


The Single Rate non-symmetric FIR, direct and transpose architectures
As I mentioned earlier, the single rate non-symmetric FIR filter has two possible implementations, the direct and the transpose forms. We will now apply again the retiming and pipeline cut methods to derive the transpose architecture from the direct one and prove that the two are equivalent.
We started from the mathematical equation of the FIR and we derived from it the direct form implementation, which is the first one in the diagram below. We will start pushing the input delay line registers through the multipliers in multiple steps, one for each FIR tap. The elements affected by the first step are marked in green, before and after the retiming. We repeat this operation for each tap until we reach the intermediate structure, where we have no more longitudinal delays, they are all located in the transversal branches:
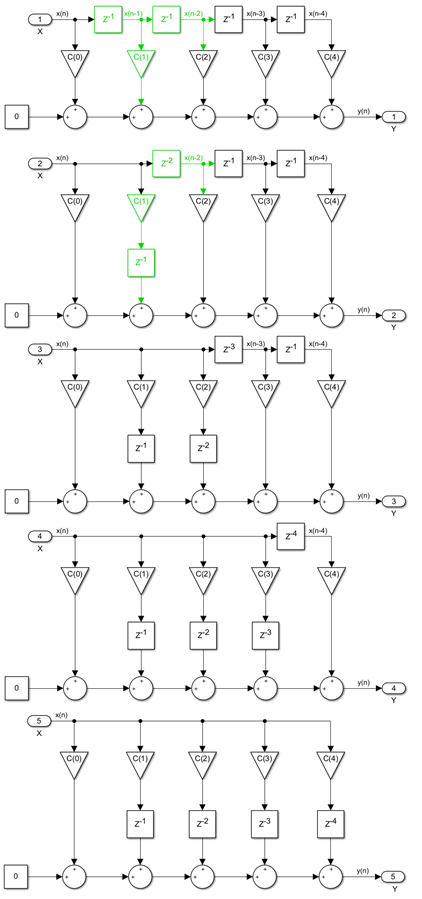
We can use now the associativity property of the addition and flip or transpose all the taps. The branch with the first coefficient is now last instead of being first. I also used the pipeline cut to insert 5 delays between the zero constant and the first adder. Since both the input and output ports are on the same side of the pipeline cut, there is no change in latency. Then we leave one of those five delays behind and push the other four through the first adder. Once again, the blocks affected by this retiming are marked in green. We repeat this operation for every tap, every time leaving one delay register behind:

The final architecture is called the transpose non-symmetric FIR. While it is clearly very different from the direct form we started with, the two are perfectly equivalent and they both implement the same mathematical equation. If I were to put one of these two implementations inside a black box, you could not tell which one I used just by looking at the filter inputs and outputs.
The first insight we can take from this exercise is that the relationship between mathematical algorithm and hardware implementation is not one to one, there could be many different ways of translating the math into physics. Instead of an input delay line, we now have delays inserted between the adders. We can add two delays for each multiplier using two longitudinal pipeline cuts and one extra register after the last adder and we would have a fully pipelined implementation. The latency of this transposed FIR would be 3 clocks and independent of the filter order N. If you remember from the previous post, the latency of the pipelined systolic direct FIR version was N+2 and it grows as the filter order grows. The transpose FIR architecture is clearly interesting and it should be the first choice if low latency is a design requirement. However, while this design is generic and we can build a filter of any order N by cascading N identical building blocks, it is not scalable. It might not be obvious, but the filter input has to reach all multipliers in a single clock. That connection translates into FPGA routing and as the filter size grows, its speed will get slower and slower. In practice there is a maximum filter size beyond which speed starts to drop. The actual value depends on the actual FPGA family and speed grade, as well as the rest of the design, since the input uses now local routing, but it is typically between 10 and 20 taps. If the filter order is less than that, the transpose architecture is definitely worth considering, and it is actually the correct choice if low latency is desired.
This of course begs the obvious question - can we have our cake and eat it too? Is it possible to build a generic, scalable and low latency FIR? Surprisingly, the answer is yes and the transpose FIR architecture is the answer. We just need to pipeline it but instead of making one transversal pipeline cut for every tap, we make one only every M taps where we chose M to be something between 10 and 20 for example. While the latency of the systolic, fully pipelined, direct FIR is N+2 clocks and the latency of the systolic, non-pipelined transpose FIR is 3 clocks and independent of N, this partially pipelined transpose version has a latency of ceil(N/M)+2 clocks. Here is an example for N=8 and M=4:

The original blocks from the non-pipeline transpose FIR we derived earlier are white but N is now 8 instead of 5. There are two longitudinal pipeline cuts, yellow and cyan and the registers added are colored accordingly. There are also N/M=2 green transversal pipeline cuts, three green pipeline registers have been added that way. We have added a lot of registers this way but it turns out that except for a single register that will have to be implemented in fabric, everything will use DSP48 registers that are already there - the cost of this pipelining in terms of hardware resources used is virtually nil. I have marked the eight DSP48s with purple boxes and labeled the registers with DSP48 internal register names. I kept M=4 for illustration purposes but in practice implementations with M values up to 20 could still run at maximum possible speed. The latency of this filter is 4 clocks, just one clock more than the smallest possible value, which is 3.
The latency does grow with N, but much slower than was the case for the systolic direct FIR implementation. If this is not good enough, it is possible to take advantage of the new DSP48 3-input post-adder feature introduced with the UltraScale FPGA family, meaning it is an option for UltraScale/UltraScale+ (DSP48E2) and Versal (DSP58) FPGAs but not the older 7-series (DSP48E1), and create a really scalable low latency FIR, one with a constant latency of 3 clocks no matter how large the FIR order N is.
In conclusion, we have found out so far that single rate non-symmetric FIR filters can be implemented in a systolic fashion using a basic building block, which can be cascaded to any length desired. These filters are generic and scalable, they use very few resources and the speed does not degrade as the filter gets larger. There are two different architectures, called direct and transpose, and their basic building blocks are shown below:
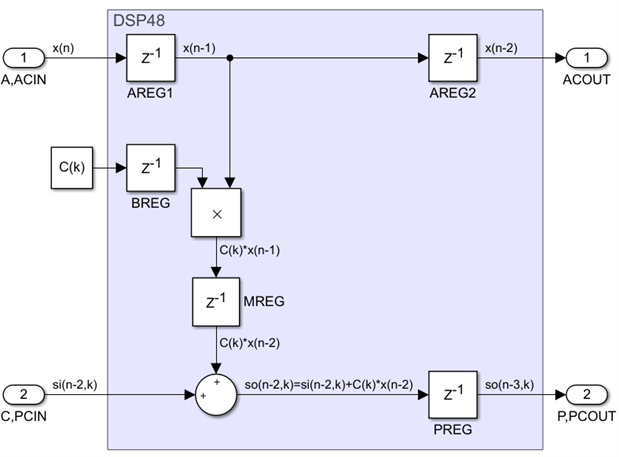

They have different properties and different uses. The systolic direct form is the simplest, it is fully scalable but its latency is proportional to the FIR filter order N. The systolic direct form has very little latency which does not depend on N but it is not scalable beyond a certain size. It is however possible to do a partial pipelining or use 3-input post-adders in the FPGA families that have them to make it fully scalable and maintain a very low latency at the same time.
So far we have considered only the simplest and most general FIR version, the single rate non-symmetric one. But there are many particular FIR architectures, and in the next posts we will start looking at these one by one and show how to implement each one efficiently. We will begin with the single rate symmetric FIRs first.
Back to the top: The Art of FPGA Design Season 2
