



An exploration of the Kaggle datasets for ASL Recognition.
Introduction
This project provides a deep dive exploration into the Kaggle datasets provided by Google for their 2023 competitions related to ASL recognition:
- Google — Isolated Sign Language Recognition
- Google — American Sign Language Fingerspelling Recognition
Since an image is worth a thousand words, a video is certainly worth even more. To that end, I created viewers for these two datasets, as well as a similar viewer for a live USB camera feed. I chose to display the landmarks generated by the MediaPipe framework (holistic model, including pose, face, hands), as well as a time lapse of the most important landmarks.

 : AlbertaBeef)
: AlbertaBeef)In the video, I have captured myself executing two styles of sign language:
- sign language (ie. words and phrases) : THANK YOU
- fingerspelling : A, V, N, E, T
The Kaggle datasets provide captured examples for each style. The latter is used for content that is not covered with the sign language itself, such as phone numbers, web URLs, etc…
The Competitions
In 2023, Google launched two open-source competitions on Kaggle, totaling $300,000 in prizes.
Google — Isolated Sign Language Recognition
- https://www.kaggle.com/competitions/asl-signs/overview
- Feb-May 2023
- $100,000 Prize

 : Kaggle)
: Kaggle)Google — American Sign Language Fingerspelling Recognition
- https://www.kaggle.com/competitions/asl-fingerspelling
- May-Aug 2023
- $200,000 Prize
 : Kaggle)
: Kaggle)It is very interesting to analyze the winning solution for the Fingerspelling Recognition competition:
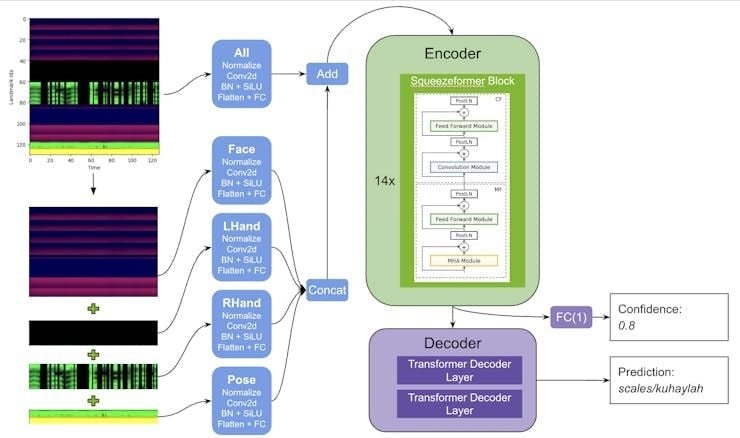 : Kaggle)
: Kaggle)The input to the solution are the following subset of 130 landmarks:
- 21 key points from each hand
- 6 pose key points from each arm
- 76 from the face (lips, nose, eyes)
In other words, the output of the MediaPipe framework (holistic model), the hand, face, and pose landmarks are being used as input to the very complex problem of sign language.
The Datasets
The datasets for these competitions are now public on the Kaggle platform.
Kaggle datasets can be directly downloaded from the website with a valid user account. Kaggle also provides programming API and access keys that can be used to download datasets programmatically, as follows:
kaggle competitions download -c asl-signs
kaggle competitions download -c asl-fingerspelling
It is important to know the size of the datasets, before you attempt to download them. Make sure you have enough room for the archives and extracted data.
If you do not have enough room the datasets, you can still view the landmarks from a USB camera.
asl-signs
- archive size : 40GB
- extracted size : 57GB
- link : https://www.kaggle.com/competitions/asl-signs/data
asl-fingerspelling
- archive size : 170GB
- extracted size : 190GB
- link : https://www.kaggle.com/competitions/asl-fingerspelling/data
landmarks
The two datasets do not contain any images or video, but rather landmarks captured with the MediaPipe models. There is a total of 543 landmarks for each sample, including:
- face : 468 landmarks
- left hand : 21 landmarks
- right hand : 21 landmarks
- pose : 33 landmarks
When landmarks are absent/missing, they are represented as NaN in the datasets.
Time Lapse of Landmarks
All of the viewers have a time-lapse of the top 130 landmarks.
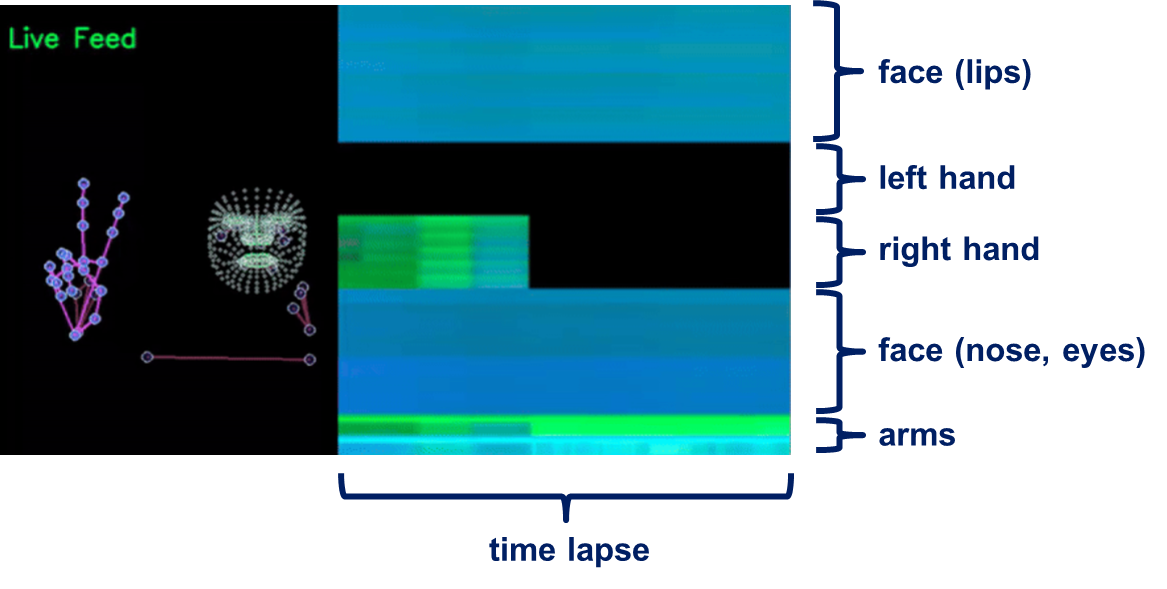 : AlbertaBeef)
: AlbertaBeef)The choice of the 130 landmarks can be tracked down to the winner of the first competition, Hoyeol Sohn (https://www.kaggle.com/hoyso48), and corresponds to the following landmarks:
- face (lips, nose, left eye, right eye) : 76 landmarks
- left hand : 21 landmarks
- right hand : 21 landmarks
- pose (left arm, right arm) : 12 landmarks
The winners of the second competition, Darragh Hanley (https://www.kaggle.com/darraghdog) and Christof Henkel (https://www.kaggle.com/christofhenkel), reused the same choice of 130 landmarks.
I think we can assume that this is a good and relevant selection for analysis and further processing.
Installing the Viewers
The dataset viewers can be accessed from the following github repository:
git clone https://github.com/AlbertaBeef/aslr_exploration
cd aslr_exploration
If not done so already, download the datasets from to the Kaggle website to the “aslr_exploration” directory, or via the Kaggle API, as follows:
kaggle competitions download -c asl-signs
kaggle competitions download -c asl-fingerspelling
Extract the “asl-signs” dataset as follows:
mkdir asl-signs
cd asl-signs
unzip ../asl-signs.zip
cd ..
Extract the “asl-fingerspelling” dataset as follows:
mkdir asl-fingerspelling
cd asl-fingerspelling
unzip ../asl-fingerspelling.zip
cd ..
You are all set !
Viewing the “asl-signs” Dataset
The “asl-signs” dataset contains sequences from various participants for 250 words.
The “asl-signs” dataset is provided in the following format:
train (94,481 total sequences)
- train.csv
- train_landmark_files\[participant_id]\[sequence_id].parquet
The parquet files have the following format:
- frame : int16 (frame number in sequence)
- row_id : string (unique identifer, descriptor)
- type : string (face, pose, left_hand, right_hand)
- landmark_idx : int16
- x/y/z : double
Each sample corresponds to 1,629 rows (543 landmarks * 3) having a common frame value in the parquet file.
The “asl-signs” viewer can be launched as follows:
python3 asl_signs_viewer.py
 : AlbertaBeef)
: AlbertaBeef)Viewing the “asl-fingerspelling” Dataset
The “asl-fingerspelling” dataset contains the sequences for various sentences performed by various participants. These sentences are typically explicitly spelled out (fingerspelling) since they contain numbers, addresses, web URLs, etc…
The “asl-fingerspelling” dataset is provided in the following format:
train (67,213 total sequences)
- train.csv
- train_landmarks\[participant_id]\[sequence_id].parquet
supplemental_metadata (52,958 total sequences)
- supplemental_metadata.csv
- supplemental_landmarks\[participant_id]\[sequence_id].parquet
By default, the viewer will use the train.csv file. Feel free to edit the python script to use the supplemental_metadata.csv instead.
The parquet files have the following format:
- sequence_id : int16 (unique identifier of sequence)
- frame : string (frame number in sequence)
- type : string (face, pose, left_hand, right_hand)
- [x/y/z]_[type]_[landmark_idx] : double (1,629 spatial coordinate columns for the x, y and z coordinates for each of the 543 landmarks, where type is one of face, pose, left_hand, right_hand)
Each sample corresponds to one row in the parquet file.
The “asl-fingerspelling” viewer can be launched as follows:
python3 asl_fingerspelling_viewer.py
 : AlbertaBeef)
: AlbertaBeef)Viewing a “Live Feed”
It may be interesting to view custom data, or capture additional data for your custom applications. The MediaPipe holistic viewer can be used for this purpose.
The “MediaPipe holistic” viewer can be launched as follows:
python3 mediapipe_holistic_viewer.py
 : AlbertaBeef)
: AlbertaBeef)Going Further
For installation instructions for the viewers, refer to my full write-up on Hackster:
I hope that these viewers will inspire you to implement your own custom application.
Acknowledgements
I want to thank Google for making the following available publicly:
- MediaPipe
- asl-signs : ASL Isolated Signs Dataset
- asl-fingerspelling : ASL Fingerspelling Dataset
I also want to thank Kaggle for hosting the competitions and datasets, as well as the following winning Kaggle members for their insight into these datasets:
- Hoyeol Sohn (https://www.kaggle.com/hoyso48)
- Darragh Hanley (https://www.kaggle.com/darraghdog)
- Christof Henkel (https://www.kaggle.com/christofhenkel)
References
- [Kaggle] Isolated Sign Language Recognition : https://www.kaggle.com/competitions/asl-signs/overview
- [Kaggle] Fingerspelling Recognition : https://www.kaggle.com/competitions/asl-fingerspelling
- [AlbertaBeef] aslr_exploration : https://github.com/AlbertaBeef/aslr_exploration
- [Hackster] Insightful Datasets for ASL recognition