


In this post, I will discuss how I implemented the reading of the IMU sensor mounted on the Arduino Nano 33 IoT and the sliding window algorithm used to detect acceleration peaks
Reading IMU
Reading the IMU on the Arduino Nano 33 IoT is really easy: you just need to install the library Arduino_LSM6D3 from the IDE's Library Manager...
and run the following sketch to have access to both the accelerometer and gyroscope
#include <Arduino_LSM6DS3.h>
void setup() {
Serial.begin(9600);
while (!Serial);
if (!IMU.begin()) {
Serial.println("Failed to initialize IMU!");
while (1);
}
Serial.print("Accelerometer sample rate = ");
Serial.print(IMU.accelerationSampleRate());
Serial.println(" Hz");
Serial.print("Gyroscope sample rate = ");
Serial.print(IMU.gyroscopeSampleRate());
Serial.println(" Hz");
Serial.println();
Serial.println("Acceleration in G's \tGyroscope in degrees/second");
Serial.println("X\tY\tZ"\t\t\t\tX\tY\tZ);
}
void loop() {
float x, y, z;
if (IMU.accelerationAvailable()) {
IMU.readAcceleration(x, y, z);
Serial.print(x);
Serial.print('\t');
Serial.print(y);
Serial.print('\t');
Serial.print(z);
}
if (IMU.gyroscopeAvailable()) {
IMU.readGyroscope(x, y, z);
Serial.print('\t\t\t\t');
Serial.print(x);
Serial.print('\t');
Serial.print(y);
Serial.print('\t');
Serial.println(z);
}
}
Detecting peak
A bit more complicated is how to detect the acceleration peak. Detecting the acceleration peak is very important in order to
- invoke the neural network with data that resembles the data in the training dataset. This makes the classification more reliable
- invoke the neural network (which is both power-hungry and time-consuming) only when some anomalies in the acceleration values are detected
I devised a sliding window algorithm with a pre-peak window of 1 second (20 samples if the sampling frequency is 50 Hz). Since the fall detection is performed by the neural network, we just need a rough anomaly detection: a threshold-based detection is enough to detect abnormal accelerations.
I just compared acceleration norm
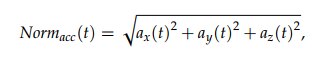
with a fixed threshold.
For the angular velocity reported by the gyroscope, I just checked whether one of the three values is above a given threshold.
When either the acceleration norm or one of the angular velocities is above the threshold, features are calculated on pre-peak data, and from this point on we will calculate all the features iteratively
// store prepeak data
SENSOR_DATA* sd = &prePeak[prePeakIdx];
sd->ax = ax;
sd->ay = ay;
sd->az = az;
sd->gx = gx / FALLDET_DEG_SCALE;
sd->gy = gy / FALLDET_DEG_SCALE;
sd->gz = gz / FALLDET_DEG_SCALE;
prePeakIdx = (prePeakIdx + 1) % FALLDET_PREPEAK_NUM_SAMPLES;
// sum up the absolutes
float aNorm2 = (ax*ax) + (ay*ay) + (az*az);
// check if it's above the threshold
if ((aNorm2 >= FALLDET_ACC_THRESHOLD_2) || (gx > FALLDET_DEG_THRESHOLD) || (gy > FALLDET_DEG_THRESHOLD) || (gz > FALLDET_DEG_THRESHOLD)) {
// compute aggregates
computePrepeakAggregates(aggregates, prePeak, prePeakIdx, FALLDET_PREPEAK_NUM_SAMPLES);
// reset the sample read count
samplesRead = FALLDET_PREPEAK_NUM_SAMPLES;
}
Calculating features
As I wrote in this blog, neural network requires aggregated data, namely (for each axis of the accelerometer and of the gyroscope)
- minimum
- maximum
- average
- standard deviation
- average of the difference between two consecutive samples
- average of the norm
The calculation of minimum and maximum is trivial. Averages and standard deviation requires some attention because we want to implement an iterative calculative in order not to store all samples and thus save some precious RAM.
For the average, we will the following formula
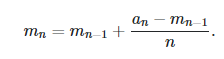
Regarding the standard deviation, the solution comes from the Welford algorithm
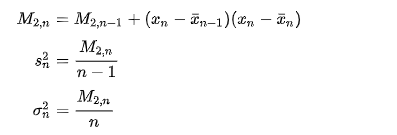
where "M2,n" is the squares of differences from the current mean, 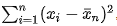 . This algorithm is much less prone to loss of precision due to catastrophic cancellation, but might not be as efficient because of the division operation inside the loop.
. This algorithm is much less prone to loss of precision due to catastrophic cancellation, but might not be as efficient because of the division operation inside the loop.
Invoking the neural network
When 300 samples have been collected, neural network is invoked. First, features like standard deviations are calculated
// finalize aggregates
finalizeAggregates(aggregates, samplesRead);
Then features are copied to the neural network's input buffer
// input tensor
for (int i=0; i<FALLDET_NUM_FEATURES; i++)
tflInputTensor->data.f[i] = (float)aggregates[i];
The interference engine is executed
// Run inferencing
TfLiteStatus invokeStatus = tflInterpreter->Invoke();
if (invokeStatus != kTfLiteOk) {
Serial.println("Invoke failed!");
return -1;
}
And finally the single output value is gathered from the output buffer
Serial.println(tflOutputTensor->data.f[0], 6);
We return true or false depending on whether the output value is above or below a threshold placed at 0.5 (output value ranges from 0 to 1)
return (tflOutputTensor->data.f[0] > 0.5);
| Previous post | Source code | Next post |
|---|---|---|
| ACE - Blog #4 - The neural network | https://github.com/ambrogio-galbusera/ace2.git | ACE - Blog #6 - Adding simplicity |