



An exploration of accelerating the MediaPipe models with Hailo-8.
Introduction
This project is part of a series on the subject of deploying the MediaPihpe models to the edge on embedded platforms.
If you have not already read part 1 of this series, I urge you to start here:
In this project, I start by giving a recap of the challenges that can be expected when deploying the MediaPipe models, specifically for Hailo-8.
Then I will address these challenges one by one, before deploying the models with the Hailo flow.
Finally, I will perform profiling to determine if our goal of acceleration was achieved.
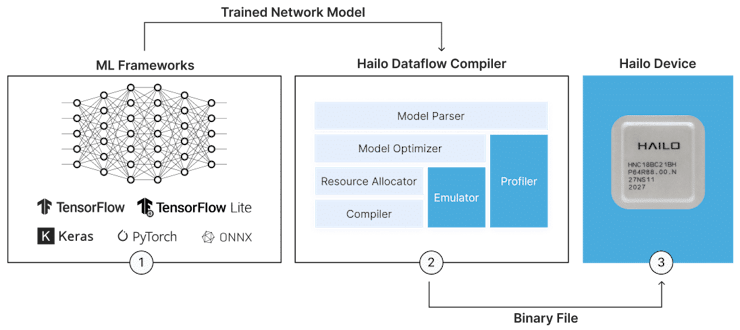
Hailo Flow Overview
Hailo's AI Software Suite allows users to deploy models to the Hailo AI accelerators.
 : Hailo)
: Hailo)In addition to the Hailo AI accelerator devices, Hailo offers a scalable range of PCIe Gen 3.0 compatible M.2 AI accelerator modules:
 : AlbertaBeef)
: AlbertaBeef)No tests have been made with the Hailo-10 AI Acceleration module due to availability. This project will only cover the following Hailo AI acceleration modules:
- Hailo-8 : M.2 M Key (PCIe Gen 3.0, 4 lanes), 26 TOPS
- Hailo-8 : M.2 B+M Key (PCIe Gen 3.0, 2 lanes), 26 TOPS
- Hailo-8L : M.2 B+M Key (PCIe Gen 3.0, 2 lanes), 13 TOPS
The Hailo AI Software Suite supports the following frameworks:
- TensorFlow Lite
- ONNX
Hailo chose TensorFlow Lite, not because of its popular use for “reduced set of instructions and quantized” models, but rather because it is a “more stable” exportable format that also supports full floating-point models.
Other frameworks are indirectly supported by exporting to the TF-Lite or ONNX formats.
The deployment involves the following tasks:
- Model Parsing
- Model Optimization & Resource Allocation
- Model Compilation
The Model Parsing task translates models from industry-standard frameworks to Hailo executable format (HAR). It allows the user to identify unsupported layers, or sequence of layers in the model that are not supported by the compiler. This step is crucial when training our own custom model, since we can adapt the model architecture to use layers that are supported by the target compiler prior to training, thus saving hours (or days) in our deployment flow.
The Model Optimization and Resource Allocation tasks convert the model to the internal representation, using state of the art quantization, then allocates this internal representation to available resources in the Hailo AI accelerator. In order to perform this analysis and conversion, a sub-set of the training dataset is required. The size of the required calibration data is typically in the order of several 1000s of samples.
The Model Compilation task converts the quantized model to micro-code that can be run on the Hailo AI acceleration device.
In this project, we will be using version 2023–10 of the Hailo AI Software Suite Container, which includes:
- Dataflow Compiler : v3.25.0
- Hailo Model Zoo : v2.9.0
- Hailo RT : v4.15.0
- TAPPAS : v3.26.0
More information on versions and compatibility can be found on the Hailo Developer Zone.
A Note about GPUs
It is important to note that a GPU will be used by the Hailo Dataflow Compiler (DFC), specifically for the Model Optimizer task.
In my case, I have the following GPUs in my system:
- AMD GPU Radeon Pro W7900 (45GB) : not supported
- NVIDIA T400 (2GB) : supported
If like me, your GPU does not have enough memory, you will get a message like the following:
hailo_model_optimization.acceleras.utils.acceleras_exceptions.AccelerasResourceError:
GPU memory has been exhausted.
Please try to use Fine Tune with lower batch size or run on CPU.
In this case, it is possible to reduce the batch size from the default 8 down to something less memory intensive, such as 2. Since this may affect quantization accuracy, it is best to use the maximum batch size supported by your GPU for each model.
Challenges of deploying MediaPipe with Hailo-8
The first challenge that I encountered, in part 1, was the reality that the performance of the MediaPipe models significantly degrades when run on embedded platforms, compared to modern computers. This is the reason I am attempting to accelerate the models with the Hailo AI SW Suite.
The second challenge is the fact that Google does not provide the dataset that was used to train the MediaPipe models. Since quantization requires a subset of this training data, this presents us with the challenge of coming up with this data ourselves.
Creating a Calibration Dataset for Quantization
As described previously in the “Hailo Flow Overview” section, the quantization phase requires several hundreds to thousands of data samples, ideally a subset from the training data. Since we do not have access to the training dataset, we need to come up with this data ourselves.
We can generate the calibration dataset using a modified version of the blaze_app_python.py script, as follows:
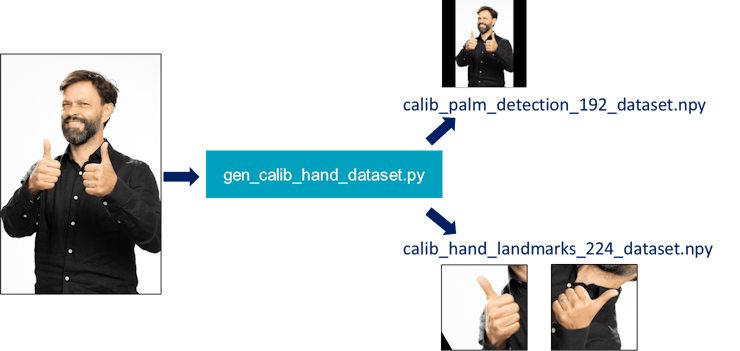 : AlbertaBeef)
: AlbertaBeef)For each input image that contains at least one hand, we want to generate:
- palm detection input images : resized image and padded to model’s input size
- hand landmarks input images : cropped image of each hand, resized to model’s input size
Two possible sources for input images are the following:
- Kaggle : many datasets exist, and may be reused
- Pixabay : contains several interesting videos, from which images can be extracted
For specific examples for these two use cases, refer to my full write-up on Hackster:
If you know of other sources that can be used for the calibration dataset, please share your insight in the comments.
A Deeper Dive into the Palm Detection model
Before we tackle the deployment flow with the Hailo AI SW Suite, it is worth taking a deeper dive into the models we will be working with. For this purpose, I will highlight the architecture of the palm detection model.
At a very high level, there are three convolutional neural network backbones that are used to extract features at three different scales. The outputs of these three backbones are combined together to feed two different heads : classifiers (containing score) and regressors (containing bounding box and additional keypoints).
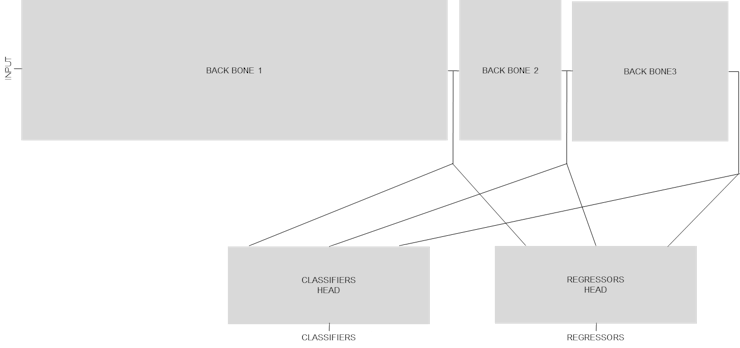 : AlbertaBeef)
: AlbertaBeef)The input to this model is a 256x256 RGB image, while the outputs of the model are 2944 candidate results, each containing:
- score
- bounding box (normalized to pre-determined anchor boxes)
- keypoints (7 keypoints for palm detector)
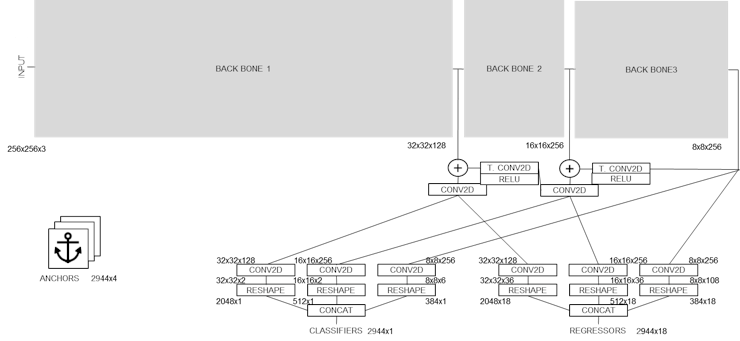 : AlbertaBeef)
: AlbertaBeef)The following block diagram illustrates details of the layers for the model. I have grouped together repeating patterns as “BLAZE BLOCK A”, “BLAZE BLOCK B”, and “BLAZE BLOCK C”, showing the details only for the first occurrence.
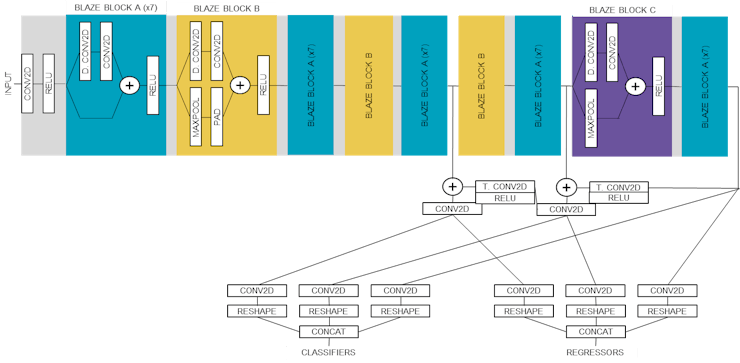 : AlbertaBeef)
: AlbertaBeef)The following block diagram is the same as the previous one, but this time showing details of the “BLAZE BLOCK B” patterns, which will required further discussion during the deployment phase.
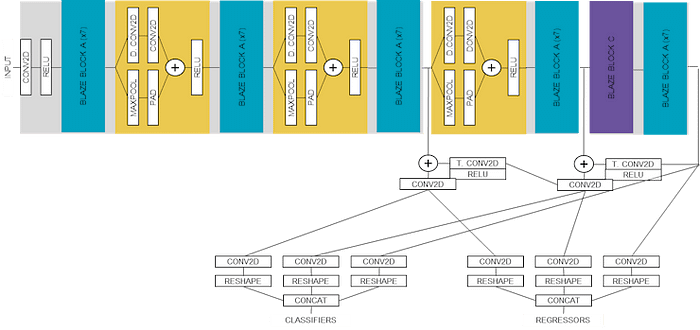 : AlbertaBeef)
: AlbertaBeef)Model Inspection
As we saw previously in the “Hailo Flow Overview” section, the deployment phase starts with an inspection of the model in order to determine if the layers are supported by the Hailo data flow compiler (DFC).
Initial exploration reveals that the final reshape/concatenation layers of the model are not supported. This is reported as shown below for the 0.10 lite version of the palm detection model:
python3 hailo_flow.py --arch hailo8 --name palm_detection_lite --model models/palm_detection_lite.tflite --resolution 192 --process inspect
Command line options:
--arch : hailo8
--blaze : hand
--name : palm_detection_lite
--model : models/palm_detection_lite.tflite
--resolution : 192
--process : inspect
Traceback (most recent call last):
File "hailo_flow.py", line 42, in <module>
hn, npz = runner.translate_tf_model(model_path,model_name)
File "/local/workspace/hailo_virtualenv/lib/python3.8/site-packages/hailo_sdk_common/states/states.py", line 16, in wrapped_func
return func(self, *args, **kwargs)
File "/local/workspace/hailo_virtualenv/lib/python3.8/site-packages/hailo_sdk_client/runner/client_runner.py", line 902, in translate_tf_model
parser.translate_tf_model(model_path=model_path, net_name=net_name, start_node_names=start_node_names,
File "/local/workspace/hailo_virtualenv/lib/python3.8/site-packages/hailo_model_optimization/tools/subprocess_wrapper.py", line 57, in parent_wrapper
raise SubprocessTracebackFailure(*child_messages)
hailo_model_optimization.acceleras.utils.acceleras_exceptions.SubprocessTracebackFailure: Subprocess failed with traceback
Traceback (most recent call last):
File "/local/workspace/hailo_virtualenv/lib/python3.8/site-packages/hailo_model_optimization/tools/subprocess_wrapper.py", line 32, in child_wrapper
func(self, *args, **kwargs)
File "/local/workspace/hailo_virtualenv/lib/python3.8/site-packages/hailo_sdk_client/sdk_backend/parser/parser.py", line 73, in translate_tf_model
return self.parse_model_to_hn(graph, values, net_name, start_node_names, end_node_names, nn_framework)
File "/local/workspace/hailo_virtualenv/lib/python3.8/site-packages/hailo_sdk_client/sdk_backend/parser/parser.py", line 214, in parse_model_to_hn
fuser = HailoNNFuser(converter.convert_model(), valid_net_name, converter.end_node_names)
File "/local/workspace/hailo_virtualenv/lib/python3.8/site-packages/hailo_sdk_client/model_translator/translator.py", line 63, in convert_model
self._create_layers()
File "/local/workspace/hailo_virtualenv/lib/python3.8/site-packages/hailo_sdk_client/model_translator/edge_nn_translator.py", line 26, in _create_layers
self._add_direct_layers()
File "/local/workspace/hailo_virtualenv/lib/python3.8/site-packages/hailo_sdk_client/model_translator/edge_nn_translator.py", line 101, in _add_direct_layers
self._layer_callback_from_vertex(vertex)
File "/local/workspace/hailo_virtualenv/lib/python3.8/site-packages/hailo_sdk_client/model_translator/tflite_translator/tflite_translator.py", line 134, in _layer_callback_from_vertex
layer, consumed_vertices, activation = create_layer_from_vertex(LayerType.concat, vertex)
File "/local/workspace/hailo_virtualenv/lib/python3.8/site-packages/hailo_sdk_client/model_translator/tflite_translator/tflite_layer_creator.py", line 44, in create_layer_from_vertex
return _create_concat_layer(vertex)
File "/local/workspace/hailo_virtualenv/lib/python3.8/site-packages/hailo_sdk_client/model_translator/tflite_translator/tflite_layer_creator.py", line 366, in _create_concat_layer
layer = ConcatLayer.create(vertex.name, vertex.input, output_shapes=vertex.output_shapes, axis=axis)
File "/local/workspace/hailo_virtualenv/lib/python3.8/site-packages/hailo_sdk_common/hailo_nn/hn_layers/concat.py", line 25, in create
layer = super(ConcatLayer, cls).create(original_name, input_vertex_order, output_shapes)
File "/local/workspace/hailo_virtualenv/lib/python3.8/site-packages/hailo_sdk_common/hailo_nn/hn_layers/layer.py", line 88, in create
raise UnsupportedModelError(f'1D form is not supported in layer {original_name} of type '
hailo_sdk_common.hailo_nn.exceptions.UnsupportedModelError: 1D form is not supported in layer Identity_1 of type ConcatLayer.
If we trace this back to our block diagram, these are the final layers of the model, as shown in red below:
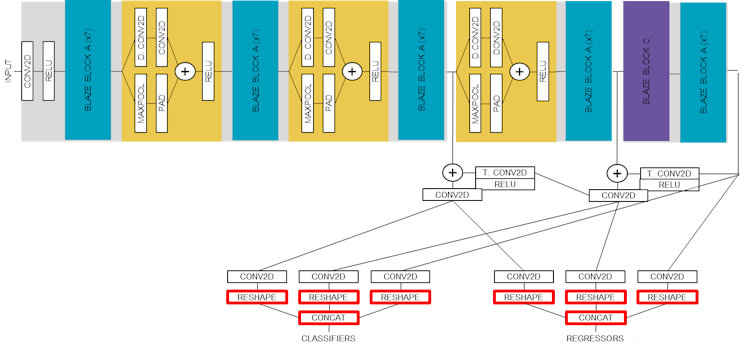 : AlbertaBeef)
: AlbertaBeef)These unsupported layers are in an ideal location (first or last layers), since the bulk of the model can execute entirely on the Hailo-8 acceleration module.
With respect to the Hailo AI SW Suite, this means that we need to specify the last CONV2D layers as output layers, and implement the missing layers in our application. This is shown below for the 0.10 lite version of the palm detection model:
python3 hailo_flow.py --arch hailo8 --name palm_detection_lite --model models/palm_detection_lite.tflite --resolution 192 --process parse
Command line options:
--arch : hailo8
--blaze : hand
--name : palm_detection_lite
--model : models/palm_detection_lite.tflite
--resolution : 192
--process : parse
[INFO] start_node_names : ['input_1']
[INFO] end_node_names : ['model_1/model/classifier_palm_16_NO_PRUNING/BiasAdd;model_1/model/classifier_palm_16_NO_PRUNING/Conv2D;model_1/model/classifier_palm_16_NO_PRUNING/BiasAdd/ReadVariableOp/resource1', 'model_1/model/classifier_palm_8_NO_PRUNING/BiasAdd;model_1/model/classifier_palm_8_NO_PRUNING/Conv2D;model_1/model/classifier_palm_8_NO_PRUNING/BiasAdd/ReadVariableOp/resource1', 'model_1/model/regressor_palm_16_NO_PRUNING/BiasAdd;model_1/model/regressor_palm_16_NO_PRUNING/Conv2D;model_1/model/regressor_palm_16_NO_PRUNING/BiasAdd/ReadVariableOp/resource1', 'model_1/model/regressor_palm_8_NO_PRUNING/BiasAdd;model_1/model/regressor_palm_8_NO_PRUNING/Conv2D;model_1/model/regressor_palm_8_NO_PRUNING/BiasAdd/ReadVariableOp/resource1']
[info] Translation completed on TensorFlow Lite model palm_detection_lite
[info] Initialized runner for palm_detection_lite
[info] Saved HAR to: /local/shared_with_docker/palm_detection_lite_hailo_model.har
I used netron.ai to analyze the model and determine the names of these intermediate layers.
Model Deployment
Now that we know which layers are supported by our models, and know which input and output layers to specify for the Hailo AI SW Suite, we can deploy them with scripting, using the calibration data we have prepared.
I have prepared a script for this purpose:
This script takes four (4) arguments when invoked:
- arch : architecture (ie. hailo8, hailo8l)
- name : BlazePalm, BlazeHandLandmark, etc …
- resolution : input size (ie. 256)
- process : inspect, parse, optimize, compile, all
The name argument indicates which model we are deploying, such as BlazePalm for the palm detector or BlazeHandLandmark for the hand landmark models. The resolution indicates the input size to the model.
These two arguments will determine which calibration dataset to use for the quantization. For example:
- name=BlazePalm, size=192 => calib_palm_detection_192_dataset.npy
- name=BlazeHandLandmark, size=224 => calib_hand_landmark_224_dataset.npy
The process argument indicates which task to run. By default specify “all” to parse, optimize, and compile the model. We saw the inspect task in the previous section when we analyzed our models.
I have provided a second script which will call the hailo_flow.py script to parse, optimize, and compile the models to be deployed:.
You will want to modify the following list before execution:
- model_list : specify which model(s) you want to deploy
Below is a modified version of the script that will deploy the 0.10 versions of the palm detection and hand landmarks models.
# TFLite models
model_palm_detector_v0_07=("palm_detection_v0_07","models/palm_detection_without_custom_op.tflite",256)
model_hand_landmark_v0_07=("hand_landmark_v0_07","models/hand_landmark_v0_07.tflite",256)
model_palm_detector_v0_10_lite=("palm_detection_lite","models/palm_detection_lite.tflite",192)
model_palm_detector_v0_10_full=("palm_detection_full","models/palm_detection_full.tflite",192)
model_hand_landmark_v0_10_lite=("hand_landmark_lite","models/hand_landmark_lite.tflite",224)
model_hand_landmark_v0_10_full=("hand_landmark_full","models/hand_landmark_full.tflite",224)
model_list=(
model_palm_detector_v0_10_lite[@]
model_palm_detector_v0_10_full[@]
model_hand_landmark_v0_10_lite[@]
model_hand_landmark_v0_10_full[@]
)
model_count=${#model_list[@]}
#echo $model_count
# Convert to TensorFlow-Keras
for ((i=0; i<$model_count; i++))
do
model=${!model_list[i]}
model_array=(${model//,/ })
model_name=${model_array[0]}
model_file=${model_array[1]}
input_resolution=${model_array[2]}
echo python3 hailo_flow.py --arch hailo8 --name ${model_name} --model ${model_file} --resolution ${input_resolution} --process all
python3 hailo_flow.py --arch hailo8 --name ${model_name} --model ${model_file} --resolution ${input_resolution} --process all | tee deploy_${model_name}.log
done
This script must be executed in the Hailo AI SW Suite docker container for Pytorch. Launch the docker from the “blaze_tutorial/hailo-8/hailo_ai_sw_suite_docker” directory as follows:
$ ./hailo_ai_sw_suite_docker_run.sh
If you get a message indicating that a container is already running, launch the script with the “ — resume” argument as follows:
$ ./hailo_ai_sw_suite_docker_run.sh --resume
Inside the Hailo AI SW Suite docker, download the TFLite models to the “models” sub-directory, then launch the deploy_models.sh script as follows:
$ cd ../shared_with_docker
$ cd models
$ source ./get_tflite_models.sh
$ ..
$ source ./deploy_models.sh
When complete, the following compiled models will be located in the current directory:
- palm_detection_lite.hef
- palm_detection_full.hef
- hand_landmarks_lite.hef
- hand_landmarks_full.hef
For convenience, I have archived the compiled models for Hailo-8 in the following archive:
- Hailo-8 models : blaze_hailo8_models.zip (compiled with DFC v3.25.0)
- Hailo-8L models : blaze_hailo8l_models.zip (compiled with DFC v3.25.0)
A Note about Context Switching
One thing that is important to highlight with the Hailo flow is that the number of contexts that are used to implement a model will affect its inference performance.
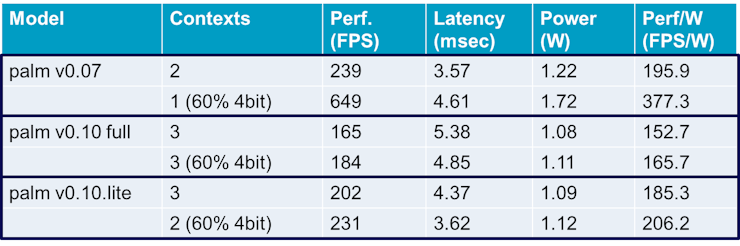
The ideal scenario is that the model can be implemented with a single context. The following table illustrates the significant performance of the 0.10 versions of the hand landmark models (implemented with 1 context), compared to the 0.07 version (implemented with 3 contexts).
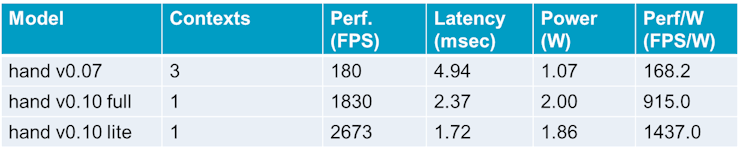 : AlbertaBeef)
: AlbertaBeef)When multiple contexts are required, additional transfers will need to occur over the PCIe bus in order to perform the context switching required to execute the entire model.
It can be worth exploring compression and multiple-precision, with the intent of reducing the number of contexts, in order to improve overall performance.
In my provided hailo_flow.py script, I set the compression parameter auto_4bit_weights_ratio to 0.6 (which means ~60% of the weights will be quantized into 4-bits) and ran the model optimization again. Using 4-bit weights might reduce the model’s accuracy but will help to reduce the model’s memory footprint, possibly reduce the number of contexts, and thus increase performance.
# The following line is needed for really small models, when the compression_level is always reverted back to 0.'
'model_optimization_config(compression_params, auto_4bit_weights_ratio=0.6)\n',
# The application of the compression could be seen by the [info] messages: "Assigning 4bit weight to layer .."
# Increase control utilization to reduce number of contexts
'resources_param(strategy=greedy,max_control_utilization=0.80)\n'
The following table illustrates the significant performance increase achieved with 60% of weights being quantized to 4-bit with the 0.07 version of the palm detection model.
 : AlbertaBeef)
: AlbertaBeef)All this comes at the cost of increased power consumption. If we look at the performance per watt, however, the trade-off is well worth it, since we get more performance per watt for all versions of the palm detection models.
Model Execution
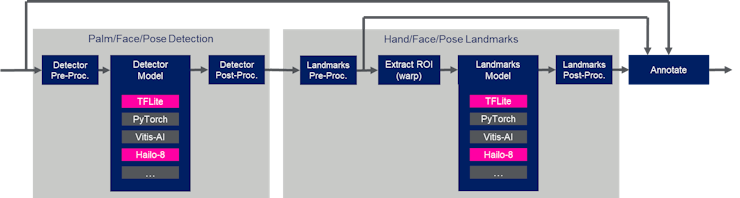
n order to support the Hailo-8 models, the “blaze_app_python” application was augmented with the following inference targets:
 : AlbertaBeef)
: AlbertaBeef)My final inference code for the Hailo-8 models can be found in the “blaze_app_python” repository, under the blaze_hailo sub-directory:
Note that the Hailo-8 inference can be run on a computer (with a M.2 socket, populated with a Hailo-8 module) as well as on the Zynq UltraScale+ embedded platform (ie. ZUBoard, with M.2 HSIO, and Hailo-8 accelerator module).
Launching the python application on ZUBoard
Using the blaze_app_python demo application, we can launch the 0.010 lite version of the model, compiled for Hailo-8, as shown below:
[video]
python3 blaze_detect_live.py — pipeline=hai_hand_v0_10_lite ( : AlbertaBeef)
: AlbertaBeef)
The previous video has not been accelerated. It shows the frame rate to be approximately 19 fps when no hands are detected (one model running : palm detection), approximately 12 fps when one hand has been detected (two models running : palm detection and hand landmarks), and approximately 8 fps when two hands have been detected (three models running : palm detection and 2 hand landmarks).
It is worth noting that this is running with a single-threaded python script. There is an opportunity for increased performance with a multi-threaded implementation. While the graph runner is waiting for transfers from one model’s sub-graphs, another (or several other) model(s) could be launched in parallel …
There is also an opportunity to accelerate the rest of the pipeline with C++ code …
Benchmarking the models on ZUBoard
Using the blaze_app_python demo application, we are able to profile the original TFLite model against the accelerated Hailo-8 implementations.
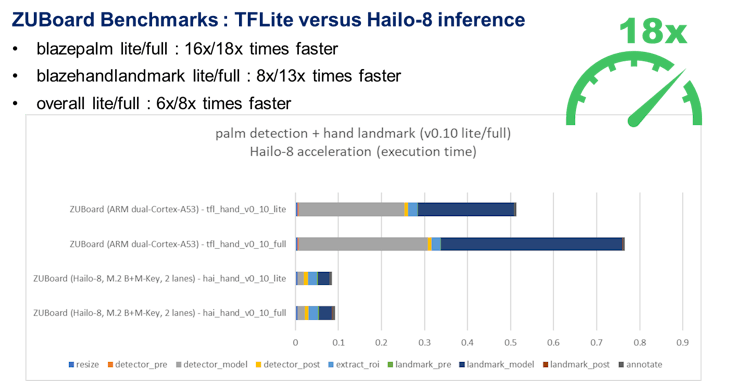
Here are the profiling results for the 0.10 versions of the models deployed with Hailo-8, in comparison to the reference TFLite models:
 : AlbertaBeef)
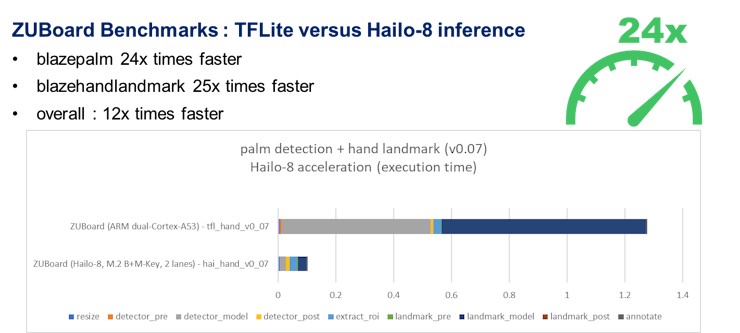
: AlbertaBeef)Here are the profiling results for the 0.07 versions of the models deployed with Hailo-8, in comparison to the reference TFLite models:
 : AlbertaBeef)
: AlbertaBeef)Again, it is worth noting that these benchmarks have been taken with a single-threaded python script. There is additional opportunity for acceleration with a multi-threaded implementation. While the graph runner is waiting for transfers from one model’s sub-graphs, another (or several other) model(s) could be launched in parallel …
There is also an opportunity to accelerate the rest of the pipeline with C++ code …
Setting up the various Hailo-8 platforms
In order to get a better feeling of the acceleration achieved with the Hailo-8 acceleration module, I decided to perform similar profiling for the following platforms:
- Raspberry Pi5 : quad-Cortex-A76 ARM processors / Hailo-8L (B+M, 2 lanes)
- ZUBoard : dual-Cortex-A53 ARM processor / Hailo-8 (B+M Key, 2 lanes)
- ZCU104 : quad-Cortex-A53 ARM processors / Hailo-8 (M Key, 4 lanes)
- HP Z4 G4 Workstation : Intel Xeon (3.6GHz) / Hailo-8 (M Key, 4 lanes)
In order to setup the RPI5, please refer to the following documentation:
My understanding is that the RPI5 Hailo-8L integration was performed with Hailo AI SW Suite v2024-04, with models compiled with DFC v3.27.0. In preparation for this, I have compiled the Hailo-8L models using DFC v3.27.0:
In order to setup the ZUBoard, please refer to the detailed instructions in my previous project:
 : AlbertaBeef)
: AlbertaBeef) : AlbertaBeef)
: AlbertaBeef)In order to setup the UltraZed-EV, I started with the following PCIe enabled design:
- [Github] Avnet/hdl/uz7ev_evcc_nvme
- [Github] Avnet/petalinux/uz7ev_evcc_nvme
I then I added the meta-hailo recipes to the petalinux project, as described in the previous hackster project for ZUBoard, and attached the Hailo-8 module using the Opsero M.2 M-Key Stack FMC:
- [Opsero] M.2 M-key Stack FMC
 : AlbertaBeef)
: AlbertaBeef) : AlbertaBeef)
: AlbertaBeef)In order to setup the HP G4 Z4, I simply inserted the Hailo-8 module into the M.2 socket:
 : AlbertaBeef)
: AlbertaBeef)Benchmarking the models for various Hailo-8 platforms
In order to determine the acceleration achieved on each platform, the reference TFLite models needed to be profiled as well:
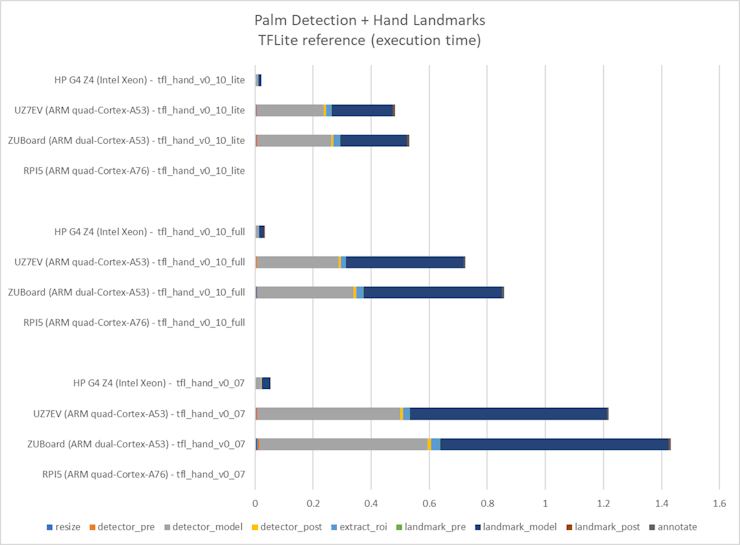 : AlbertaBeef)
: AlbertaBeef)Next, I profiled the 0.07 and 0.10 versions of the models deployed with Hailo-8, and compared with the reference TFLite models:
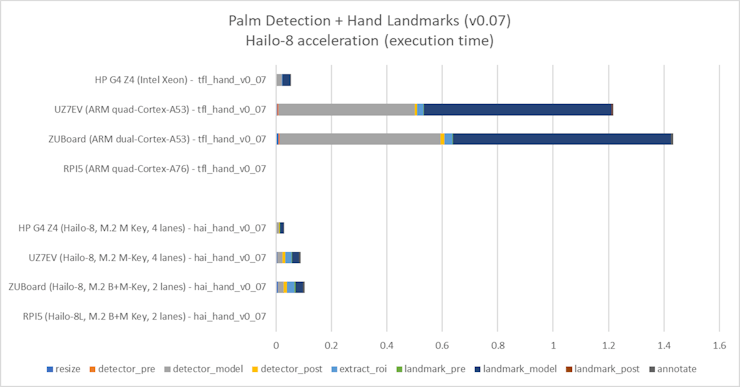 : AlbertaBeef)
: AlbertaBeef)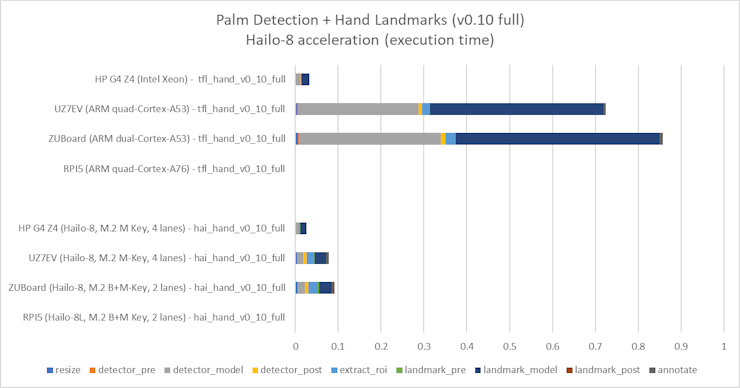 : AlbertaBeef)
: AlbertaBeef)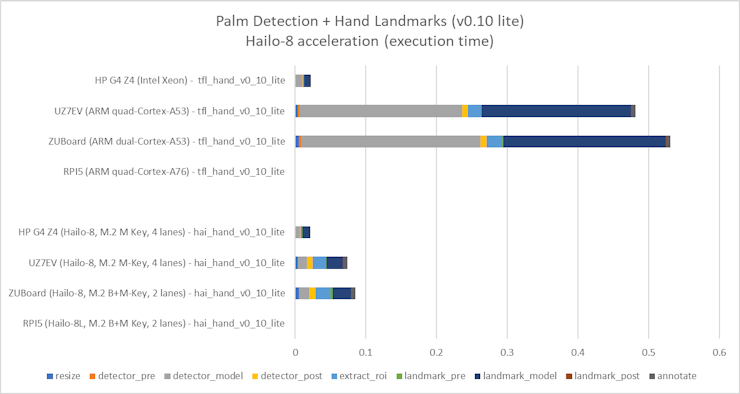 : AlbertaBeef)
: AlbertaBeef)If we plot the execution times for the Hailo-8 models for each platform, we get the following results:
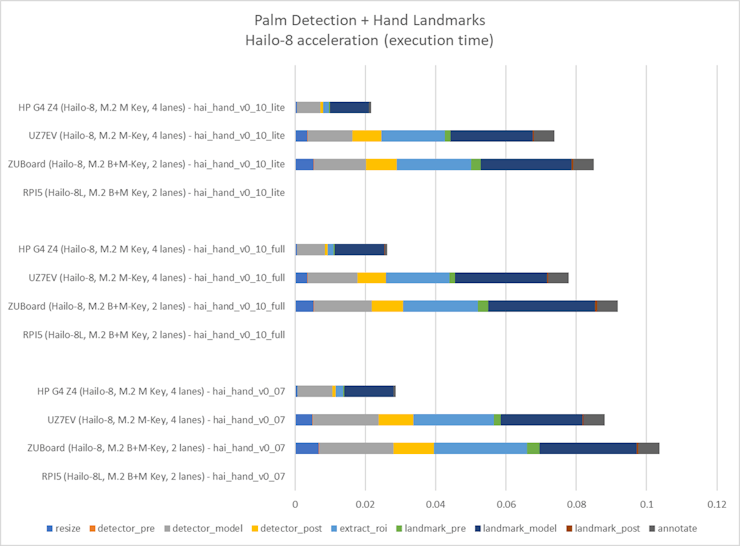 : AlbertaBeef)
: AlbertaBeef)If we analyze these results per platform, we can observe the following acceleration:
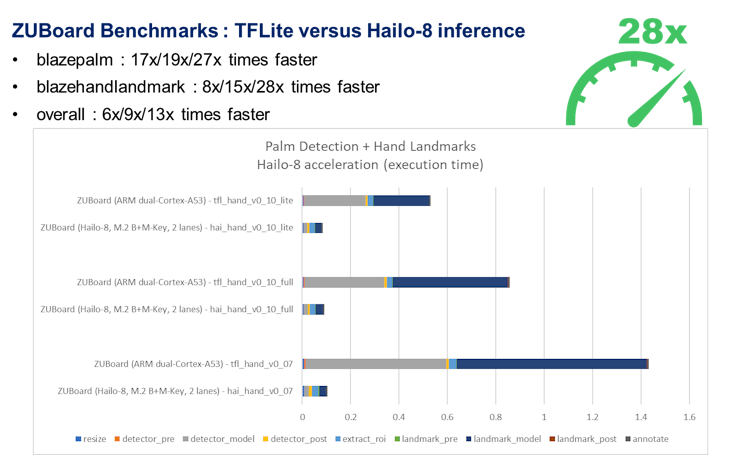 : AlbertaBeef)
: AlbertaBeef)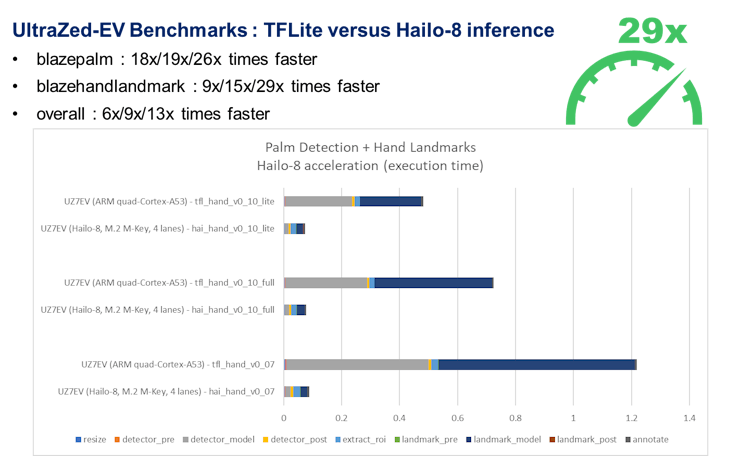 : AlbertaBeef)
: AlbertaBeef)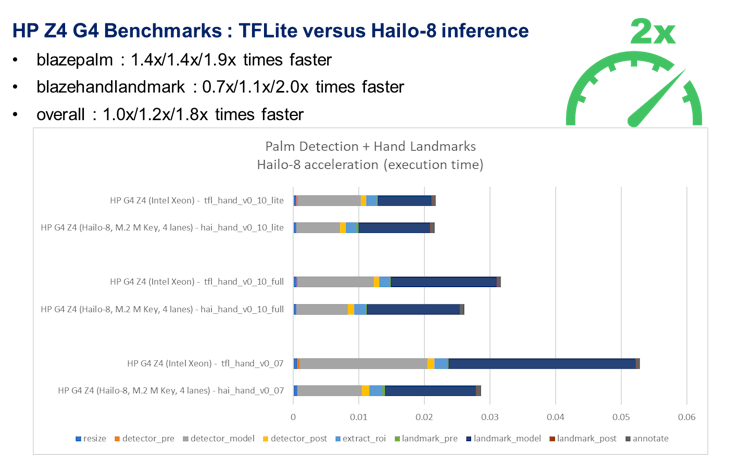 : AlbertaBeef)
: AlbertaBeef)If we plot the acceleration ratios of the execution times for the Hailo-8 models with the most acceleration (versions 0.07), for each platform, we get the following results:
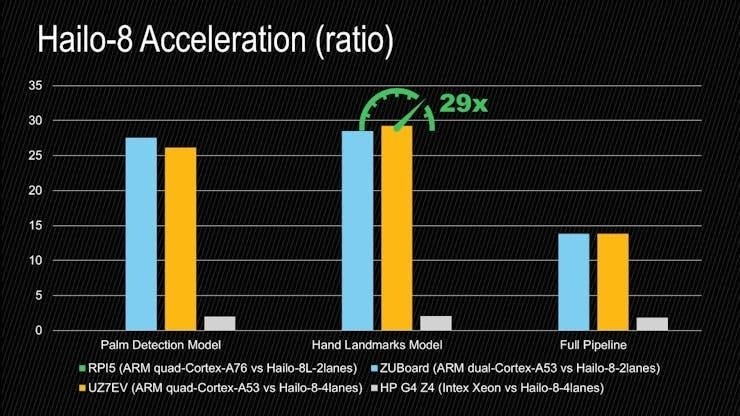 : AlbertaBeef)
: AlbertaBeef)The uncontested winner in terms of performance is the modern workstation (HP G4 Z4). Both of its TFLite and Hailo-8 models have the smallest execution times. If we consider acceleration, however, there is little gain offered by the Hailo-8 acceleration module, since the models are already performing very well on the CPU.
If we consider the acceleration acheived, the Zynq UltraScale+ platforms rise above the others. Specifically on the UltraZed-EV platform, 29X faster for the hand landmarks model.
Going Further
For detailed instructions on deploying the models, and installing the python demo application, refer to my full write-up on Hackster:
I hope this project will inspire you to implement your own custom application.
Since I have not yet received my RPI5 AI Kit, I was not able to generate any profiling results for that platform. If you would like to see benchmarks for the RPI5 AI Kit (with Hailo-8L module), please let me know in the comments …
If you have a RPI5 AI Kit, and would like to test out these accelerated models (and perhaps perform profiling), please le me know in the comments …
Acknowledgements
I want to thank my co-author Gianluca Filippini (EBV) for his pioneering work with the Hailo-8 AI Accelerator module, and bringing this marvel to my attention. His feedback, guidance, and insight have been invaluable.
I also want to thank Jeff Johnson (Opsero) for his M.2 M-Key Stack FMC, which was indispensable for testing the Hailo-8 module on the UltraZed-7EV FMC Carrier Card:
- [Opsero] M.2 M-key Stack FMC
References
- [Google] MediaPipe Solutions Guide : https://ai.google.dev/edge/mediapipe/solutions/guide
- [Hailo] Hailo AI SW Suite Documentation :
https://hailo.ai/products/hailo-software/hailo-ai-software-suite - [Hailo] Hailo Dataflow Compiler (DFC) User Guide, v3.25.0
- [Hailo] Hailo RT User Guide, v4.15.0
- [Hailo] Hailo TAPPAS User Guide v3.26.0
- [Hailo] Hailo Developer Zone : https://hailo.ai/developer-zone
- [Opsero] M.2 M-key Stack FMC
- [AlbertaBeef] blaze_app_python : AlbertaBeef/blaze_app_python
- [AlbertaBeef] blaze_tutorial : AlbertaBeef/blaze_tutorial
- [Hackster] Accelerating the MediaPipe models with Hailo-8
