further configuration I'll go through when I start to capture the design.
Setup Source Control and Repository
I need to set up the following structure under ~\LabVIEW Data\":
\ProjectTemplates\CategoryOverrides \ProjectTemplates\MetaData \ProjectTemplates\Source\HAF\documentation \ProjectTemplates\Source\HAF\images
Framework code will sit in folder \HAF\ and any sub-folders I create to organise the project clearly. As the \CategoryOverrides\, \MetaData\ and \Source\ directories are shared across all Project Templates, I need to keep \ProjectTemplates\ within the Repository, which I will call "LabVIEW_Project_Templates".
It would be nice if I could have a way of grouping repositories under a master name in GitHub, e.g. like the idea of a Folder called LabVIEW with subfolders (actual repositories) called "Project_Templates", "Test_Apps", "Etc", but GitHub doesn't have any way to achieve that. I could just call the repository LabVIEW but then there's no easy way of differentiating the individual projects within that, i.e. when I want to just clone "Project_Templates" I don't also want "Test_Apps". There is pseudo-grouping as GitHub Lists but that isn't quite the same.
The selected .gitignore file from a LabVIEW template was selected which looks like this:
# Libraries *.lvlibp *.llb # Shared objects (inc. Windows DLLs) *.dll *.so *.so.* *.dylib # Executables *.exe # Metadata *.aliases *.lvlps .cache/
Due to the way some LabVIEW files are constructed they contain both text and binary data. Additionally, Visual Paradigm files also need to be considered as binary. To ensure that Git doesn't mess this up treats these files as binary I need to add a .gitattributes file at the same level as .gitignore containing the following:
*.vi binary *.vim binary *.lvproj binary *.lvclass binary *.lvlps binary *.aliases binary *.lvlib binary *.vit binary *.ctl binary *.ctt binary *.xnode binary *.xcontrol binary *.rtm binary *.vpp binary
The "binary" attribute is actually a Macro Attribute: it combines together a number of single attribute settings against the file to ensure it is handled correctly.
Also, and obviously, I need to create the folders listed at the beginning of this section.
Create the Project Template and Project
It's probably a little early, but I'm creating the necessary Project Template files that control how the framework will be managed by LabVIEW when creating a new project:
In CategoryOverrides create file "MyTemplateCategoryOverrides.xml":
<?xml version='1.0' encoding='windows-1252' standalone='yes'?>
<CategoryOverrides>
<Category>
<Name>My Templates</Name>
<Priority>10</Priority>
</Category>
</CategoryOverrides>
Giving a priority level of 10 means it will appear above the in-built Categories.
In MetaData create file "HAFTemplateMetadata.xml":
<?xml version="1.0" encoding="windows-1252" standalone="yes"?> <MetaData> <ProjectTemplate> <Title>Hardware Abstraction Framework</Title> <Description>Abstracts the complexity of interacting with Test Instruments and automating their operation.</Description> <Filters>My Templates:Test Support</Filters> <Keywords>hardware;abstraction;framework;architecture</Keywords> <LocationPath>HAF</LocationPath> <ProjectPath>Hardware Abstraction Framework.lvproj</ProjectPath> <ListboxImagePath>images/HAF_small.png</ListboxImagePath> <DocumentationPath>documentation/Hardware Abstraction Framework Documentation.html</DocumentationPath> <CustomVIMode>None</CustomVIMode> <SortPriority>300</SortPriority> </ProjectTemplate> </MetaData>
I've defined the category (filter) with Test Support as a child: this becomes a sub-grouping under My Templates when there is more than one child category but is not seen otherwise. Just helps further organise future templates.
In \Source\HAF\documentation add a placeholder file "Hardware Abstraction Framework Documentation.html":
In \Source\HAF\images add a thumbnail file, 32x32 pixels "HAF_small.png":
Finally, in LabView, create a new project from a Blank Template and save it in "\source" as "Hardware Abstraction Framework". It's not necessary to add anything into the project yet, but LabVIEW won't display the template without the project file existing. Once this step is done, I can check that the Project Template is correctly set up:
These changes can be committed into the repository - note, I haven't created any development branch yet but that's ok.
LabVIEW and the project are now set up ready for development.
Summary
I covered a lot here, in what is quite a long post:
- LabVIEW's architecture is highly parallelised and works on what NI calls Data Flow execution: basically, any piece of code will execute once, and as soon as, all its data is available. That means as a developer you don't necessarily control the specific sequence in which your code runs with some functions executing concurrently. Obviously you control the generation and flow of the data so it's not a "random" execution path (hence the term data flow execution) and there are constructs available to guarantee that some piece of code must finish before another piece is executed, e.g. Sequence Structures.
- LabVIEW supports an Object Oriented Programming approach to application development. Given the highly parallelised architecture, NI has taken the view that objects will work with a "by-value" approach rather than the normal "by-reference" common to other OO languages. This is so they can guarantee data integrity and prevent problems such as race conditions and deadlocks. It does introduce the need for the developer to re-synchronise data with other instances if required so data consistency is not guaranteed. It will support a by-reference approach through the use of a mechanism called DVR (Data Value Reference) which is essentially a pointer to a memory location. The issue with using DVRs is that LabVIEW cannot guarantee data integrity without the use of blocking code around functionality that needs to be atomic. Either approach requires a developer to be on their toes.
- Many of the standard OO mechanisms still apply, but there are some aspects that will need to be worked around, e.g. NULL and Reflection. It is still feature rich though.
- LabVIEW will directly integrate with Source Control solutions that conform to Microsofts Source Control Interface such as Subversion and Perforce. Any solution that doesn't conform must be operated externally to LabVIEW, including Git. In practice, this probably makes no real difference and there would be no reason I can see for switching. Whatever solution is used, care must be taken in setting up Source Control as many LabVIEW file types need managing as Binarys given the way LabVIEW compiles VIs requires separating the compiled binary from the source.
- There are probably multiple ways of managing code for reuse with LabVIEW and I've identified two ways: utilising packaging to distribute the code across consumers; or utilising Project Templates to allow an initial setup of an application to be made. My view of packaging, using VIPM, is that it is ideally suited to situations where usage is distributed across many installations as it seems simple to implement and manage. Project Templates are great where the codebase to be re-used forms a starting point for future applications. This is the case with the HAF where I will have a framework and an example application that can be modified, extended or ignored as needed.
NEXT: Designing the Framework



