



Introduction
This is the first project of a series on the subject of deploying the MediaPipe models to the edge on embedded platforms.
I will start by giving a general overview of the MediaPipe models, and some of the challenges that can be expected when running on embedded hardware.
Then I will dive into the architecture of its most popular models (hand/face/pose detection and landmarks).
Finally, I will introduce an custom python application that I created as a tool for running, debugging, and profiling alternate implementations of these models.
Status of the MediaPipe models
MediaPipe is a framework created by Google that implements detection for the following applications:
- palm detection and hand landmarks
- face detection and landmarks
- pose detection and landmarks
- etc…

 : Google)
: Google)-
TF-Lite (models)
-
Bazel (build tools)
The first public versions of the MediaPipe models appeared in 2019, which can be considered a very long time ago with respect to AI/ML’s rapid evolution.
The latest version of the MediaPipe framework, as of this writing, is v0.10.xx, which is still considered a development version.
Since its first public release, Google has made continual improvements to its MediaPipe framework.
One of the most notable improvements that was documented in 2021 was the improvement in hand landmarks for individual fingers, especially important for sign language applications.

MediaPipe hand landmarks model improvements ( : Google)
: Google)
In the latest version of the framework (v0.10.14), Google introduced a new MediaPipe LLM Inference API enabling select large language models (Gemma 2B, Falcon 1B, Phi 2, and Stable LM 3B).
It is interesting that Google have never published a 1.00 version, which would have been considered stable … most probably because they are continually improving the models and framework.
Challenges with the MediaPipe models
If using the MediaPipe framework on a modern computer, all that is required is a “pip install mediapipe”, and everything works out of the box !
The requirement to re-build the MediaPipe framework for a custom target, however, may be a challenge if not familiar with the Bazel build tools.
Re-training the models is not possible, since the dataset(s) used to train these models was never published by Google.
Deployment to specialized targets, which usually requires a sub-set of the training dataset presents the challenge of coming up with this data yourself.
Furthermore, many targets do not support the TF-Lite framework, so the models need to be converted to an alternate framework prior to deployment.
One example of this is OpenVINO, where the models are first converted to TensorFlow2 using PINTO’s model conversion utilities, before being fed into the OpenVINO framework.
Another example I ran into was deploying to Vitis-AI, where I had to work with models that had been converted to Pytorch. But this is a subject for another project …
Architecture Overview
It should be clear by now that these pipelines are implemented with two models, and can be called multi-inference pipelines. If we take the example of the palm detector and hand landmarks, we have the following dual-inference pipeline:
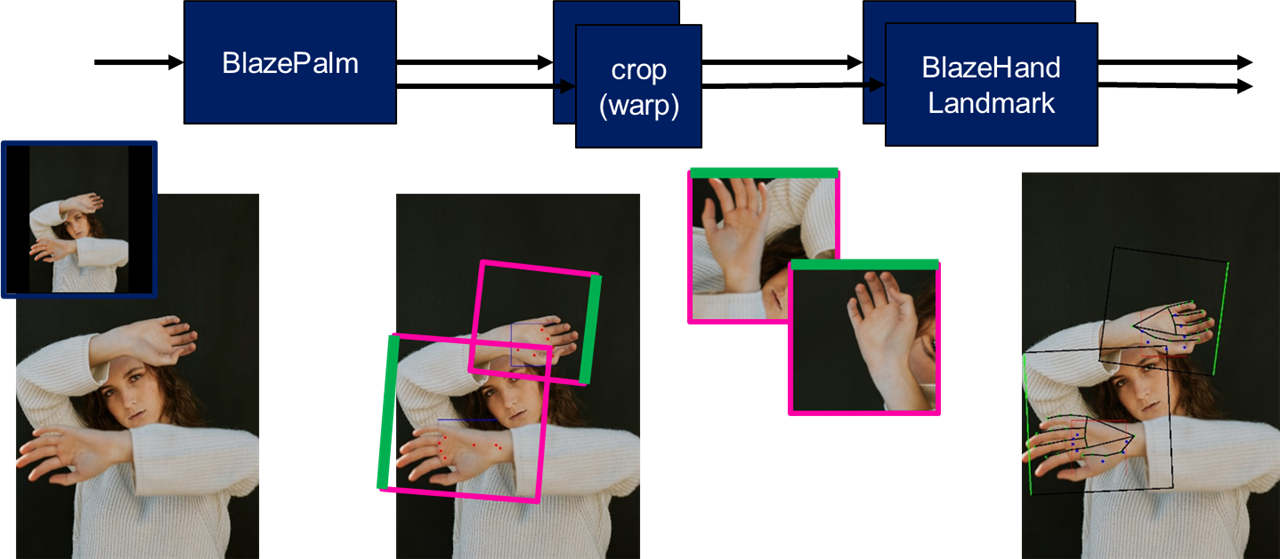 : AlbertaBeef)
: AlbertaBeef)The final hand landmarks are illustrated in the figures below:
 : Google)
: Google)Re-Inventing the wheel with python
Before attempting to deploy the MediaPipe models to embedded platforms, I took upon myself to create a purely python implementation of the pre-processing and post-processing, and explicitly running inference of the individual TF-Lite models.
 : AlbertaBeef)
: AlbertaBeef)Take the time to appreciate the details captured in the above video:
- the top three windows illustrate overall detection and landmarks for hand, face, and pose
- the bottom three “debug” windows illustrate the regions of interest (ROIs) that are extracted by the detector model, for the landmark model
The ROIs are extracted such that the hands, face, and even human pose are presented in the same orientation and size to the landmark model.
Notice for the case of the pose models, how the cropping is selected to include the entire body, even when it is not visible.
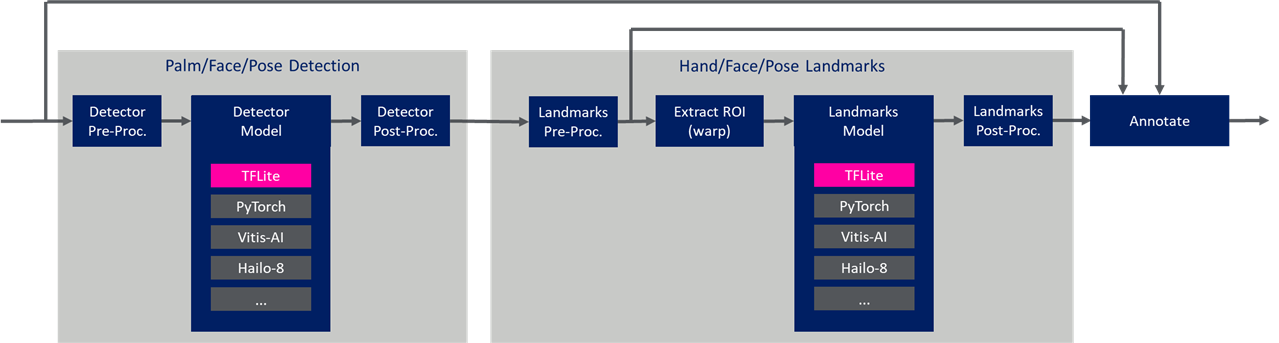 : AlbertaBeef)
: AlbertaBeef)The "blaze_app" python application provides a common base for performing the following experiments during my exploration:
-
Compare output from different versions of same models (0.07 versus 0.10)
-
Compare output from alternate versions of the models (PyTorch, …) with the reference versions (TFLite)
-
Identify and Profile latency of each component (model inference time, pre-processing, post-processing, etc…)
-
View intermediate results (ROIs, detection scores wrt threshold, etc…)
How Fast is Fast ?
On modern computers, the MediaPipe framework runs VERY fast !
On embedded platforms, however, things quickly break down, resulting in one frame per second in some cases …
The following benchmarks were gathered with my single-threaded python-only implementation in order identify where time is being spent for different components on various platforms:
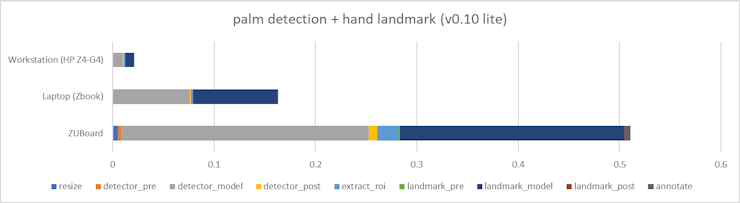 : AlbertaBeef)
: AlbertaBeef)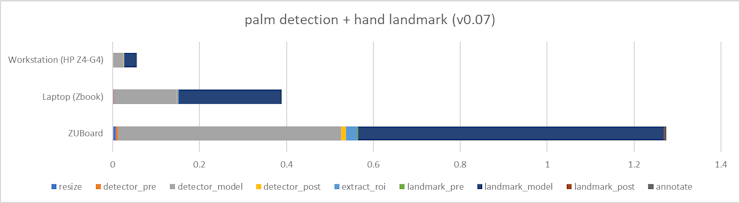 : AlbertaBeef)
: AlbertaBeef)On an embedded ARM A63 processing, the Palm Detection and Hand Landmark models run 3x slower than a modern laptop, and 20x slower than a modern workstation !
This is a case, where the models cannot be used out of the box, they need to be further accelerated. But once again, this is a subject for another project …
Going Further
For a more in depth overview of the dual-inference pipeline architecture and instructions on installing the python application, refer to my full write-up on Hackster:
I hope this project will inspire you to implement your own custom application.
Acknowledgements
I want to thank Google (https://www.hackster.io/google) for making the following available publicly:
- MediaPipe
References
- [Google] MediaPipe Solutions Guide : https://ai.google.dev/edge/mediapipe/solutions/guide
- [Google] MediaPipe Source Code : https://github.com/google-ai-edge/mediapipe
- [Google] SignALL SDK : https://developers.googleblog.com/en/signall-sdk-sign-language-interface-using-mediapipe-is-now-available-for-developers/
- [AlbertaBeef] blaze_app_python : https://github.com/AlbertaBeef/blaze_app_python
- [Hackster] Blazing Fast Models