


Register pushing and the pipeline cut
It should be clear by now that a direct implementation of the DSP algorithm is not good enough. Every single individual computation block, the adders and the multipliers, will require pipeline registers and there are simply none available. If we had these registers already available in the design, we could move them around to where we actually need them, a process called re-timing, or more informally, register pushing. There are several re-timing transformations that can be applied to a design. They will change the number and position of registers but will not affect the functionality in any way. Here are a few examples:
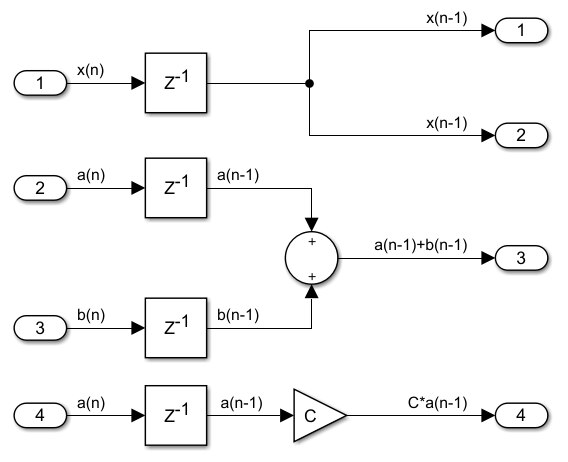
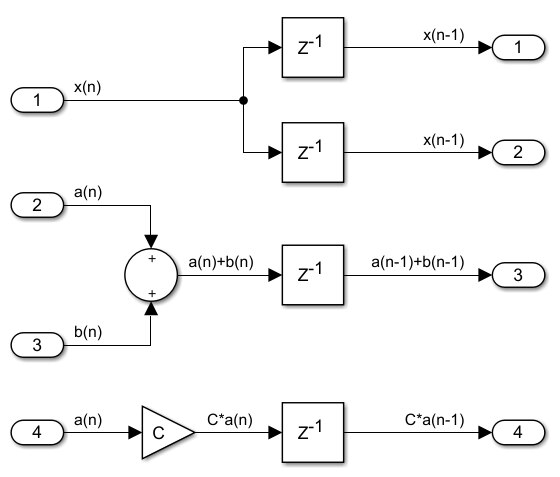
On the left we can see examples of circuits before the re-timing transformation, and on the right what the circuit becomes after the transformation. The operation is reversible and we can very well apply it in the opposite direction. We say we can push a register delay through a multiplier, or through an adder, even through a fork. In the last two cases the number of registers before and after will change, if we push a register through a fork the register will have to split. If we want to push registers through a join, like a 2-input adder, two registers on the two incoming branches will have to merge. If there is no register available on one branch, we cannot push the register on the other branch through the adder. These are examples of pushing one register, but we can also do this with delays of two or more register levels.
So if a particular adder or multiplier lacks its own output register, which is essential if we care about speed, and there are registers available elsewhere in the design, we can push them through adders, multipliers and forks and bring them in the position needed to pipeline these combinatorial blocks. Let's look again at the 5-tap FIR example we have used a few posts ago:
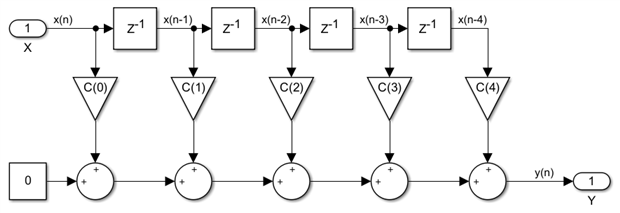
We can see here the need for one pipeline level after each 2-input adder, as well as two pipeline levels for each multiplier. None of these registers exist in the design right now. While we have a method to push registers to re-time the circuit, there is nothing to push yet. We need a method for adding pipeline registers to an existing design, and that is what a pipeline cut will help us do.
It is important to understand that while re-timing does not change the functionality of the design, using the pipeline cut will change the design. But if done properly using the three rules we will see below, the changes will affect only the design latency and not its core functionality. The design outputs will be exactly the same, they will simply arrive one or more clocks later.
A pipeline cut is a line that cuts through the entire design, and this is rule number one, you cannot make a local cut, the line should divide the design in two parts, with the input on one side and the output on the other side. Rule number two says that if you insert one or more delays on every net that you cut and you add exactly the same number of delays on each such net, the functionality of the design does not change, only its latency increases by the number of delays you add. The following image shows several possible pipeline cuts applied to the 5-tap FIR example we have used earlier:
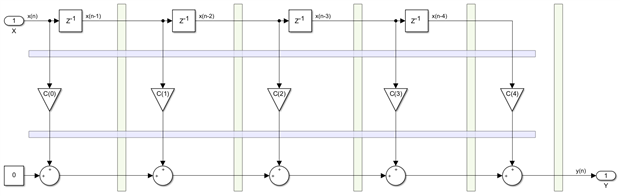
There are actually two types of cuts we can see here, transversal and longitudinal ones. We need the five transversal cuts to add a pipeline register after each adder. These will increase the filter latency by N clocks, where N is the filter order or number of taps, 5 in this example. We need the two longitudinal cuts to pipeline the multipliers and they will increase the latency by two clocks, irrespective of the value for N. The cutting lines must extend all the way so they intersect the entire design, we cannot have nets going around the cut. There should be no paths from input to output that would not go through the cutting line. We will add one pipeline register for each one of these cuts. Alternatively, you can say we do just one longitudinal pipeline cut, we add two registers to any net crossing it and then we push one of each pair of registers through the multipliers to have them pipelined properly. After all these operations, our design now looks like this:

To recap everything we have done here, we started with a very general mathematical formula for a single rate, non-symmetric FIR:
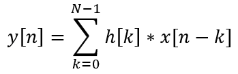
It was trivial to express it as a hardware design using the three fundamental DSP building blocks, adders, multipliers and delays:

The generic N-input adder is not something we would want to have in a scalable hardware implementation so we used the associativity property of addition to come up with a truly generic solution, one where we have a single tap module that we instantiate and cascade N times to build an FIR of any size:
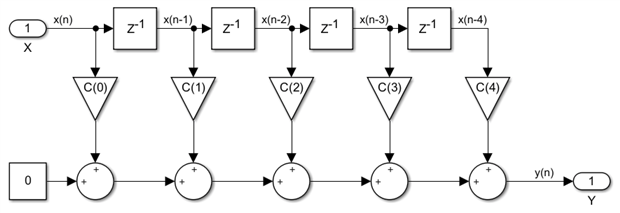
This design is now generic but not scalable, its maximum speed is inversely proportional to the filter order N. Using the pipeline cut rules, we can add more registers to the design until we arrive at the ultimate solution, one which is both generic and scalable. A non-symmetric, single rate, systolic FIR of order N can be built by cascading this basic module N times:
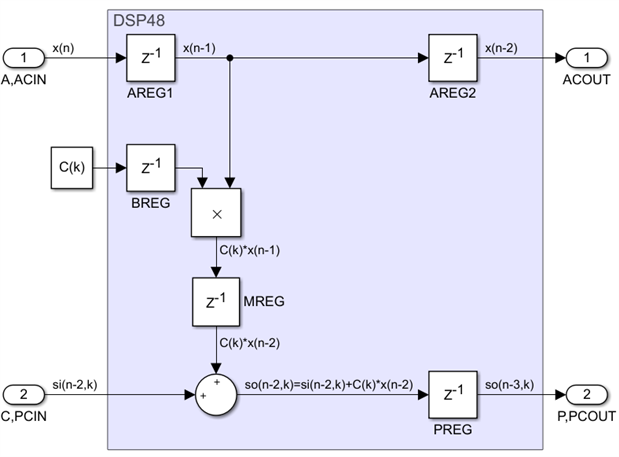
We can see now that everything inside this one-tap module will fit inside the DSP48 primitive, including the input delay chain and the post-adder cascade routing, and I have labeled both registers and ports using DSP48 primitive names. Chains of tens or even hundreds of taps can be created by instantiating this basic module in a generate loop and cascading them, with no impact on speed or on the rest of the FPGA design. We achieve this at the cost of increased latency, namely from 0 clocks to N+2 clocks.
And we are done, this is what we need to implement in hardware now. It does not matter what language we use, VHDL, Verilog or C/C++ for an HLS flow. It does not matter if we infer this from behavioral code or we instantiate DSP48 primitives. As long as we can achieve this implementation result, our design will be efficient, generic and scalable.
While this solution looks much more complicated than what we started with, the increase in performance is very significant and the speed will not drop as N increases. More importantly, we get all this for free. An N-tap FIR requires N multiplications every clock, so we have to use N DSP48 primitives anyway. But those primitives come with everything else we need, the post-adders and every delay in the design are part of the DSP48 primitives, we do not have to use any extra fabric resources. We will not even use any fabric routing, all the connections, except for the filter input and output also come for free with the DSP48s. There is dedicated routing for both the input delay line, called the A cascade and for the partial sums, the P cascade, which run vertically along every DSP48 column. These are independent from general fabric routing. There will be no routing conflicts between the DSP48 chain and the rest of the FPGA design, so not only is the maximum speed independent of N, it is also independent of the rest of the FPGA. It is not unrealistic to say that such an FIR will always be able to run at the maximum clock frequency permitted by the data sheet, no matter what the FIR filter order N is or even what the rest of the FPGA does. This systolic FIR architecture, properly using the available DSP48 features, is truly efficient, scalable and generic.
Wait, what about the third pipeline cut rule you may ask. We did not have to use it here because in every single case, all the nets crossing the cut line were going in the same direction. In general this is not the case and we will encounter examples like IIR filters and symmetric FIRs where we have nets crossing the pipeline cut line in both directions. The third rule says that if you add delays on the nets going one way, you have to remove delays on all nets going in the opposite direction. If you have those registers already in the design that’s OK, the design will use fewer registers but if you do not have those registers than you cannot make the cut. Removing registers can also make pipelining more difficult.
In the next post we will use the re-timing and pipeline cut rules once again to derive the transpose FIR architecture and then we will have an opportunity to apply the third pipeline cut rule when we start looking at pipelining symmetric FIRs.
Back to the top: The Art of FPGA Design Season 2
