I recently stumbled across this great ebook:

Available at: https://personal.utdallas.edu/~pervin/RPiA/RPiA.pdf
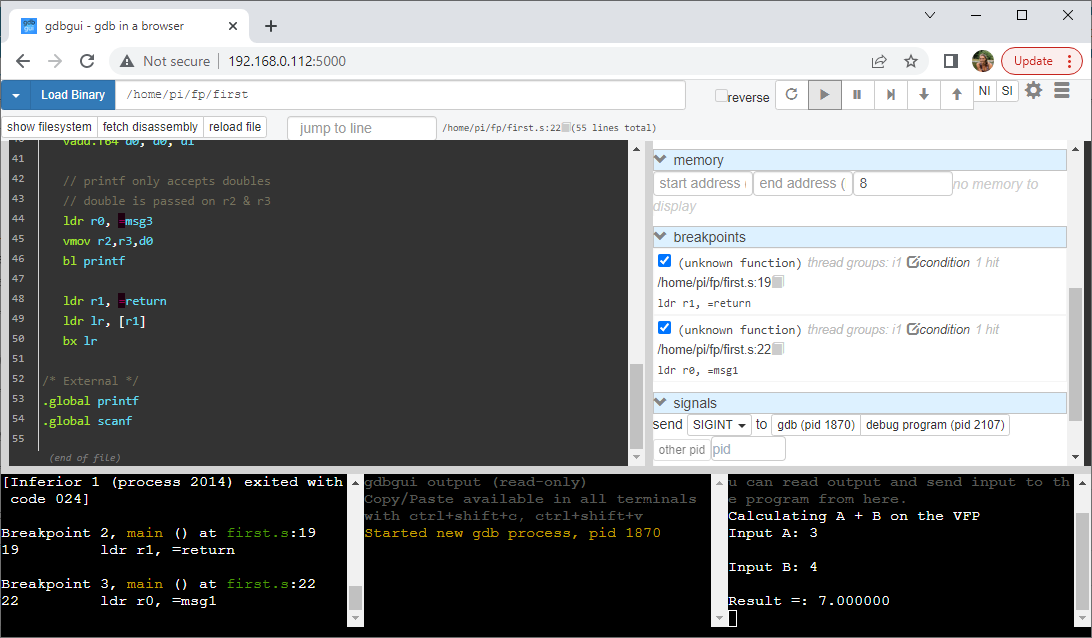
Following along the yellow brick road, I was able to get a basic program up and running. It takes two numbers as user input and calculates their sum. Thrilling! I know. Though kind of, as the addition is in double precision floating point and happening on the VFP of the cortex-A53. I should note I am still using a 32-bit os on the pi, it will be interesting to see what changes when I move to the new 64-bit os.
.data
msg1: .asciz "Calculating A + B on the VFP\nInput A: "
msg2: .asciz "\nInput B: "
msg3: .asciz "\nResult =: %f\n"
scan_pattern : .asciz "%lf"
.balign 4
return: .word 0
.balign 8
d1: .double 0.0
d2: .double 0.0
.text
.global main /* entry point must be global */
.func main /* ’main’ is a function */
main: /* This is main */
ldr r1, =return
str lr, [r1]
ldr r0, =msg1
bl printf
ldr r0, =scan_pattern @ r0 <- &scan_pattern
ldr r1, =d1
bl scanf
ldr r0, =msg2
bl printf
ldr r0, =scan_pattern @ r0 <- &scan_pattern
ldr r1, =d2
bl scanf
ldr r1, =d1
vldmia.f64 r1, {d0-d1}
vadd.f64 d0, d0, d1
// printf only accepts doubles
// double is passed on r2 & r3
ldr r0, =msg3
vmov r2,r3,d0
bl printf
ldr r1, =return
ldr lr, [r1]
bx lr
/* External */
.global printf
.global scanf
the makefile to assemble and link the program:
# Makefile all: first fploop fploop: fploop.o gcc -g -o $@ $+ fploop.o : fploop.s as -g -mfpu=vfpv2 -o $@ $< first: first.o gcc -g -o $@ $+ first.o : first.s as -g -mfpu=vfpv2 -o $@ $< clean: rm -vf first fploop *.o
Testing it out:
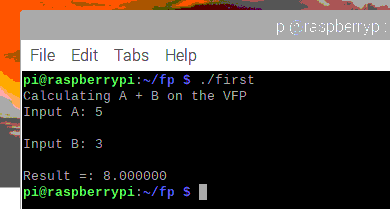
Amazing! lol
I also experimented with seeing how long some of the VFP instructions take. In this program I run a tight loop 1 billion times on a VFP instruction:
.data
msg1: .asciz "Looping: (%d) times...\n"
msg2: .asciz "\nResult =: %3.1e\n"
scan_pattern : .asciz "%lf"
.balign 4
return: .word 0
loopcount: .word 1000000000
.balign 8
d1: .double 1.0
d2: .double 1.0
.text
.global main /* entry point must be global */
.func main /* ’main’ is a function */
main: /* This is main */
ldr r1, =return
str lr, [r1]
ldr r0, =msg1
ldr r1, =loopcount
ldr r1, [r1]
bl printf
ldr r1, =d1
vldmia.f64 r1, {d0-d1}
ldr r1, =loopcount
ldr r1, [r1]
loop:
// vadd.f64 d2, d0, d1
// vadd.f64 d0, d0, d1
// vmla.f64 d2, d0, d1
subs r1, r1, #1
bne loop
ldr r0, =msg2
vmov r2,r3,d0
mov r1,#0
bl printf
ldr r1, =return
ldr lr, [r1]
bx lr
/* External */
.global printf
.global scanf
Just the loop itself, the sub and conditional branch run at the full system clock rate. Pretty snazzy!

(d1 never got modified so it remained at its initial value of 1.)
Adding one VFP instruction at a time and reassembling and running results in the following:
vadd.f64 d2, d0, d1 => 2s
vadd.f64 d0, d0, d1 => 4s
vmla.f64 d2, d1, d0 => 4s
That is a lot of processing power for a $15 development board.