



Introduction
In this blog post, I'll explore Deep Learning and quantization using the AMD Zynq 7000. I'm focusing on how these techniques can be applied to Computer Vision for my FruitVision Scale project. To do this, I'll use the Zynq 7000 and PYNQ.
Over the past few weeks, I've been testing different PYNQ versions on the Arty Z7, seeing how well Machine Learning and Deep Learning work on this platform. This blog will cover the installation process, system requirements, and what I've discovered from my experiments. To make learning easier, I've included PDFs of Jupyter notebook sessions.

AMD Zynq 7000 SoC and PYNQ
The AMD Zynq 7000 is an APSoC, integrating almost all components of a computer into a single chip while also incorporating FPGA (field-programmable gate array) technology. This powerful SoC combines a dual-core ARM processor with a programmable FPGA fabric.
The image shows a Zynq 7000 on the Digilent Arty Z7 development board.

For all the exercises, I used PYNQ, an open-source project by AMD that simplifies development for these boards with Python and Jupyter notebooks. This combination lets you use both the CPU and FPGA’s capabilities for edge-based machine learning (ML) tasks.
In the image, a Jupyter session with PYNQ and the Arty Z7 is shown.
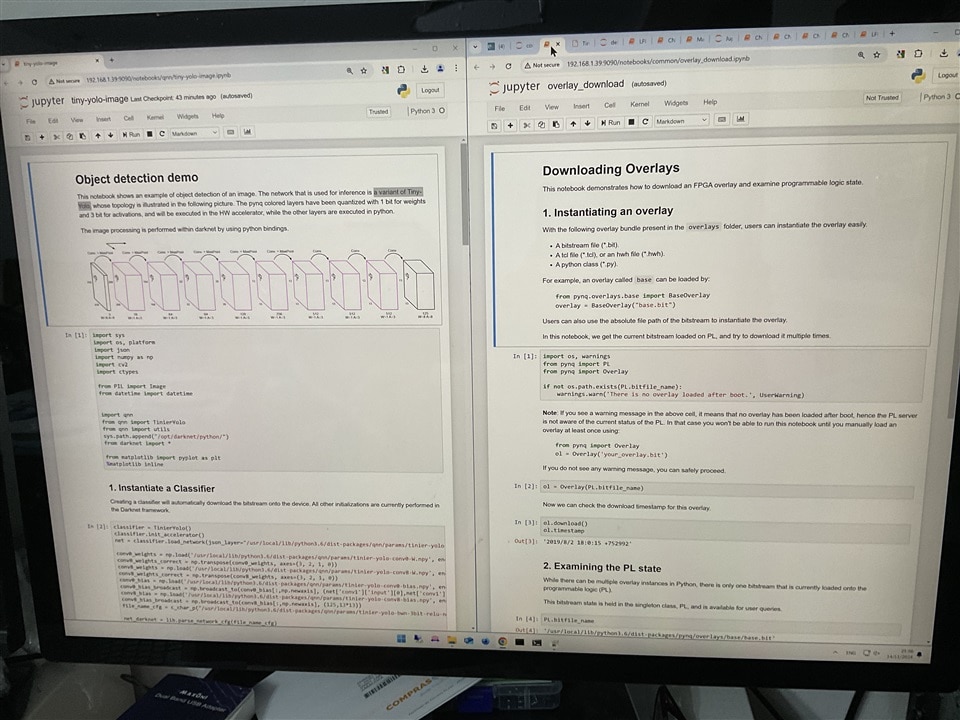
Computer Vision
Computer Vision is all about teaching machines to see and understand the world like we do. It covers a wide range of tasks, from image processing and object classification to image understanding and object tracking. Essentially, it's about using computer algorithms to extract meaningful insights from images.
In the image, you can see object classification running on the Arty Z7 using Quantized Tiny YOLO on FPGA with the Xilinx FINN framework, specifically BNN-PYNQ.

My project, FruitVision Scale, uses computer vision to classify fruits and then weighs them to calculate their price.
Deep Learning, Machine Learning, and Artificial Intelligence
While the terms Deep Learning, Machine Learning, and Artificial Intelligence are often used interchangeably, it’s important to understand their distinctions:
- Artificial Intelligence (AI) involves creating intelligent systems with the goal of achieving artificial general intelligence.
- Machine Learning (ML) is a subset of AI that allows programs to learn and make decisions from data.
- Deep Learning (DL) is a subset of ML that uses artificial neural networks to learn complex patterns from large amounts of data.
Unlike traditional ML algorithms, which rely on human-engineered features, Deep Learning models can learn these features directly from raw data. This makes them particularly well-suited for tasks like image and speech recognition.
Machine Learning: Face detection using Haar Feature-based Cascade Classifiers
The base version of PYNQ for the PYNQ-Z1 and Arty-Z7 boards includes several examples to test face and eye detection using Haar feature-based cascade classifiers. You can find more details about this method in the OpenCV tutorial on face detection here.
https://docs.opencv.org/4.x/d2/d99/tutorial_js_face_detection.html
Object Detection using Haar feature-based cascade classifiers is a highly effective method proposed by Paul Viola and Michael Jones in their 2001 paper, "Rapid Object Detection using a Boosted Cascade of Simple Features." This machine learning approach involves training a cascade function with numerous positive and negative images, which is then used to detect objects in other images.
The next three images were captured by a webcam connected to the Arty Z7 and processed using OpenCV within a Jupyter notebook. Note the false positives that are frequent in this type of detection.
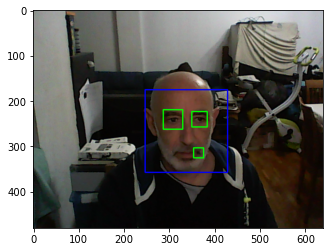

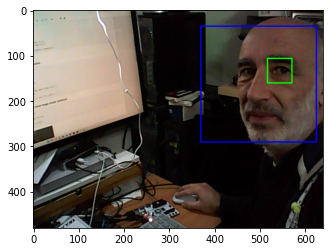
You only need to download the latest version of PYNQ for the PYNQ-Z1 to test this machine learning classifier.
It is relatively easy to create Haar feature-based cascade classifiers for specific objects, in the following two images the classifier has been configured to detect bananas.


Deep Learning
Deep learning uses Artificial Neural Networks (ANNs), which are like interconnected nodes or neurons that process information. These ANNs work like human brains, with each layer learning different features from the data. As data moves through each layer, the network understands more complex patterns, helping it make accurate predictions or decisions. This layered method helps deep learning models handle tasks like recognizing images and speech, understanding language, and more efficiently.
For example, in image recognition, a deep learning model can learn to identify objects by first looking at simple features like edges and textures in the initial layers. Then, it gradually builds up to understanding higher-level concepts like shapes and objects in the deeper layers. This step-by-step learning process helps the model recognize even complex patterns and make accurate predictions.
One of the key components of deep learning models is the concept of weights. These weights are numerical values assigned to the connections between neurons in the neural network. During the training process, the model adjusts these weights to optimize its performance. By modifying the weights, the network can strengthen or weaken the influence of different inputs on the output, enabling it to learn complex patterns and make accurate predictions.
Quantization or reduced precision
Traditionally, neural networks use high-precision 32-bit floating-point numbers for their weights. However, recent research has shown that quantizing these weights to lower precision, such as 8-bit or even 1-bit, can significantly reduce computational costs and memory footprint with minimal impact on accuracy.
The advantages of quantization include:
- Reduced memory footprint: Smaller data types for weights lead to lower memory requirements.
- Enhanced processing efficiency: Lower-precision arithmetic operations are more efficient and consume less power.
- Hardware acceleration: The Zynq 7000’s FPGA can be customized to implement hardware accelerators for quantized neural networks.
YOLOv3 Detection Compared to the Quantized Version
By quantizing the weights, we gain speed and efficiency in processing and reduce the memory footprint at the cost of some precision. As seen in the following example, the image on the left shows the output of a model with 32-bit precision weights, while the image on the right shows the output of a reduced model with significantly quantized weights.
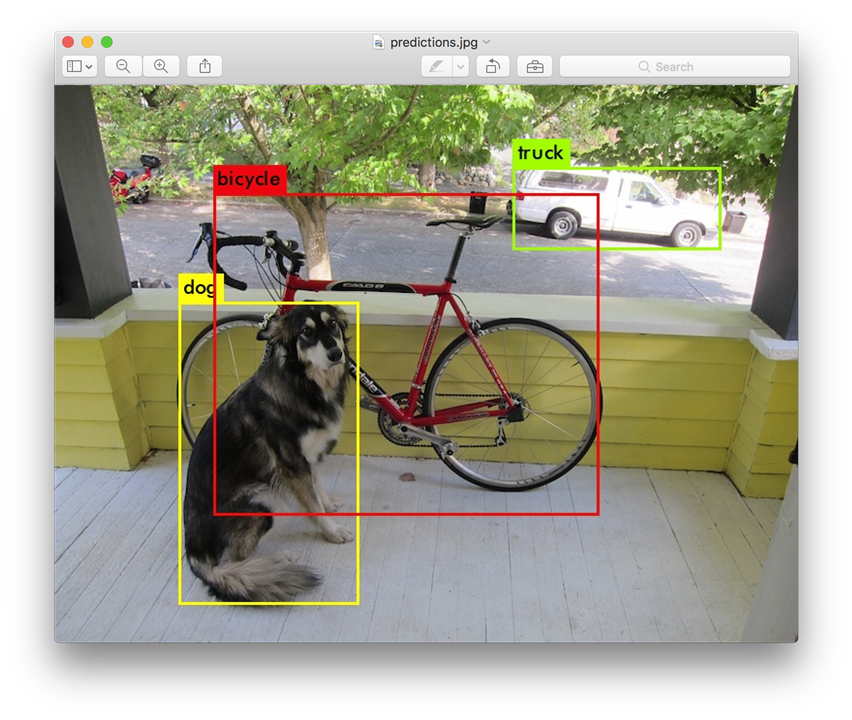
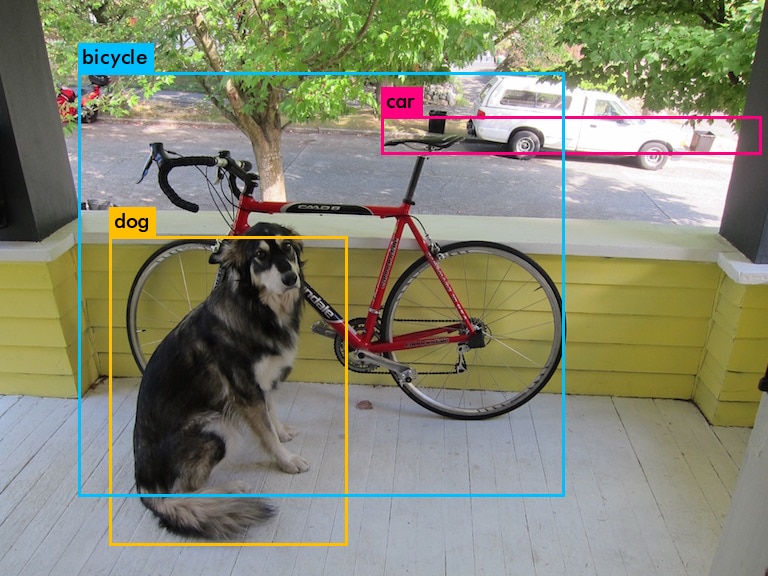
The image on the left shows the output of a model with 32-bit precision weights. The model accurately identifies and labels the objects in the image, including a bicycle, a dog, and a truck. The bounding boxes are precise and the labels are correctly assigned.
The image on the right, processed on the Arty Z7, shows the output of a reduced model with significantly quantized weights. While the model still identifies the objects, the bounding boxes are less precise and the labels are slightly off. This indicates that quantization has resulted in some loss of accuracy, but the model is still able to perform the task reasonably well.
This example demonstrates the trade-off between accuracy and efficiency in deep learning. Quantization can be a useful tool for reducing model size and increasing inference speed, but it may come at the cost of some accuracy. The choice of whether to use quantization depends on the specific requirements of the application.
Prebuilt PYNQ Hardware Overlays
PYNQ hardware overlays are pre-designed hardware blocks that can be loaded onto the FPGA fabric of a Zynq SoC to accelerate specific tasks. They are designed and implemented in hardware description languages like Verilog or VHDL, and then compiled into a bitstream that can be loaded onto the FPGA. PYNQ simplifies the process of working with these overlays by providing a Python-based interface, allowing users to interact with the hardware accelerators using familiar Python programming techniques.
AMD provides pre-built hardware overlays for the Zynq 7000 to accelerate quantized neural networks. These overlays fall into two categories:
- Binarized Neural Networks (BNN): Extreme quantization where weights are represented by a single bit.
- Quantized Neural Networks (QNN): More flexible quantization with variable bit widths for weights.
Overlay Architectures
The overlays can be implemented using different architectures:
- Feed-forward Dataflow: All the network's layers are built into the hardware. As soon as one layer finishes processing, its output immediately becomes the input for the next layer. The parameters for all layers are stored in the on-chip memory. Each network layout gets a custom hardware setup, which ensures low latency and high throughput.
- Multi-layer Offload: This involves using a fixed hardware setup that can handle multiple layers in one go. The entire network runs through several calls, all scheduled on the same hardware. If you change the network's layout, you only need to adjust the scheduling, not the hardware. This method is flexible but can result in slightly higher latency.
Quantized Tiny-YOLO Architecture for Efficient Inference
The image below showcases a variant of the Tiny-YOLO architecture that uses quantization and hardware acceleration to boost efficiency and cut down computational costs.
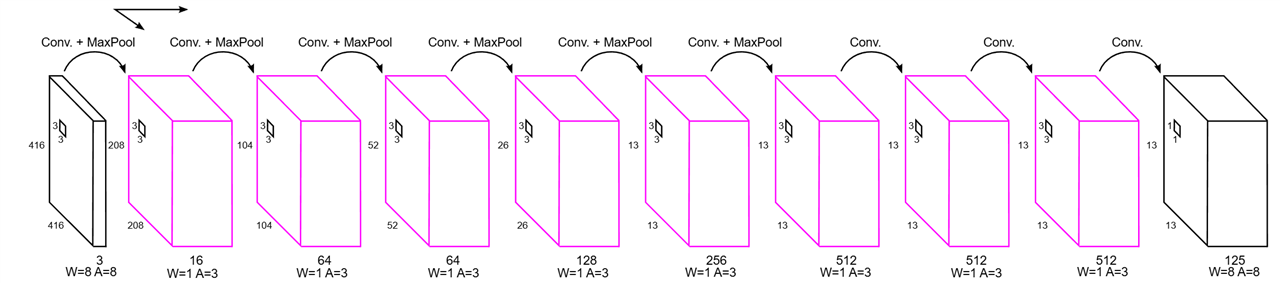
This neural network architecture highlights specific layers (in pink) that have been quantized. Quantization here means lowering the precision of the weights and activations within these layers. Specifically, the weights are reduced to 1 bit, and the activations to 3 bits.
By quantizing these layers, the model runs more efficiently on hardware accelerators. These accelerators are specialized devices designed for specific computations, like matrix multiplications, which are common in neural networks. Offloading the quantized layers to the hardware accelerator significantly speeds up the overall computation time of the model.
Machine Learning on PYNQ
For reference, here is a copy of the PDF included in the PYNQ image. The document provides an overview of the potential applications of Machine Learning on the PYNQ framework..
AMD Zynq Deep Learning Resources
These are the main Deep Learning resources for the Zynq 7000 I've found:
- https://github.com/Xilinx/BNN-PYNQ : Quantized Neural Network (QNN) on PYNQ
- https://github.com/Xilinx/QNN-MO-PYNQ : Quantized Neural Network (QNN) on PYNQ using a Multi-Layer Offload (MO) architecture
- https://github.com/Xilinx/finn : Fast, Scalable Quantized Neural Network Inference on FPGAs
- https://github.com/Xilinx/finn-examples : Finn Dataflow Accelerator Examples for PYNQ on Zynq and Alveo
BNN-PYNQ
BNN-PYNQ is a framework that allows you to implement and deploy Binary Neural Networks (BNNs) on PYNQ. It provides pre-trained models and optimized algorithms for various tasks, such as image classification and object detection. You can found it here:
https://github.com/Xilinx/BNN-PYNQ
BNNs are a type of neural network that uses binary weights for improved efficiency and faster inference on hardware platforms like FPGAs. BNNs significantly reduce model complexity and computational cost by binarizing weights and activations to 1-bit precision. They use custom hardware accelerators implemented on the FPGA to perform efficient binary operations. This produces extremely low-precision models with a significant reduction in hardware resource utilization and potential for very high inference speeds. However, it has its limitations: reduced model accuracy compared to higher-precision models and restrictions to specific network architectures and data types.
QNN-MO-PYNQ
This repository introduces the Quantized Neural Network Model Optimizer for PYNQ (QNN-MO-PYNQ). The core concept of QNN-MO-PYNQ involves utilizing Quantized Neural Networks (QNNs) to reduce model size and computational cost without sacrificing significant accuracy. It allows for flexible quantization of weights and activations to different bit widths (e.g., 2-bit, 4-bit, 8-bit) and leverages the FPGA to accelerate the execution of quantized operations. This approach provides a better balance between accuracy and efficiency compared to BNNs, supports a wider range of network architectures and data types, and offers more flexibility in quantization schemes.
You can find it here:
https://github.com/Xilinx/QNN-MO-PYNQ
However, QNN-MO-PYNQ does come with its own set of limitations. While it provides enhanced flexibility and a better accuracy-efficiency tradeoff, it requires increased hardware resource utilization compared to BNNs. Despite this, its capability to support diverse architectures and flexible quantization makes it a strong option for edge ML tasks using the Zynq 7000 platform.
FINN
BNN-PYNQ has been archived and is no longer actively maintained. Therefore, it is recommended to switch to the FINN compiler. In this blog, I've introduced BNN-PYNQ and QNN-PYNQ because they effectively supported specific models for the Zynq 7000.
FINN is an experimental framework developed by AMD's Integrated Communications and AI Lab. It focuses on deep neural network inference on FPGAs, specifically targeting quantized neural networks. FINN emphasizes creating customized dataflow-style architectures for each network, resulting in highly efficient FPGA accelerators that provide high throughput and low latency. The framework is fully open-source, offering flexibility and enabling neural network research across multiple layers of the software/hardware abstraction stack.
https://github.com/xilinx/finn
Installing QNN-MO-PYNQ
First, make sure you have PYNQ version 2.3, 2.4, or 2.5 installed on your Arty-Z7 board. Now, you have two ways to install QNN-MO-PYNQ. The first method is through the serial or SSH console. Connect to your Arty-Z7 board using either a serial console or SSH. Then, clone the QNN-MO-PYNQ repository by running the command:
git clone https://github.com/Xilinx/QNN-MO-PYNQ.git
The second method is using a Jupyter Notebook. Open a Jupyter Notebook on your PYNQ board and install the QNN-MO-PYNQ package by running
!pip install git+https://github.com/Xilinx/QNN-MO-PYNQ.git
This method is pretty straightforward since the Jupyter server already has the environment set up. The image shows the installation process using a Jupyter Notebook.
After installation, a new QNN directory is created. It contains Jupyter Notebook files (.ipynb), image files (.png, .svg), text-based files (.pkl, .txt), and folders for specific datasets such as ImageNet and YOLO.
Imagenet/DoReFaNet classification
This notebook shows an example of ImageNet classification. This notebook shows how to classify an image choosen by the user, while dorefanet-imagenet-samples runs the classification on labeled images (extracted from the dataset)
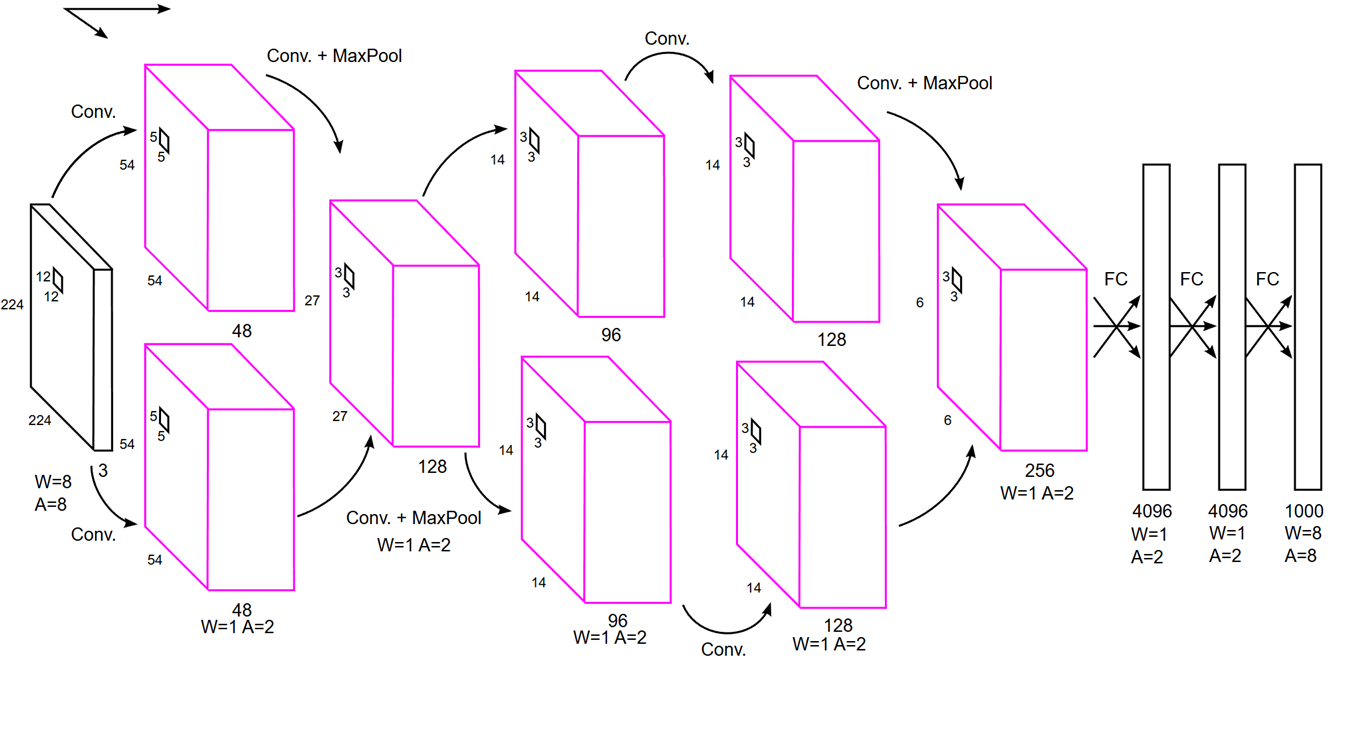
Imagenet topology
The following picture shows the topology of this hardware accelerated Imagenet classifier. The pink layers are executed in the Programmable Logic at reduced precision (1 bit for weights, 2 bit for activations) while the other layers are executed in python.
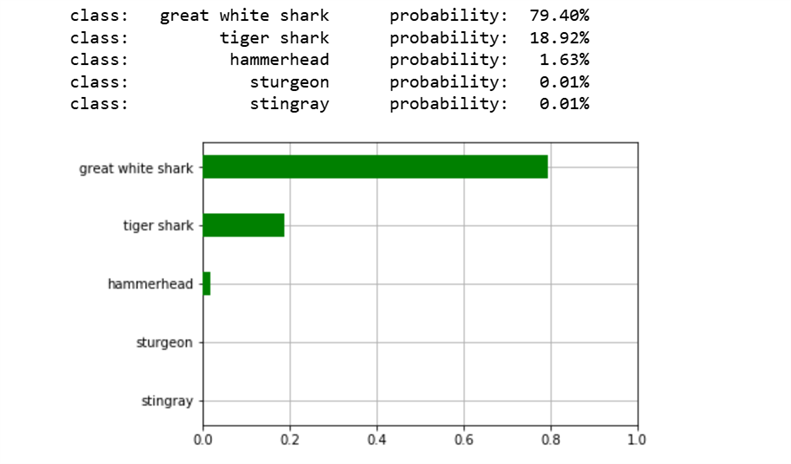
Some examples of imagenet classifications



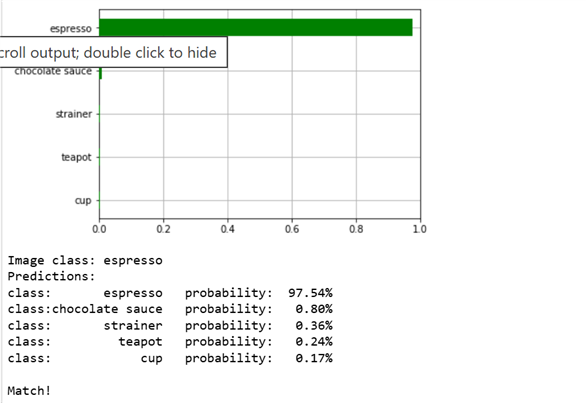
Tiny Yolo Image
YOLO stands for “You Only Look Once.” It’s a real-time object detection system that processes an entire image in one go, rather than looking at small parts of the image one at a time. Imagine you’re trying to find your cat in a photo. With traditional methods, you’d start by looking in one specific spot, maybe the center of the photo. If you don’t see your cat there, you’d move to another spot, like the top left corner, then the bottom right, and so on. You’d keep doing this for different sizes, looking for a tiny cat, a medium-sized cat, or a large cat. This is how traditional detection systems work—they look at small parts of the image at a time and try to decide if there’s a cat there.
With the YOLO (You Only Look Once) approach, you look at the whole picture at once. Instead of focusing on small pieces, you check out the entire photo. Then, you imagine the photo is divided into a grid of squares. For each square, you guess where the cat is and how likely it is to be there. The model guesses if there’s a cat in each square and, if so, where the cat is located. It also tells you how confident it is about its guess. Finally, you combine all the guesses from each square to get the final answer. It’s like having a bird’s-eye view of the photo, rather than looking at it piece by piece.
YOLO: Real-Time Object Detection
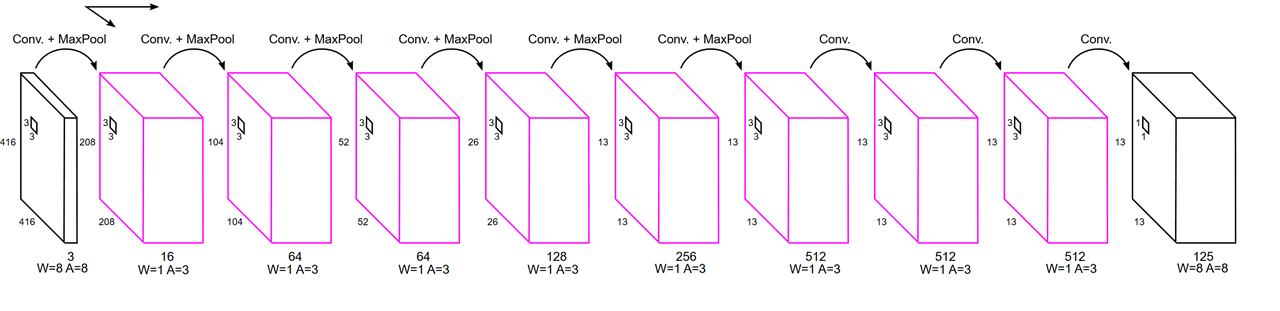
This notebook shows an example of object detection of an image. The network that is used for inference is a variant of Tiny-Yolo, whose topology is illustrated in the following picture. The pink colored layers have been quantized with 1 bit for weights and 3 bit for activations, and will be executed in the HW accelerator, while the other layers are executed in python.
The image processing is performed within darknet by using python bindings.
The following images illustrate the impact of quantization and hardware acceleration on object classification accuracy. The first image shows results using a quantized neural network with hardware acceleration, while the second image doesn't use quantization. As expected, the purely quantized model experiences a slight accuracy reduction.
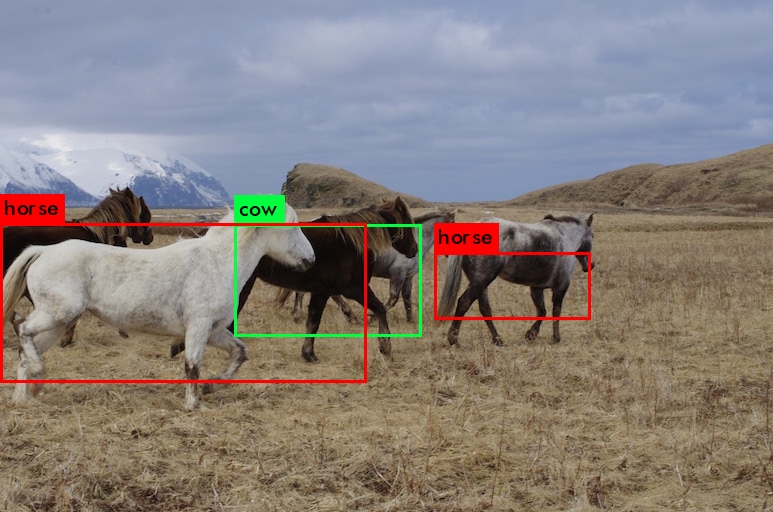
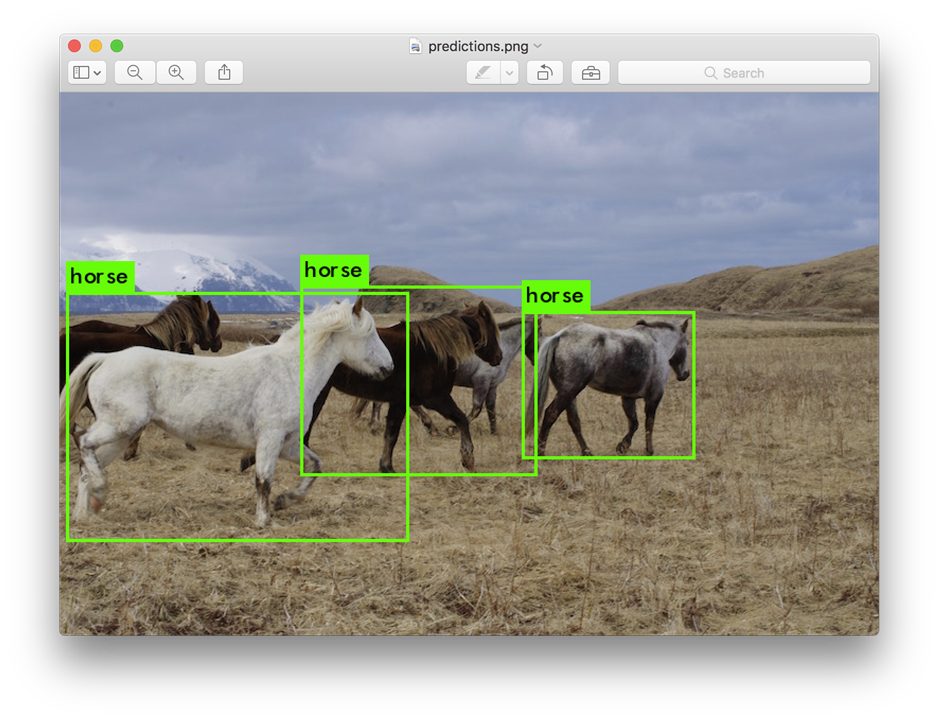
Installing BNN-PYNQ
BNN-PYNQ is a framework that enables you to implement and deploy Binary Neural Networks (BNNs) on PYNQ. It offers pre-trained models and optimized algorithms for tasks like image classification and object detection.
To install:
sudo pip3 install git+https://github.com/Xilinx/BNN-PYNQ.git
Ciphar10 with CNV
The first example we are going to review is a classification on a typical reference dataset, the CIFAR10. The CIFAR10 dataset includes 10 classes of image: 'Airplane', 'Automobile', 'Bird', 'Cat', 'Deer', 'Dog', 'Frog', 'Horse', 'Ship', 'Truck'.
Later when we review the experimental FINN framework we will return to this example in an updated version, using the FINN compiler.
We can choose between hardware accelerated or pure software inference and two versions of hardware accelerators: 'cnv_w1a1_cifar10' and 'cnv_w1a2_cifar1 0'
Handwritten Recognition using BNN on Pynq
This notebook demonstrates how to utilize Binary Neural Networks (BNNs) on a PYNQ board for handwritten digit recognition. It presents a specific example involving a binarized neural network architecture composed of four fully connected layers, each containing 1024 neurons. This network was trained on the MNIST dataset of handwritten digits.

To replicate this notebook, you'll need an external USB camera connected to your Arty Z7 board.
Capturing a Handwritten Digit with the Webcam


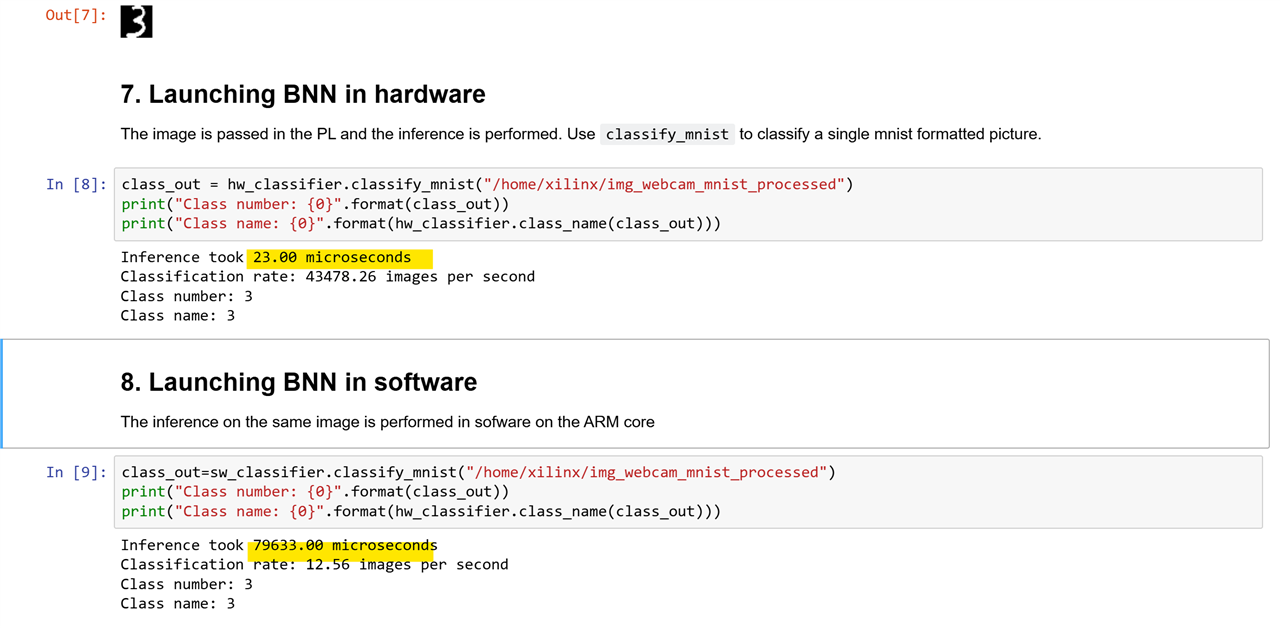
FINN Examples
This repository offers a collection of example projects showcasing the capabilities of the FINN (Xilinx AI Engine) framework. FINN is a comprehensive toolset for deploying deep learning models onto various hardware platforms, including FPGAs.
https://github.com/Xilinx/finn-examples
FINN is an experimental framework from Integrated Communications and AI Lab of AMD Research & Advanced Development to explore deep neural network inference on FPGAs. It specifically targets quantized neural networks, with emphasis on generating dataflow-style architectures customized for each network.
Please note that the ImageNet with CNNs, Binarycop mask detection, and Radio ML with CNNs examples are not currently supported on the PYNQ-Z1 platform.
Mnist With Fully Connected Networks
Again an example against the MINST dataset. MNIST stands for Modified National Institute of Standards and Technology database. It is a large database of handwritten digits, commonly used for training various image processing systems.
The dataset contains 70,000 images of handwritten digits, each 28x28 pixels in size. It is divided into a training set of 60,000 images and a test set of 10,000 images.
The MNIST dataset is a popular benchmark for testing image classification algorithms. While Convolutional Neural Networks (CNNs) are often the go-to choice for image tasks, Fully Connected Networks (FCNs) can also be used, especially for smaller datasets like MNIST.
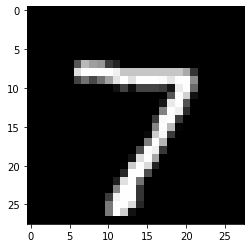
Ciphar10 with CNV Networks
CIFAR-10 is a popular dataset for image classification tasks. It consists of 60,000 32x32 color images, divided into 10 classes, with 6,000 images per class. The 10 different classes represent various objects like airplanes, automobiles, birds, cats, deer, dogs, frogs, horses, ships, and trucks.

CNV is a type of neural network designed to recognize images. It works by looking at small parts of an image and gradually building up a bigger understanding of what's in the whole picture.
This network has a specific structure: it uses three sets of layers, each one getting more complex. Each set consists of three layers:
- Convolutional layer: This layer looks for patterns in small parts of the image.
- Convolutional layer: This layer combines the patterns found in the previous layer to form more complex patterns.
- Max pooling layer: This layer reduces the size of the image while keeping the important information.
The first set of layers uses 64 filters to find simple patterns, the second set uses 128 filters for more complex patterns, and the third set uses 256 filters for even more complex patterns.
After these three sets of layers, there are two fully connected layers with 512 neurons each. These layers help the network make a final decision about what the image shows.
Keyword spotting
The keyword spotting (KWS) network was trained on the Google Speech Commands v2 dataset to detect specific keywords. Audio waveforms were transformed into visual representations using Mel-Frequency Cepstral Coefficients (MFCCs) and processed with the python_speech_features library. The training and validation datasets were pre-processed and quantized to 8 bits for efficient network training. The next step involves loading this pre-processed validation dataset for further analysis.
The technique called Mel Frequency Cepstral Coefficients or MFCC for short turns audio waveforms into 2D images with one channel:
More Examples from the FINN Examples Repository
Traffic Sign Recognition and Cybersecurity with MLPs:
Traffic sign recognition
Deep Learning accelerator for traffic sign recognition using the GTSRB dataset. GTSRB stands for German Traffic Sign Recognition Benchmark. It's a dataset containing images of German traffic signs, categorized into 43 different classes. This dataset is commonly used for training and testing machine learning models, particularly those for image classification and object detection tasks.

Cybersecurity With MLP
This example uses a FINN accelerator for anomaly detection on the UNSW-NB15 dataset. UNSW-NB15 is a comprehensive network intrusion detection dataset designed to evaluate the performance of intrusion detection systems (IDS). It was created by the Australian Centre for Cyber Security (ACCS) at the University of New South Wales (UNSW).
The dataset includes nine different types of attacks, such as DoS, worms, backdoors, and fuzzers, along with normal network traffic.
It is considered a valuable resource for researchers and practitioners in the field of cybersecurity, as it provides a realistic and diverse set of network traffic patterns for training and testing IDS models.
MLP (Multilayer Perceptron) is a type of artificial neural network used for supervised learning tasks like classification and regression. It consists of multiple layers of interconnected nodes, including an input layer, one or more hidden layers, and an output layer. Each node in a layer is connected to every node in the next layer, allowing the network to learn complex patterns in data.
Summary
By using the AMD Zynq 7000 and the PYNQ framework, we explored how quantized neural networks can make Deep Learning and Computer Vision tasks more efficient. We looked into how using techniques like quantization and hardware acceleration with FPGA overlays can improve image classification and object detection performance. This method not only boosts performance but also cuts down on computational costs, making it great for devices with limited resources and real-time applications.
References
- https://github.com/Xilinx/BNN-PYNQ
- https://github.com/Xilinx/finn-examples
- Xilinx/finn-examples at v0.0.5 (github.com)
FruitVision Scale Blogs Series
- Blog 1 - FruitVision Scale - Digilent Arty Z7 - AMD Zynq-7000 - Overview
- Blog 2 - FruitVision Scale - PYNQ on the Digilent Arty Z7 - Quickstart
- Blog 3 - FruitVision Scale - Weighing strategies with load cells using the Digilent Arty Z7
- Blog 4 - FruitVision Scale - FPGA-Based HX711 Driver for Precision Weighing with AMD PYNQ
- Blog 5 - FruitVision Scale - Exploring Deep Learning Applications with AMD Zynq 7000
- Final - FruitVision Scale
